软件开发规范及常用模块一
Posted 我`你的唯一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软件开发规范及常用模块一相关的知识,希望对你有一定的参考价值。
一、软件开发规范
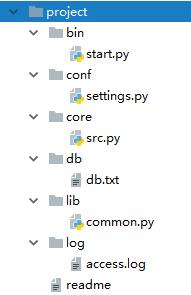
ATM #总文件夹
bin:用来放程序执行文件;start.py
conf:配置文件
log:日志文件
lib:放模块和包
db:数据文件
core:放程序的核心逻辑,里面src.py
readme #用来保存详细的每个文件夹的介绍,及作用
以上并未非规定,而是看个人理解不同自行定制。但一定要清晰明了。
二、序列化
前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,
但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
x="[null,true,false,1]"
print(eval(x)) #报错,无法解析null类型,而json就可以
print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化
序列化的主要目的:
1:持久保存状态
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一
种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。反过来,把变量内容从序列化的
对象重新读到内存里称之为反序列化,即unpickling。
1. json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,
因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。
JSON表示的对象就是标准的javascript语言的对象,JSON和Python内置的数据类型对应如下:


2. pickle
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python 。因此使用较少,不过它可以支持python内
所有的数据类型。
三、logging模块
logging模块的四种对象:
1 logger:负责产生日志
2 filter:过滤日志(不常用)
3 handler:控制日志打印到文件or终端
4 formatter:控制日志的格式
四种对象具体使用方式(了解即可) :
logger:负责产生日志
logger1=logging.getLogger(\'xxx\')
filter:过滤日志(不常用)
handler:控制日志打印到文件or终端
fh1=logging.FileHandler(filename=\'a1.log\',encoding=\'utf-8\')
fh2=logging.FileHandler(filename=\'a2.log\',encoding=\'utf-8\')
sh=logging.StreamHandler()
formatter:控制日志的格式
formatter1=logging.Formatter(
fmt=\'%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s\',
datefmt=\'%Y-%m-%d %H:%M:%S %p\',
)
formatter2=logging.Formatter(fmt=\'%(asctime)s - %(message)s\',)
为logger1对象绑定handler
logger1.addHandler(fh1)
logger1.addHandler(fh2)
logger1.addHandler(sh)
为handler对象绑定日志格式
fh1.setFormatter(formatter1)
fh2.setFormatter(formatter1)
sh.setFormatter(formatter2)
日志级别: 两层关卡,必须都通过,日志才能正常记录
logger1.setLevel(10)
fh1.setLevel(10)
fh2.setLevel(10)
sh.setLevel(10)
调用logger1对象下的方法,产生日志,然后交给不同的handler,控制日志记录到不同的地方
logger1.debug(\'调试信息\')
日常开发不需要自己写日志模块,通常的做法是拿别人写好的去使用,只需了解使用方法即可。
四、OS模块
优先掌握
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素(r\'C:\\a\\b\\c\\d.txt\'))
os.path.basename(path) 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。(r\'C:\\a\\b\\c\\d.txt\'))
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False。只管路径是否存在,不区分文件还是文件夹
print(os.path.exists(r\'D:\\code\\SH_fullstack_s1\\day15\\下午\\json.py\'))
print(os.path.exists(r\'D:\\code\\SH_fullstack_s1\\day15\'))
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False。
print(os.path.isfile(r\'D:\\code\\SH_fullstack_s1\\day15\\下午\'))
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
了解即可:
os.path.abspath(path) 返回path规范化的绝对路径
file_path=r\'a\\b\\c\\d.txt\'
print(os.path.abspath(file_path))
os.path.split(path) 将path分割成目录和文件名二元组返回
res=os.path.split(r\'C:\\a\\b\\c\\d.txt\')
print(res[-1])
print(res[0])
os.path.isabs(path) 如果path是绝对路径,返回True
print(os.path.isabs(r\'b/c/d.txt\'))
os.path.normcase 在Windows上,文件系统上, 把路径转换为小写字母,正斜杠转换为反斜杠。
print(os.path.normcase(\'c:/windows\\\\system32\\\\\') )
以上是关于软件开发规范及常用模块一的主要内容,如果未能解决你的问题,请参考以下文章