GPU与GPGPU泛淡
Posted 夕阳叹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPU与GPGPU泛淡相关的知识,希望对你有一定的参考价值。
GPU与GPGPU泛淡
GPU(Graphics Processing Unit),也即显卡,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上作图像运算工作的微处理器。它已经是个人PC和移动设备上不可或缺的芯片,有界面有显示的地方,一般就离不开它。高清电视、智能手机、个人电脑。
GPU的产生是为了解决图形渲染效率的问题,但随着技术进步,GPU越来越强大,尤其是shader出现之后(这个允许我们在GPU上编程),GPU能做的事越来越多,不再局限于图形领域,也就有人动手将其能力扩展到其他计算密集的领域,这就是GP(General Purpose)GPU。
考虑到当下,图形领域的技术人员对GPU已经是很熟悉了,其他那些关心GPU的,无非是向往GPU的强大并行运算能力,想利用它做通用计算的,因此,本文会特别提GPGPU。
架构与生态
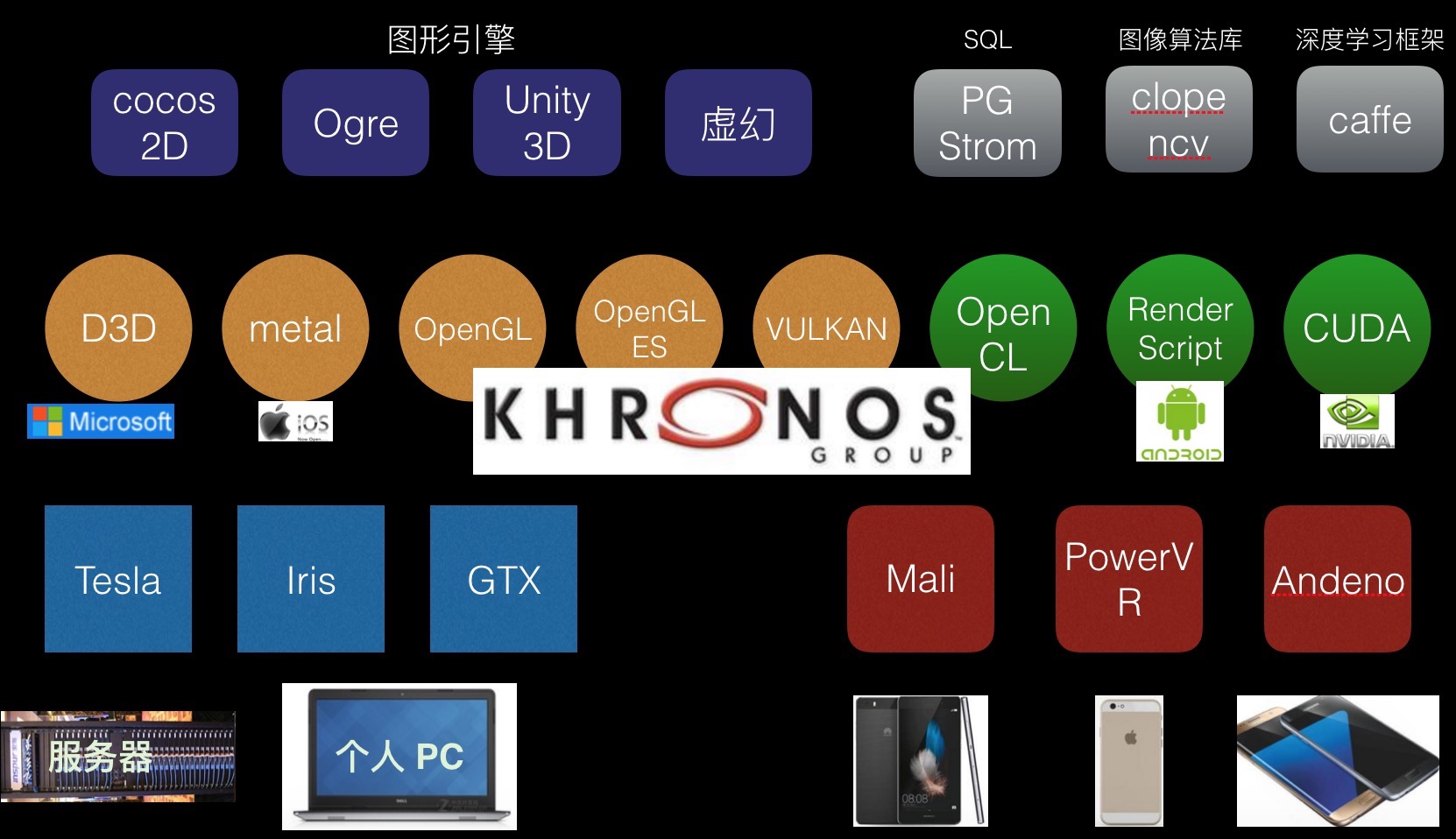
第一行为图形引擎/算法库,
第二行为图形标准
第三行为不同型号的GPU
图形标准
开发者直接调用驱动接口是很不方便且不安全的,为此,需要有一套给上游应用开发提供的API,开发者使用这组API,去触发GPU的功能,这一套API就是图形标准。
如图所示:
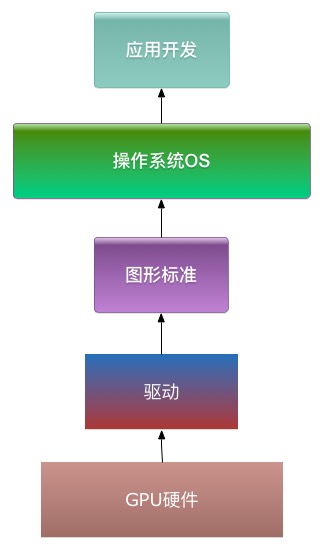
作为开发者,自然非常希望这套API是统一的,不过很不幸,由于历史原因、性能问题及永恒的利益之争,统一似乎是不可能的事情。还好,主流的标准就那么几个,而且编程原理基本上一样,代码封一层去适应下,一般也就可以了。
图形渲染标准
个人PC一般是Windows系统,主要使用Direct3D,一般也支持OpenGL。
服务器、mac等一般是类unix系统(Ubuntu、Redit、macOS),支持开放标准OpenGL。
智能手机、机顶盒等嵌入式设备一般是类unix系统(ios、android、阿里云等),支持开放标准OpenGLES(OpenGL标准作裁剪而得),不过苹果觉得OpenGL效率太低,不能充分发挥自家GPU的优势,就搞了一个metal。后面 AMD 也这么认为,搞了一个mantle,到了最后khronos组织也一致这么认为了,就推出了vulkan。
Direct3D只适用于Windows,metal只适用于ios,mantle只适用于AMD的GPU,OpenGL/OpenGL ES及新推出的vulkan是通用开放标准,它们由khronos组织维护,理论上适用于任何操作系统,但需要GPU厂商去支持。
最早的图形标准是联合组织维护的OpenGL,后面微软觉得这个组织效率太低,于是结合自己的系统弄了Direct3D,在后续的较量中渐渐取得了绝对优势(率先推出shader是竞争拐点)。OpenGL在PC端渐渐不行的时候,苹果的iphone及一系列Android机又在移动端拯救了它(开放的好处,移动端只能用OpenGL)。但OpenGL这套标准实在是有硬伤,人们虽然将就着用,并且不断升级改良,也实在到了需要进一步突破的时候,于是就有了 vulkan。
如这篇文章所述:
http://blog.csdn.net/mythma/article/details/50808817
vulkan在设计上无疑是先进的,一是废弃了OpenGL的线程上下文及状态机模式(这导致图形引擎在考虑多线程并发时的设计超痛苦,且很容易出Bug),二是废弃了shader前端、只支持一种叫SPIR-V的shader中间码(一方面防止奇葩低端gpu在编译shader时报语法错误,另一方面,可以对shader代码作一定的产权保护)。不过,引擎开发者、驱动开发者及系统维护者适应这一变更,需要一段时间。
通用计算标准
目前的通用计算标准主要是OpenCL,最新版到2.1,但人们用得最多的是NVIDIA的专属API:CUDA。
Google 一直在Android系统中强推 RenderScript,不在系统层面支持OpenCL,很大程度上限制了移动端的通用计算应用。
这篇文章分析 OpenCL和RenderScript 得比较好:
http://blog.csdn.net/zhuanshenweiliu/article/details/40746873
硬件与驱动
在个人PC、游戏主机及服务器市场,主要是NVIDIA和AMD两强争霸,传统的图形渲染上,不分伯仲;通用计算方面,由于NVIDIA先行了一步,推出CUDA,生态圈已成,拥有绝对优势;不妨看今年据说要爆发的VR(虚拟现实)上,两边的成绩如何。
嵌入式设备市场上,GPU品种要繁多一些,论第一还是首推iphone所采用的powerVR(Imagination公司所产),其次是高通的Adreno系列(如小米、三星S7),继而Arm的mali系列(海思自用图芯吃亏之后,改用mali系列,图形能力脱胎换骨【但还是相对弱势】,不过P6、D2给消费者留下的图形能力不行的阴影至今仍在)。其他份额较少的gpu就不罗列了。
谈到硬件,不妨提一下相应的驱动框架:
参考文章
http://blog.csdn.net/myarrow/article/details/17375483
(这一部分建议没有背景知识的先跳过)
一般来说,gpu的驱动框架类似下图:
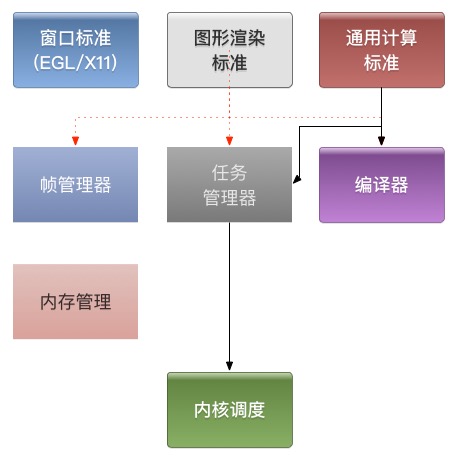
1、窗口标准的实现是与操作系统强相关的,它为图形渲染提供目标内存。一般来说,只要支持的标准不变,操作系统更换/升级,对驱动的代码影响就只限在窗口这一块。
2、编译器用于编译shader或kernel,编译kernel需要用llvm预编译,编译器会大一些。低端GPU的编译器特别容易出现各种语法不支持,让写shader的人痛苦万分。
3、通用计算的实现就是把kernel编译后转成任务扔给内核去跑,相对简单。
4、图形渲染的实现则需要考虑到一帧中可能有重复渲染/过度绘制的情况,为了这方面做优化,一帧中的任务有必要做一下组织,因此要有个帧管理器模块。
5、内存管理用于管理显存,但显存不一定是在GPU芯片上(独显和集显的区别)。
6、不管上层玩得多么风生水起,到了内核都是一个个的任务,内核模块执行、调度便是。
图形引擎/算法库
一般而言,应用开发者不会直接去调用图形标准API,而是使用图形引擎/算法库。原因如下:
1、图形标准API非常繁琐难用,需要习惯GPU编程的思想,有必要做适度封装,减轻上层应用的开发难度。
2、如上文所述,图形标准有多种,且不同硬件对同一标准的支持情况也不一定相同,有必要做一个中间层,专门去处理这些问题。
3、一些图形图像算法需要较强的专业知识,得用专业人才去编写。
图形引擎
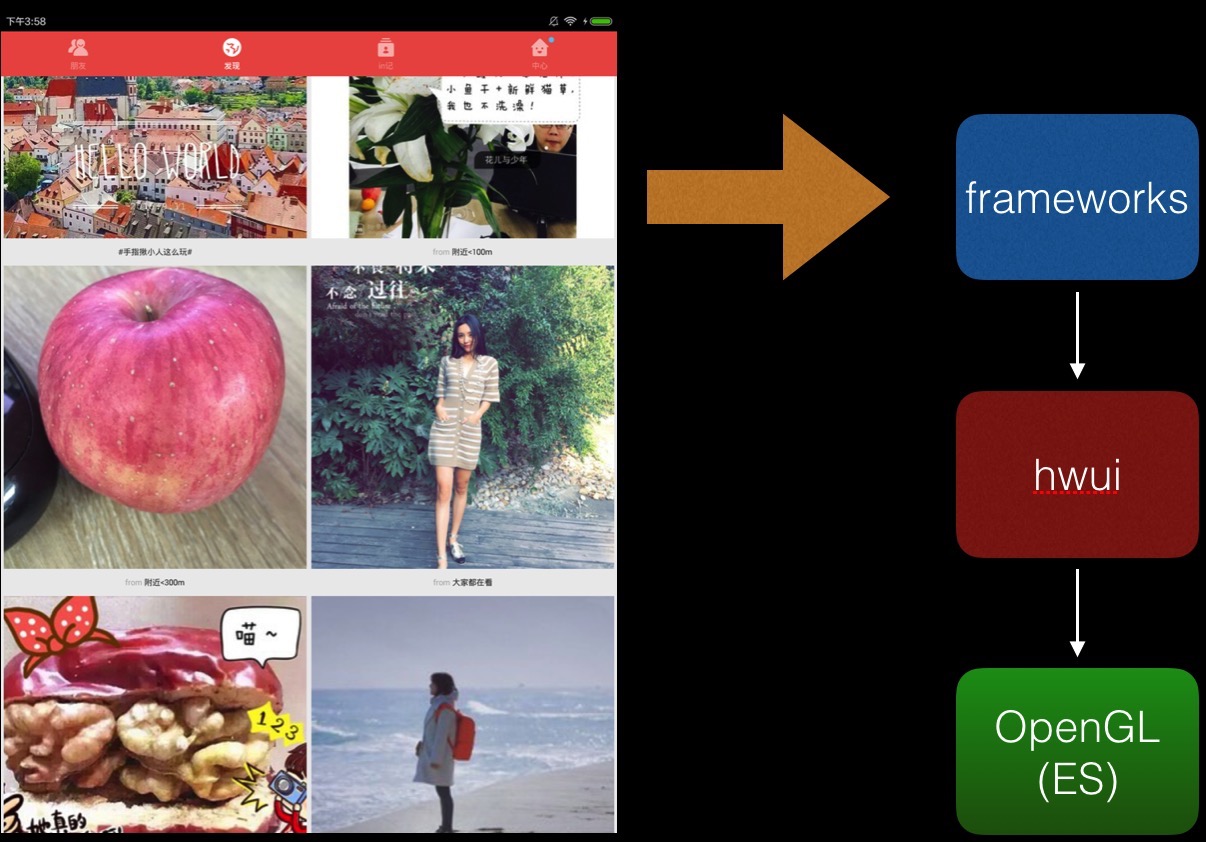
应用开发者开发界面时,主要是用操作系统提供的View框架。为支持这个框架,操作系统都会实现一套2D引擎,开发者间接使用了图形引擎。
如这个应用间接使用了Android的hwui引擎:
要求界面炫酷的应用,典型如游戏,会去用一些3D引擎。目前手游上主流的游戏引擎是 unity3D和cocos2D,unity3D免费但不开源,cocos2D是做了捕鱼达人游戏的公司公布并开源的。PC游戏方面,以收费商业引擎为主,且一般是基于D3D(这就是为什么linux、类linux系统下游戏那么少),典型如虚幻引擎,特效强大。ogre是主要用于PC的久负盛名的开源引擎,支持OpenGL,完美时空基于ogre做过游戏。
网易的天下HD用的unity3D(没记错的话。。。)
虚幻引擎做的某款游戏:

图形引擎多种多样,这里仅仅是列了很少一部分,毕竟是个大坑,只能简单提一下。
通用计算引擎/算法库
通用计算引擎所见的主要是 ArrayFire,主页:http://arrayfire.com/。它提供了一系列用OpenCL/Cuda加速的算法库,并提供方便的接口去开发GPU加速的算法。
caffe是工业上最常用的深度学习框架,支持多台装配NVIDIA的服务器同时进行深度学习。
opencv 是一个庞大的图像算法库,cl-opencv对其核心算法基于OpenCL作了加速。
PG-Storm 则据说是用 GPU加速的 postsql,具体没看过,SQL查询中的变长字符串处理是GPU优化的难点,以前看过的demo都回避了这一问题,不知道这个是否解决了。
GPU编程
抛开具体的硬件,标准,以及引擎来说,GPU本身代表着和CPU不一样的编程思想:CPU好比几个高智商精英,什么都能做且做得快;而GPU就是一大群低学历农民工,每个人可以做的有限,也不快,但人数优势决定其整体速度完爆精英们。
GPU编程,就像指挥一大群蚂蚁,有几个通用原则:
1、让蚂蚁们做的工作量尽可能相等,因为你要等所有蚂蚁都完成才能进行下一步。
2、不要在意每一只蚂蚁的工作细节,请关注你给蚂蚁准备的粮食。(GPU编程的主要工作是配置参数)
3、蚂蚁们所在的世界和你的世界有矩离,你要教导它们做事(提供shader或kernel),向它们喊话(触发执行API),并提供做事的资源(内存数据传到显存)。
图形渲染
管线
管线是GPU上做图形渲染编程最为重要的概念,GPU就像一个炒菜机,程序员要做的主要事情是给它配原料,至于翻滚、加热等工序,不在程序员的控制之内。
参考:
http://www.360doc.com/content/13/0107/18/9934052_258805453.shtml
简单的记法:
顶点——图元——光栅化——着色
形与色
图形渲染的基本思想就是先定形,再定色,
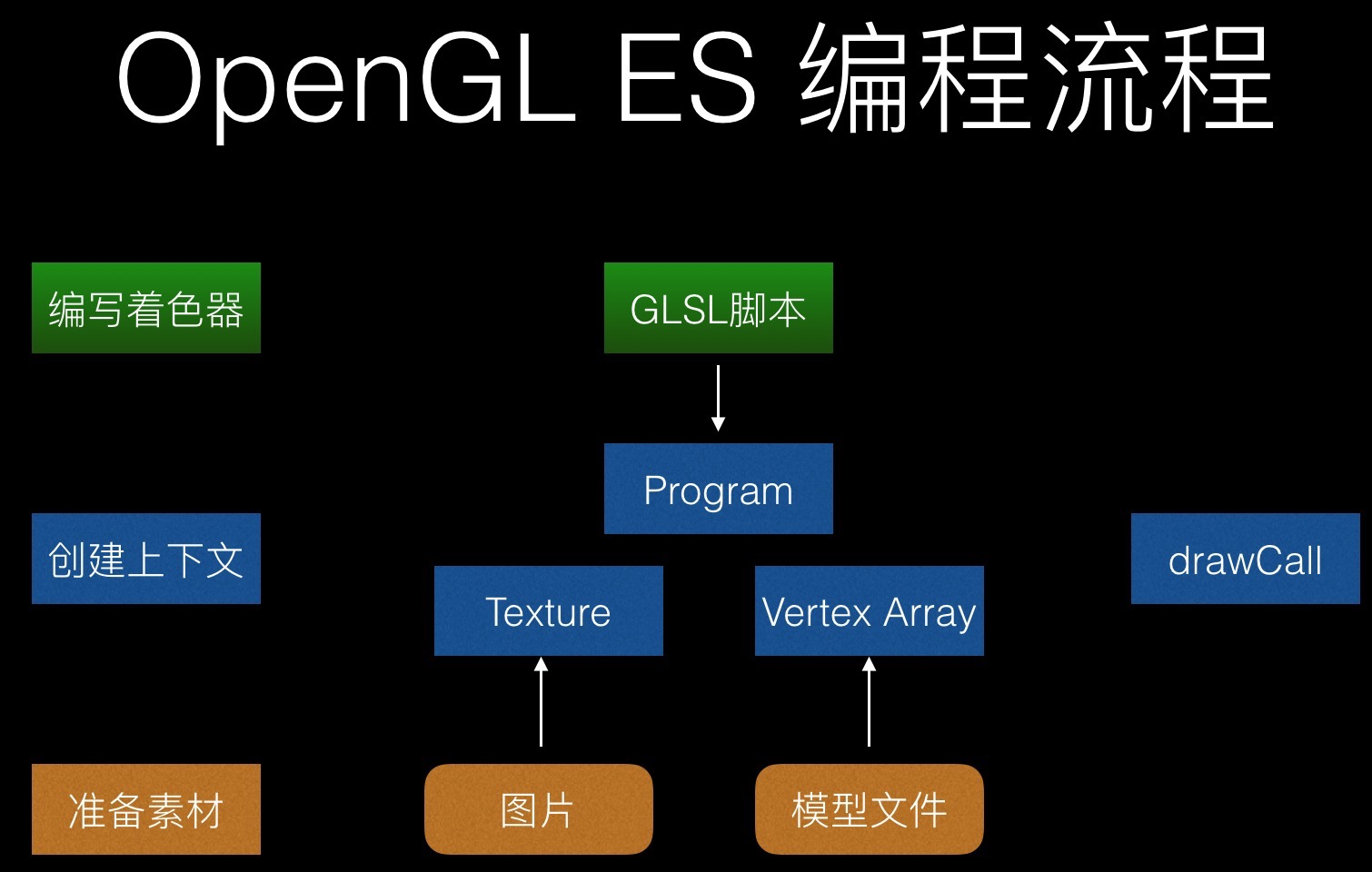
下图是OpenGL ES 编程流程:
通用计算
数据并行与批量化
使用GPU加速算法,务必做到批量化处理,只处理1条或1行数据,调用GPU接口的交互时间会远远超出计算时间。
减少交流
这里的交流,一方面指的是CPU与GPU之间的数据传输,另一方面指调触发运算的API。
GPGPU应用展望
移动端的通用计算
从事SOC开发的工作时,对此做了许多尝试均告失败。移动端的通用GPU计算实在是很难有进展的一件事情,首先,受限于可怜的GPU性能及弱爆了的内存传输带宽,GPU加速往往被多线程+neon完爆;其次,移动端作密集运算的场景着实有限,最需要运算的也就相机模块与图像编解码,但这么有限的场景厂商完全可以上DSP/ISP,GPU在这时并没太大优势。目前而言,在移动端做优化,主要还是运用OpenGL和neon。
然而随着普适计算、情景智能、图像识别的发展,移动端的通用计算将会变得越来越有意义,更快更准确的机器学习算法的使用,可以让手机更智能。
通用分布式异构计算框架
目前的分布式计算框架,通用型的如hadoop、spark、flink等都是只能利用CPU的(虽然也可以用GPU,但用起来很麻烦且兼容性不好)。
用上了 GPU 的,主要是特定设备上跑固定算法(Deep Learning),不具备通用性。以致于几乎Tesla就是DL的代表,
http://server.yesky.com/es/355/50639355.shtml
若有一个通用的分布式异构计算框架,可以大幅降低机器学习、图像处理、视频制作等计算密集业务在时间和机器上的消耗,其价值是非常大的。
此外,基于此可以设计分布式GPU数据库,大大提升查询的性能。
以上是关于GPU与GPGPU泛淡的主要内容,如果未能解决你的问题,请参考以下文章