某天女朋友抛出了下面一段以下类似代码的字符串问我其中的Xmx、Xms...等等等是什么意思,干嘛用的?我先是一惊,随后淡定,因为刚好这几个参数我还认识(没吃过猪肉,也见过猪跑啊)然后说这是配置jvm最大堆内存和最小堆内存的。然后她又问什么是jvm?这就尴尬了,这就聊不下去了,于是有了这篇随笔。
1 JAVA_OPTS="-server -Xmx1G -Xms1G -XX:PermSize=256M -XX:MaxPermSize=512M -XX:ParallelGCThreads=8
-XX:NewRatio=2 -XX:SurvivorRatio=8 -XX:TargetSurvivorRatio=70 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:+UseParNewGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC -Xloggc:log/gc.log "
一、什么是JVM?
JVM是Java Virtual Machine(Java虚拟机)的缩写,意思就是说我们要跑Java程序就必须要有Java环境,而这个环境就是Java虚拟机啦,就是我们常说的JVM了。再想想,要想一个Java程序可以跑起来,那必须得给这个程序分配内存啊、控制指令的执行这些一系列复杂的操作,而这些操作在Java的世界里就是由JVM来完成的。
接下来这张图就是Java虚拟机会在执行Java程序过程中把它所管理的内存划分为若干不同的数据区域。在运行时数据区主要分为5个不同数据区域分别是方法区、堆、虚拟机栈、本地方法栈、程序计数器。我们可以按照这些区域是否线程共享分成2类,蓝色区域表示由所有线程共享的,淡紫色区域表示非线程共享的,非线程共享意思就是说每个线程在这个区域只能访问自己的,不能访问别的线程的数据。
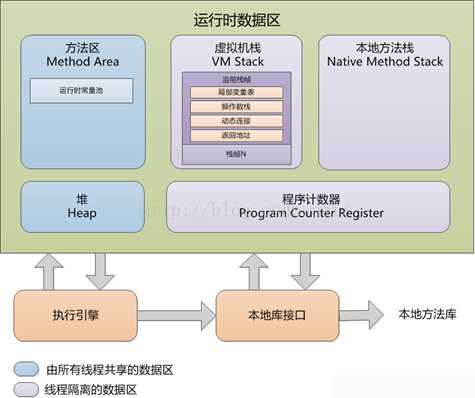
- 线程私有区域
程序计数器:它是当前线程所要执行指令(字节码)的指示器,我们每个线程的运行就是通过改变这个计数器的值来选取下一条要执行的指令的。
虚拟机栈和本地方法栈:大学学过C语言,写过Hello World的我们都可以理解函数的调用执行就是个进栈和出栈的过程,所不同的是在Java世界里我们称函数为方法,每个Java方法执行都会创建一个帧栈(一种数据结构)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。而虚拟机栈和本地方法栈的区别就是本地方法栈里面放的不是用Java语言写的,而是其他语言写的然后给Java来调用的方法。
- 线程共享区域
方法区:它用于存储一些被JVM加载的类信息、常量、静态变量等数据。需要补充一点是其实Java虚拟机是有很多种的,例如J9、JRockit、HotSpot等。在我们常用的虚拟机HotSpot虚拟机经常会把这个方法区叫做永久代。
堆:Java堆是虚拟机中所管理内存中最大的一块,几乎所有的对象实例需要分配的内存都是从这个区域拿的。
以上是我从是否线程共享这个维度把虚拟机数据区域做简单分类及说明,但是这样还漏了一个知识点:直接内存
- 直接内存
直接内存其实不是Java虚拟机所管理的内存区域,它是指我们物理机器的内存。但是这部分的内存我们Java程序也是可以使用的(比如我们可以通过Java堆中的DireByteBuffer对象作为这块内存进行操作),所有我们如果不小心忽略的直接内存,当虚拟机占用的内存加上我们使用的直接内存超过我们机器的限制时就会出现错误啦,就是OOM了(OutOfMemberError异常)
二、垃圾收集器与堆
上面我们将虚拟机数据区域的时候说过几乎所有的对象实例需要分配的内存都是从堆中分配的,而程序计数器、虚拟机栈、本地方法栈这些区域的内存分配和回收都是相当固定。那当堆中的对象不在使用的时候我们就要回收这些内存,让这些空闲的内存可以被新创建的对象使用,而回收这这些内存就是交给垃圾收集器做的。
在HotSpot虚拟机中提供了多种垃圾收集器,Serial收集器、ParNew收集器、Parallel Scavenge收集器、Parallel Old收集器、CMS收集器、G1收集器。也许你心里又有疑惑了。。为什么会有这么多种类的垃圾收集器?道理很简单,我们说要回收不再使用对象的内存,那怎么回收?不同的人肯定有不同的回收策略嘛,我们专业点叫法就是不同的垃圾回收算法,那不同的垃圾收集器其实就是对不同的回收算法的具体实现,它们各有利弊。
垃圾收集器说明白了,我们再说说堆,这里我要说明的是堆这个区域,我们又把它分成了2部分,我们称之为新生代和老年代。这其实是一种精细化管理堆内存的方式,因为堆中的对象有些是可以存活很久的,一直都会被使用,而有些对象呢被创建出来很快就要销毁了,我们把堆分成新生代和老年代后,可以根据不同对象的特点存放在不同的区域,那些“朝生夕死”的对象我们把他分配到新生代去,而长期活着的对象最终会去到老年代,这样一来当我们需要做垃圾回收的时候就可以针对不同的区域采用不同的垃圾回收算法,换句话就是使用不同的垃圾收集器去回收内存了,下图是堆的内存划分,其中Eden、Survivor1、Survivor2下面说到复制算法时会继续讨论。
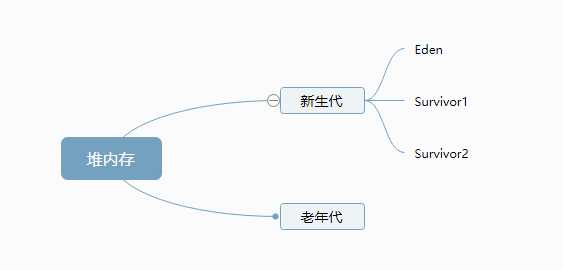
三、 垃圾回收算法
刚说了不同垃圾收集器就是对不同的垃圾回收算法的实现,那么常见垃圾回收算法又有哪些呢?它是如何演变的?
- 标记-清除算法
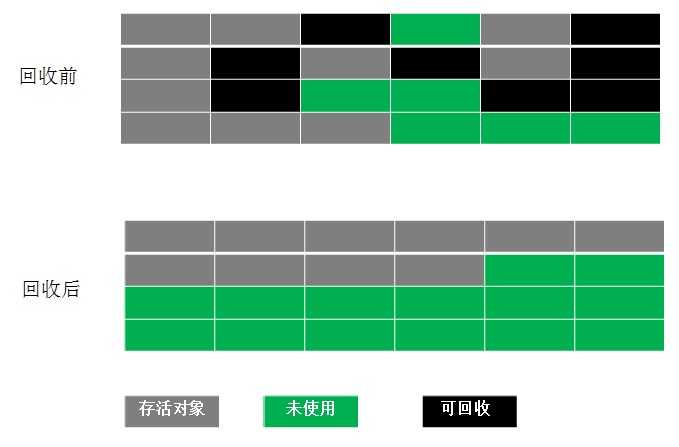
顾名思意标志-清除的算法简单,就是找出那些已死对象的内存区域,然后做标志,再清除!看看下图黑色块就是被标志已死对象占用的内存区域,清除后就变成绿色块了,表示该区域未被使用,可用来分配给新的对象。
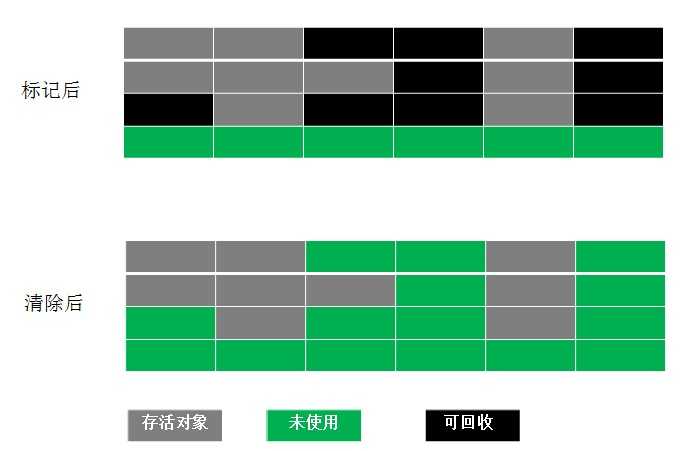
- 复制算法
对于标志-清除算法有明显的弊端,第一是效率不高、第二是标记-清除后会产生大量不连续的内存碎片。我们看看复制算法如何解决这些问题的。复制算法首先把堆分成对等上下两部分,如下图所示。当需要回收内存时直接把活着的对象复制到下部分,然后对上部分内存直接清理掉。可见这个效率是否要比标志-清除算法高效,并且清理后的内存分布是连续的。
我们又发现复制算法的弊端也很明显,很典型的是用空间换效率和避免了内存碎片,我们把内存缩少了为原来的一半了。但是还记得上面我说的新生代吗?现在的商业虚拟机都是采用这种算法来回收新生代的,因为新生代中的对象98%是“朝生夕死”的,所以我们可以把新生代又划分为一块较大的Eden空间和两块较小Survivor空间。每次分配新对象到新生代的时候,我们把它分配到Eden空间和一块Survivor1空间中,当要垃圾回收时,采用复制算法,把活着的对象复制到另外一个Survivor2空间中,然后直接对Eden和Survivor1内存清理掉,HotSpot虚拟机默认的Eden和Survivor大小比例是8:1,也就是在新生代中每次只有10%的内存被浪费掉而已,但换来了效率和内存利用率的提高。
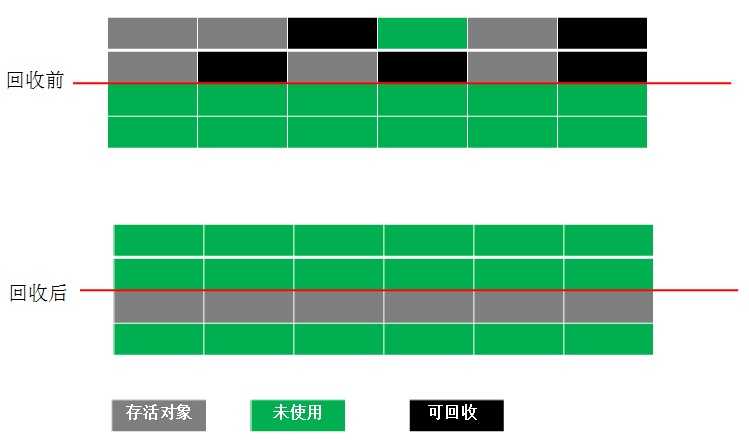
- 标记-整理算法
由于复制算法存在牺牲内存换取效率和内存连续的缺点,仅适用于在新生代这种对象存活率较低区域,而且我们没有办法保证在新生代每次回收都只有不多于10%对象存活,当Suivivor空间不够时,需要依赖其他内存(这里指用老年代分配担保)。由于老年代对象存活率比较高故不采用复制算法,而是采用标志-整理算法。标志-整理算法过程与标志-清除算法一样,只是后续步骤不是直接对回收内存进行清理,而是让存活对象向一边移动,保持内存分布的连续.
四、回到正题
写了这么多现在我觉得可以解答清楚一开始女朋友问的问题了,其实就是一些常用的jvm参数,具体一些概念可以参考随笔的一些内容去理解。
1 -server JVM Server模式与client模式启动,最主要的差别在于:-Server模式启动时,速度较慢,但是一旦运行起来后,性能会比Clien模式好
2 -Xmx1G 分配堆的最大内存
3 -Xms1G 分配堆的最小内存
4 -XX:PermSize=256M 分配永久代内存
5 -XX:MaxPermSize=512M 分配永久代最大内存
6 -XX:+UseParNewGC 新生代使用ParNew垃圾收集器
7 -XX:ParallelGCThreads=8 限制垃圾收集线程
8 -XX:NewRatio=2 设置堆中年轻代:老年代=1:2比例
9 -XX:SurvivorRatio=8 设置年轻代中eden:survivor = 8:1比例
10 -XX:TargetSurvivorRatio=70
11 -XX:+UseConcMarkSweepGC 老年代使用CMS垃圾收集器
12 -XX:CMSFullGCsBeforeCompaction=5 设置CMS垃圾收集器执行多少次不压缩的Full GC后,跟住来一次压缩整理(CMS垃圾收集器采用标志-整理算法,
通过该参数指定不压缩整理能减少GC时间)
13 -XX:+PrintClassHistogram 使用ctrl-break快捷键输出统计状态,相当于jmap-histo的功能
14 -XX:+PrintGCDetails 打印GC详细信息
15 -XX:+PrintGCTimeStamps 打印GC停顿耗时
16 -XX:+PrintHeapAtGC 打印GC时堆使用情况
17 -Xloggc:log/gc.log 设置GC日志保存文件
18 -XX:+HeapDumpOnOutOfMemoryError 发生内存溢出生成堆转储快照
19 -XX:HeapDumpPath=/data/logs/dump.log设置堆转储快照保存文件
五、结束语
这篇随笔只是简单介绍了JVM运行的数据区域、堆、垃圾收集器以及垃圾回收算法,在此我要特别说明的是为了能让非开发人员也能对Java虚拟机有个了解。所以在很多细节方面都没有进行讲解,例如各个垃圾收集器特点、内存分配和回收策略、在讲垃圾收集算法也是结合着分代收集算法的思路写的,而当我们使用G1收集器时,Java堆的内存布局和其它收集器是有很大区别的,自己对Java虚拟机的理解也是停留在一个基础水平,还需日后多有机会去实践方能得真知。
六、参考资料
参考书籍:深入理解Java虚拟机 第二版 周志明 著
随笔图片来自 https://www.cnblogs.com/cielosun/p/6674431.html
https://blog.csdn.net/u010814766/article/details/46785425