HBase底层存储原理
Posted 晴天彩虹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase底层存储原理相关的知识,希望对你有一定的参考价值。
HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已!
首先HBase不同于一般的关系数据库,
- 它是一个适合于非结构化数据存储的数据库.
- 另一个不同的是HBase基于列的而不是基于行的模式.
什么是BigTable:
- Bigtable是一个疏松的分布式的持久的多维排序的map,
- 这个map被行键,列键,和时间戳索引.
- 每一个值都是连续的byte数组.
(A Bigtable is a sparse, distributed, persistent multidimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.)
- HBase使用和Bigtable非常相同的数据模型.
- 用户存储数据行在一个表里.一个数据行拥有一个可选择的键和任意数量的列.
- 表是疏松的存储的,因此 用户可以给行定义各种不同的列.
(HBase uses a data model very similar to that of Bigtable. Users store data rows in labelled tables. A data row has a sortable key and an arbitrary number of columns. The table is stored sparsely, so that rows in the same table can have crazily-varying columns, if the user likes.)
一、架构思路
Hbase是基于Hadoop的项目,所以一般情况下我们使用的直接就是HDFS文件系统,这里我们不深谈HDFS如何构造其分布式的文件系统,
- 只需要知道虽然Hbase中有多个RegionServer的概念,并不意味着数据是持久化在RegionServer上的,
- 事实上,RegionServer是 调度者,管理Regions,但是数据是持久化在HDFS上的。
明确这一点,在后面的讨论中,我们直接把文件系统抽象为HDFS,不再深究。
Hbase是一个分布式的数据库,
- 使用Zookeeper来管理集群。
- 在架构层面上分为Master(Zookeeper中的leader)和多个RegionServer,
基本架构如图:

在Hbase的概念中,
- RegionServer对应于集群中的一个节点,而一个RegionServer负责管理多个Region。
- 一个Region代 表一张表的一部分数据,所以在Hbase中的一张表可能会需要很多个Region来存储其数据,
- 但是每个Region中的数据并不是杂乱无章 的,Hbase在管理Region的时候会给每个Region定义一个Rowkey的范围,落在特定范围内的数据将交给特定的Region,从而将负载分 摊到多个节点上,充分利用分布式的优点。
- 另外,Hbase会自动的调节Region处在的位置,如果一个RegionServer变得Hot(大量的请求 落在这个Server管理的Region上),Hbase就会把Region移动到相对空闲的节点,依次保证集群环境被充分利用
二、存储模型
有了架构层面的保证,接下来的事情就只是关注于数据的具体存储了。这里就是每个Region所承担的工作了。
- 我们知道一个Region代表的是一张 Hbase表中特定Rowkey范围内的数据,
- 而Hbase是面向列存储的数据库,所以在一个Region中,有多个文件来存储这些列。
- Hbase中数据 列是由列簇来组织的,所以每一个列簇都会有对应的一个数据结构,
- Hbase将列簇的存储数据结构抽象为Store,一个Store代表一个列簇。

所以在这里也可以看出为什么在我们查询的时候要尽量减少不需要的列,
而经常一起查询的列要组织到一个列簇里:
因为要需要查询的列簇越多,意味着要扫描越多的Store文件,这就需要越多的时间。
我们来深入Store中存储数据的方式。
Hbase的实现是用了一种LSM 树的结构!
LSM树是由B+树改进
首先来简单的看看B+树:
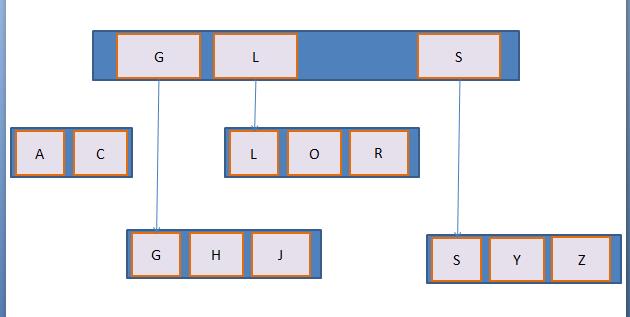
这是一颗简单的B+树,含义不言而喻,这里不多分析,但是这种数据结构并不适合Hbase中的应用场景。
这样的数据结构在内存中效率是很高的,但是 Hbase中数据是存储在文件中的,如果按照这样的结构来存储,意味着我们每一次插入数据都要由一级索引找到文件再在文件中间作操作来保证数据的有序性, 这无疑是效率低下的。
所以Hbase采用的是LSM树的结构,这种结构的关键是,
- 每一次的插入操作都会先进入MemStore(内存缓冲区),
- 当 MemStore达到上限的时候,Hbase会将内存中的数据输出为有序的StoreFile文件数据(根据Rowkey、版本、列名排序,这里已经和列 簇无关了因为Store里都属于同一个列簇)。
- 这样会在Store中形成很多个小的StoreFile,当这些小的File数量达到一个阀值的时 候,Hbase会用一个线程来把这些小File合并成一个大的File。
这样,Hbase就把效率低下的文件中的插入、移动操作转变成了单纯的文件输出、 合并操作。
由上可知,在Hbase底层的Store数据结构中,
- 每个StoreFile内的数据是有序的,
- 但是StoreFile之间不一定是有序的,
- Store只 需要管理StoreFile的索引就可以了。
这里也可以看出为什么指定版本和Rowkey可以加强查询的效率,因为指定版本和Rowkey的查询可以利用 StoreFile的索引跳过一些肯定不包含目标数据的数据。

HBase vs Cassandra
| HBase | Cassandra | |
|---|---|---|
| 语言 | Java | Java |
| 出发点 | BigTable | BigTable and Dynamo |
| License | Apache | Apache |
| Protocol | HTTP/REST (also Thrift) | Custom, binary (Thrift) |
| 数据分布 | 表划分为多个region存在不同region server上 | 改进的一致性哈希(虚拟节点) |
| 存储目标 | 大文件 | 小文件 |
| 一致性 | 强一致性 | 最终一致性,Quorum NRW策略 |
| 架构 | master/slave | p2p |
| 高可用性 | NameNode是HDFS的单点故障点 | P2P和去中心化设计,不会出现单点故障 |
| 伸缩性 | Region Server扩容,通过将自身发布到Master,Master均匀分布Region | 扩容需在Hash Ring上多个节点间调整数据分布 |
| 读写性能 | 数据读写定位可能要通过最多6次的网络RPC,性能较低。 | 数据读写定位非常快 |
| 数据冲突处理 | 乐观并发控制(optimistic concurrency control) | 向量时钟 |
| 临时故障处理 | Region Server宕机,重做HLog | 数据回传机制:某节点宕机,hash到该节点的新数据自动路由到下一节点做 hinted handoff,源节点恢复后,推送回源节点。 |
| 永久故障恢复 | Region Server恢复,master重新给其分配region | Merkle 哈希树,通过Gossip协议同步Merkle Tree,维护集群节点间的数据一致性 |
| 成员通信及错误检测 | Zookeeper | 基于Gossip |
| CAP | 1,强一致性,0数据丢失。2,可用性低。3,扩容方便。 | 1,弱一致性,数据可能丢失。2,可用性高。3,扩容方便。 |
以上是关于HBase底层存储原理的主要内容,如果未能解决你的问题,请参考以下文章