一、Kafka回顾
1、AMQP协议
消息队列中消息交互规范,多数分布式消息中间件基于该协议进行消息传输
2、Broker
对于kafka,将生产者发送的消息,动态的添加到磁盘,一个Broker等同于一个kafka应用实例,用于存放消息队列
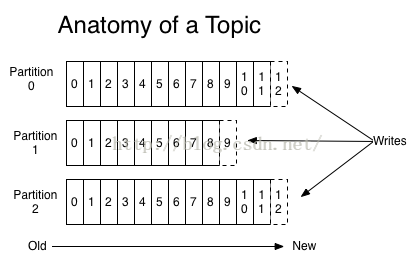
3、主题:分区:消息
一个分区(Patition)等同于一个消息队列,存放n条消息;一个主题(Topic)包括多个分区
二、常用分布式消息中间件特性对比
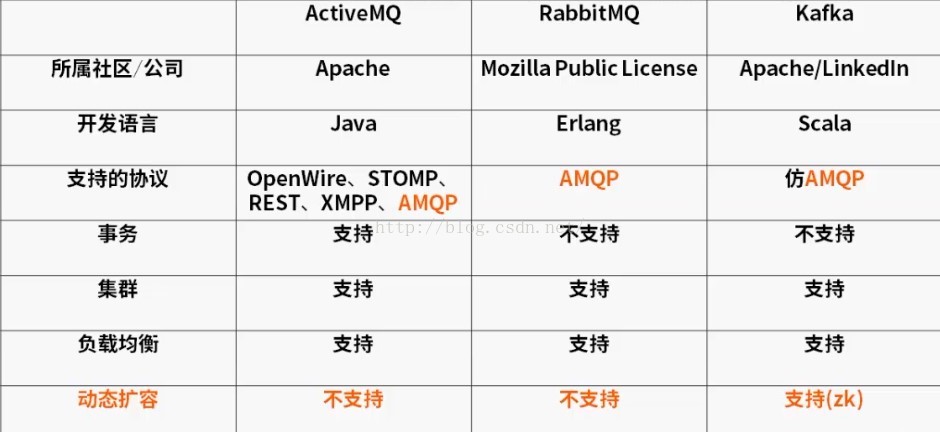
1、事务
在消息系统中,事务指多条消息一起发送时,要么全部发送成功,或全部回滚,不可能一部分成功,一部分失败
2、负载
大量的生产者和消费者向消息系统发送请求,消息系统必须能够均衡这些请求到n台服务器。
3、动态扩容
系统或服务不支持动态扩容,就意味着当访问量大于当前集群可处理数量时,不得不停止服务,反之,kafka支持zk管理集群,增加或减少一台服务器,并不影响生产环境的服务,从而达到扩容效果
高吞吐量、高水平扩展
三、Kafka消费者模型
Kafka消息系统基于发布-订阅模式,相对于ActiveMQ,没有点对点消息处理机制。
1、分区消费模型
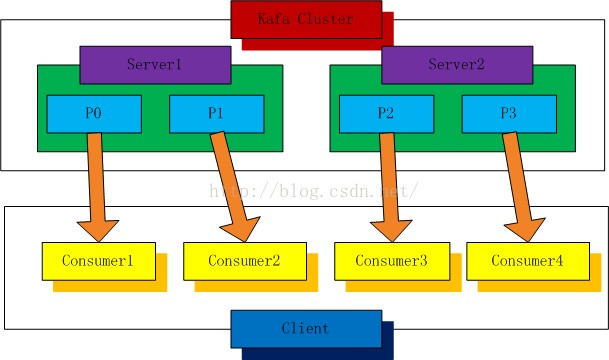
2个kafka 服务器,4个分区(P0-P3) ,分区消费模型即为:1个分区对应1个消费实例,如图4个分区,需要4个消费者实例从分区中取数据。
2、分区消费编码思路
(1)获取分区的size,一共多少个分区;
(2)针对每一个分区,分别创建一个线程,去消费该分区的数据
(3)每个线程即为一个消费者实例,通过连接;执行消费者构建;消费offset (偏移量);记录消息偏移量。
3、组消费模型
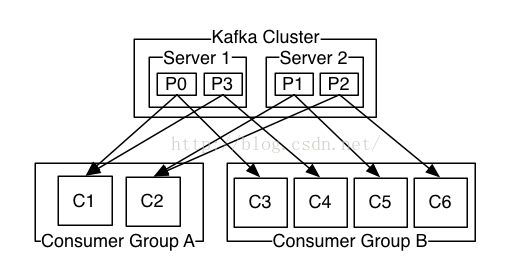
同样4个分区,P0-P3,这里使用GroupA,GroupB,GroupA可获取0,3,1,2分区的数据,GourpB也是。分组消费模型中,每个组都能拿到kafka集群当前全量数据。
4、组消费实现思路
(1)获取group里有多少个consumer实例
(2)根据实例个数,创建线程
(3)执行run方法,启动消费
四、Kafka生产者模型
1、同步生产模型
发送一条消息,如果没有收到kafka集群的确认收到的信号,则再次重发,直到发送次数超过设置的最大次数为止。其中有一次收到了确认,就接着发送下一条消息。
2、异步生产模型
消息发送到客户端的缓冲队列中,如果队列中条数到了设置的队列最大数或存放时间达到最大值,就把队列中的消息打包,一次性发送给kafka服务端。
3、同步、异步对比
同步生产模型:
(1)低消息丢失率;
(2)高消息重复率;
(3)高延迟,低吞吐量,每发一条,都要等着确认之后才继续发下一条
异步生产模型:
(1)低延迟;
(2)高发送性能;
(3)高消息丢失率(无确认机制,发送端队列满),不等待确认就直接发下一个,如果发送的队列已经满了,那接着发的消息就全丢失。另外队列满了发送给服务器,也无确认机制,整个队列就丢了。
4、应用场景
要求不能丢消息,对吞吐量没要求,使用同步
日志处理等,丢了几条也可接受,但对吞吐量要求极高,采用异步