分布式网络爬虫的基本实现简述
Posted 低调才是王道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式网络爬虫的基本实现简述相关的知识,希望对你有一定的参考价值。
一、前言
前一段时间,小小的写了一个爬虫,是关于电商网站的。今天,把它分享出来,供大家参考,如有不足之处,请见谅!(抱拳)
二、准备工作
我们实现的这个爬虫是Java编写的。所用到的框架或者技术如下:
Redis:分布式的Key-Value数据库,用来作存储临时的页面URL的仓库。
HttpClient:Apache旗下的一款软件,用来下载页面。
htmlCleaner&xPath:网页分析软件,解析出相关的需要的信息。
mysql数据库:用于存储爬取过来的商品的详细信息。
ZooKeeper:分布式协调工具,用于后期监控各个爬虫的运行状态。
三、业务需求
抓取某电商商品详细信息,需要的相关字段为:商品ID、商品名称、商品价格、商品详细信息。
四、整体架构布局
首先是我们的核心部分——爬虫程序。爬虫的过程为:从Redis数据仓库中取出URL,利用HttpClient进行下载,下载后的页面内容,我们使用HtmlCleaner和xPath进行页面解析,这时,我们解析的页面可能是商品的列表页面,也有可能是商品的详细页面。如果是商品列表页面,则需要解析出页面中的商品详细页面的URL,并放入Redis数据仓库,进行后期解析;如果是商品的详细页面,则存入我们的MySQL数据。具体的架构图如下:
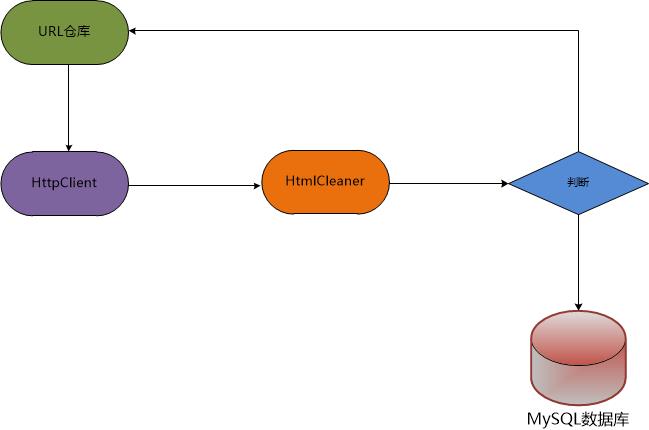
当核心程序爬虫编写完后,为了加快页面抓取效率,我们需要对爬虫进行改进:一是对爬虫程序进行多线程改造;二是将爬虫部署到多台服务器,进一步加快爬虫的抓取效率。在实际生产环境中,由于刀片服务器的稳定性不太好,所以可能导致一些问题,例如:爬虫进程挂掉,这些问题有可能是经常出现的,所以我们需要对其进行监控,一旦发现爬虫进程挂了,立即启动脚本对爬虫进程进行重新启动,保证我们整个爬虫核心的持续性作业。这是就用到了我们的分布式协调服务ZooKeeper。我们可以另外写一个监控进程的程序用来实时监控爬虫的运行情况,原理是:爬虫在启动时,在ZooKeeper服务中注册一个自己的临时目录,监控程序利用ZooKeeper监控爬虫所注册的临时目录,利用ZooKeeper的性质——如果注册临时目录的程序挂掉后,这个临时目录过一会儿也会消失,利用这个性质,我们的监控程序监控爬虫所注册的临时目录,一旦发现临时目录消失,则说明改服务器上的爬虫进程已挂,于是我们需要启动脚本重新启动爬虫进程。随后我们将抓取得到的商品详细信息存储到我们的分布式MySQL数据库中。以下是整个爬虫项目的架构图:
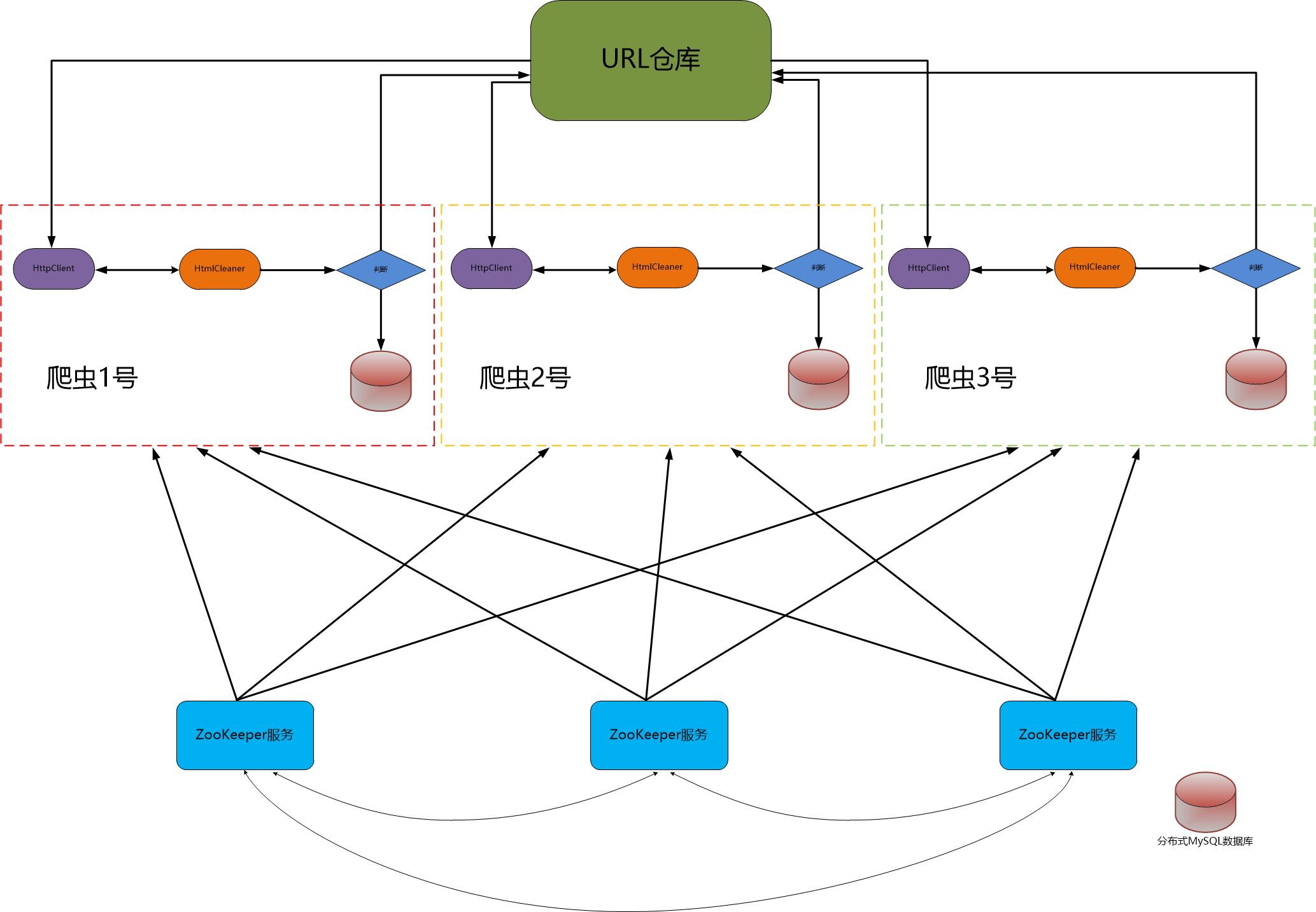
接下来,我们将重点分析爬虫架构中的各个部分。
五、Redis数据库——临时存储待抓取的URL。
Redis数据库是一个基于内存的Key-Value非关系型数据库。由于其读写速度极快,收到了人们的热捧(每秒10W左右的读写速度)。选用Redis数据库作临时数据存储正是基于此。为了使我们的爬虫优先抓取商品列表页面,我们在Redis中定义了两个队列(利用Redis的list的lpop和rpush模拟),分别是高优先级队列和低优先级队列,我们再高优先级队列中存储了商品列表页面,在低优先级队列存储了商品详细页面。这样我们就可以保证爬虫再进行抓取数据的时候,优先从高优先级队列取数据,从而使得爬虫优先抓取商品列表页面。为了很好地利用Redis数据库,我们编写了一个对于Redis的操作工具类。
package cn.mrchor.spider.utils; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class JedisUtils { public static String highKey = "jd_high_key"; public static String lowKey = "jd_low_key"; private JedisPool jedisPool = null; /** * 构造函数初始化jedis数据库连接池 */ public JedisUtils() { JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); jedisPoolConfig.setMaxIdle(10); jedisPoolConfig.setMaxTotal(100); jedisPoolConfig.setMaxWaitMillis(10000); jedisPoolConfig.setTestOnBorrow(true); jedisPool = new JedisPool("192.168.52.128", 6379); } /** * 获取jedis对象操作jedis数据库 * @return */ public Jedis getJedis() { return this.jedisPool.getResource(); } /** * 往list添加数据 */ public void addUrl(String key, String url) { Jedis jedis = jedisPool.getResource(); jedis.lpush(key, url); jedisPool.returnResourceObject(jedis); } /** * 从list中取数据 */ public String getUrl(String key) { Jedis jedis = jedisPool.getResource(); String url = jedis.rpop(key); jedisPool.returnResourceObject(jedis); return url; } }
六、HttpClient——使用IP代理抓取数据
为防止爬虫在频繁访问电商页面的行为被对方程序发现,爬虫程序一般在进行抓取数据的时候都是利用代理IP来抓取,以减少爬虫被电商发现的概率。我们可以使用一些网上的免费IP代理,如西刺代理,也可以花钱买一些IP进行代理下载电商页面。在使用代理进行页面下载时,可能出现连接超时,但这有可能是网络波动导致,也可能是代理IP失效。为了防止出现误判,我们在此做了三次尝试连接的机制代码,如果三次尝试失败,则认为这个IP失效。
七、HtmlCleaner&xPath——对下载过来的页面进行解析
解析页面是比较繁琐的任务,我们首先要确定需要解析的对象,然后再利用浏览器提供的xPath工具,copy xpath,然后再根据这个xpath解析出需要的东西。下图是我们解析商品价格用到的xpath(值为:/html/body/div[5]/div/div[2]/div[3]/div/div[1]/div[2]/span/span[2]),具体的解析代码附在图后:
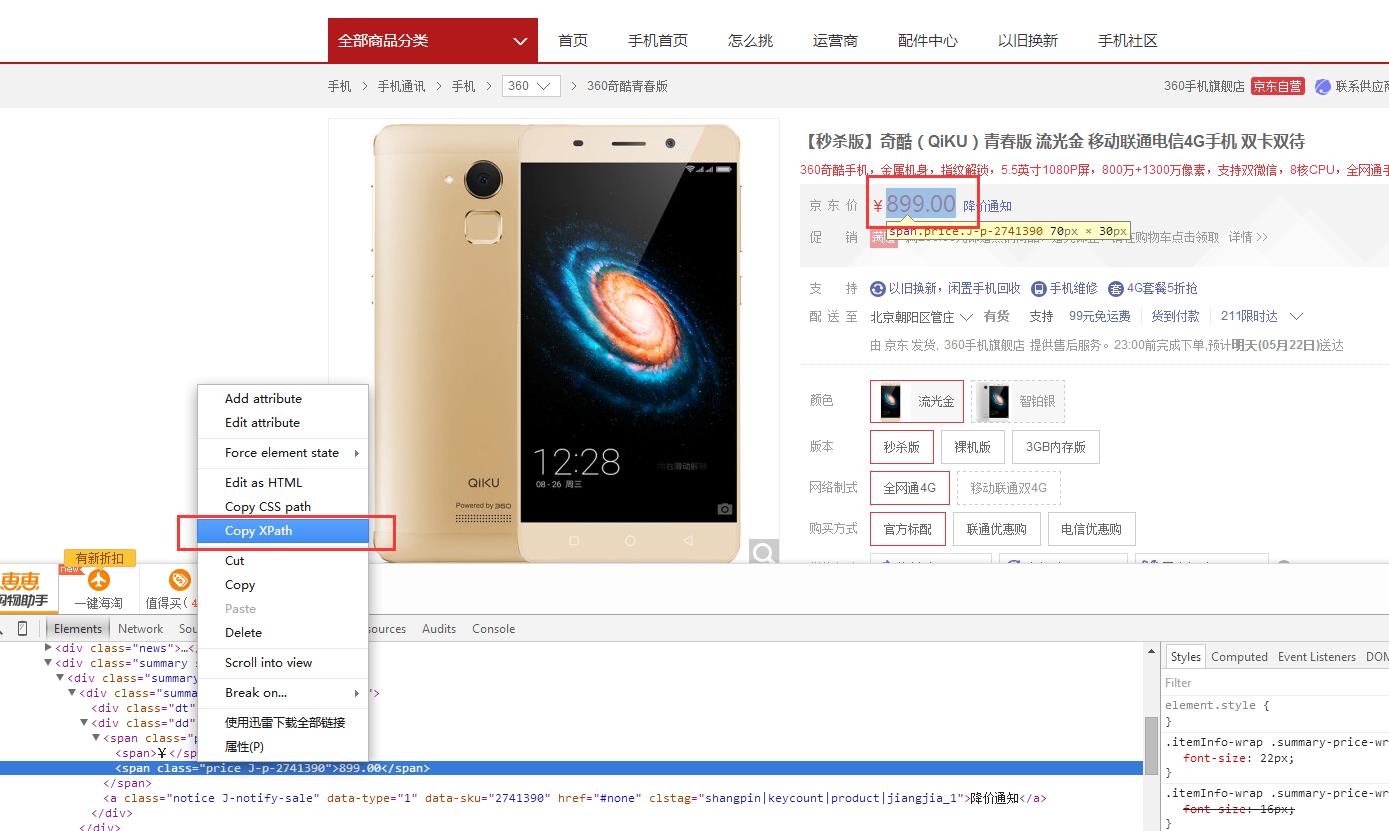
package cn.mrchor.spider.process; import org.htmlcleaner.HtmlCleaner; import org.htmlcleaner.TagNode; import org.htmlcleaner.XPatherException; import org.json.JSONArray; import org.json.JSONObject; import cn.mrchor.spider.domain.Page; import cn.mrchor.spider.download.HttpClientDownloadModeImpl; import cn.mrchor.spider.utils.HtmlUtils; import cn.mrchor.spider.utils.PageUtils; public class HttpCleanerProcessModeImpl implements ProcessMode { @Override public void process(Page page) { // 创建htmlcleaner对象 HtmlCleaner htmlCleaner = new HtmlCleaner(); // 使用htmlcleaner对象操作页面内容content,得到tagNode对象 TagNode tagNode = htmlCleaner.clean(page.getContent()); if (page.getUrl().startsWith("http://list.jd.com/list.html")) { // 商品列表页面解析 try { // 解析商品列表页面的url //*[@id="plist"]/ul/li[1]/div/div[4]/a Object[] goodsList = tagNode.evaluateXPath("//*[@id=\\"plist\\"]/ul/li/div/div[4]/a"); for (Object object : goodsList) { TagNode goodsUrl = (TagNode) object; System.err.println("http:" + goodsUrl.getAttributeByName("href")); page.addUrl("http:" + goodsUrl.getAttributeByName("href")); } // 解析商品列表页面中下一页的url Object[] nextPage = tagNode.evaluateXPath("//*[@id=\\"J_topPage\\"]/a[2]"); for (Object object : nextPage) { TagNode nextUrl = (TagNode) object; if (!nextUrl.getAttributeByName("href").contains("javascript:;")) { page.addUrl("http://list.jd.com" + nextUrl.getAttributeByName("href")); // System.err.println("http://list.jd.com" + // nextUrl.getAttributeByName("href")); } } } catch (XPatherException e) { e.printStackTrace(); } } else if (page.getUrl().startsWith("http://item.jd.com/")) { // 商品详细信息的页面解析 GoodsInfoProcess.goodsInfoProcess(tagNode, page); } } }
八、MySQL数据库——存储商品详细信息
在操作MySQL数据库这一块,我们也是写了一个数据库操作工具类,使用了Apache数据库连接池DBCP,这个算是比较简单的,配置了DBCP的配置文件后就可以很好地使用了:
package cn.mrchor.spider.utils; import java.sql.Connection; import java.sql.SQLException; import com.mchange.v2.c3p0.ComboPooledDataSource; public class MySqlConnectionTool { public static Connection getConnection(String database) { ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource(database); Connection connection = null; try { connection = comboPooledDataSource.getConnection(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return connection; } public static Connection getConnection() { ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource(); Connection connection = null; try { connection = comboPooledDataSource.getConnection(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return connection; } }
九、ZooKeeper服务——监控爬虫集群进程的运行情况
以上是关于分布式网络爬虫的基本实现简述的主要内容,如果未能解决你的问题,请参考以下文章