Java IO4:字符编码
Posted IT·达人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java IO4:字符编码相关的知识,希望对你有一定的参考价值。
前言
字符编码,这本不属于IO的内容,但字节流之后写的应该是字符流,既然是字符流, 那就涉及一个"字符编码的"问题,考虑到字符编码不仅仅是在IO这块,Java中很多场景都涉及到这个概念,因此这边文章就专门详细写一下字符编码,具体 的网上有很多,但本文目的是尽量讲清楚各种编码方式的作用,个人认为,不求、也没有必要对字符编码理解地多么深入。
字符集和字符编码
第一个概念就是字符集和字符编码之间的区别:
1、字符集(charset)
字符集指的是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,常见的字符集有ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。
2、字符编码(encoding)
计算机要准确处理各种字符集文字,就要进行字符编码,以便计算机能够识别和存储各种文字。因此字符编码就是讲符号转换为计算机可以接受的数字系统的数,称为数字代码。
ASCII码
计算机里面只有数字0和1(严格说连0和1都没有,只有开和关,无非是用0和1表 示开关的状态罢了),在计算机软件里的一切都是用数字标识的额,屏幕上显示的一个一个字符也是数字。最初使用的计算机在美国,用到的字符很少,因此每一个 字符都用一个数字表示,一个字节所能表示的数字反内卫足以容纳所有这些字符。实际上表示这些字符的数字的字节最高位都是0,也就是说这些数字都在 0~127之间,如字符a对应97,字符b对应数字98,这种字符与数字的对应编码固定下来之后,这套编码规则被称为ASCII码(美国标准信息交换码)。一张简单的ASCII码表如图:
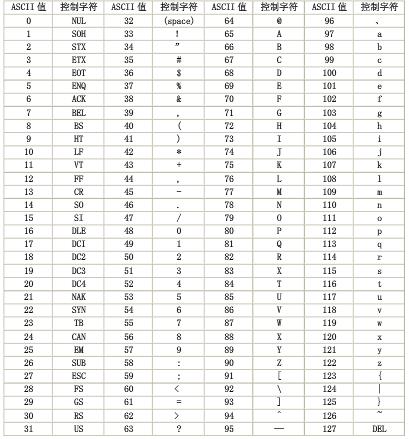
从表中可以看出ASCII码分为两部分:
1、0~31是控制字符,如换行、回车、删除等
2、32~126是打印字符,可以通过键盘输入并且能够显示出来
GB2312和GBK
随着计算机在其它国家的普及,许多国家把本地字符集引入了计算机,大大扩展了计算机中字符的范围。一个字节所能表示的范围不足以容纳中文字符(看看上面的ASCII码表就知道了),中国大陆将每一个中文字符都用两个字节表示,原有的ASCII码字符的编码保持不变。
为了将一个中文字符与两个ASCII码字符相区别,中文字符的每个字节最高位为1,中国大陆为每一个中文字符都指定了一个对应的数字,并于1980年制定了一套《信息技术 中文编码字符集》,这套规范就是GB2312。GB2312是双字节编码,总的编码范围是A1~F7,其实A1~A9是富豪区,总共包含682个符号;B0~F7是汉字区,总共包含6763个汉字。
GBK是在1995年制定的后续标准,全称为《汉字内码扩展规范》,是国家技术监督局为Windows 95所制定的新的汉字内码规范。GBK的出现是为了扩展GBK2312,并加入更多的汉字。GBK的编码范围是8140~FEFE(去掉XX7F),总共有23940个码位,能表示21003个汉字,它的编码是和GB2312兼容的,也就是说用GB2312编码的汉字可以用GBK来解码,并且不会有乱码问题。GBK还是现如今中文Windows操作系统的系统默认编码。
Unicode
在一个国家的本地化系统中出现的一个字符,通过电子邮件传送到另外一个国家的本地 化系统中,看到的就不是那个原始字符了,而是另外那个国家的一个字符或乱码,因为计算机里面并没有真正的字符,字符都是以数字的形式存在的,通过邮件传送 一个字符,实际上传送的是这个字符对应的字符编码,同一个数字在不同的国家和地区代表的很可能是不同的符号。
为了解决各个国家和地区之间各自使用不同的本地化字符编码带来的不便,人们将全世界所有的符号进行了统一编码,称之为Unicode(统一码、万国码)。 所有字符不再区分国家和地区,都是人类共有的符号,如"中"字在Unicode中不再是GBK中的D6D0,而是在任何地方都是4e2d,如果所有的计算 机系统都使用这种编码方式,那么4e2d这个字在任何地方都代表汉字中的"中"。Unicode编码的字符都占用两个字节的大小,也就是说全世界所有字符 个数不会超过65536个。
当然Unicode只包含65536个字符就想包含全世界所有的字符是远远不够的,所以Unicode提供了字符平面映射,链接地址上就是Wiki百科对于字符平面映射的解读。另外要提一点的是,Unicode是Java和XML的基础。
UTF-8和UTF-16
Unicode是一种字符集标准,而具体该标准应该如何应用到计算机中,则是另一个话题了,常用的Unicode编码方式有两种:
1、UTF-16。两个字节表示Unicode转换格式,这是定长的表示方法。也就是说不管什么字符都可以使用两个字节表示,两个字节是16Bit,所以叫做UTF-16。UTF-16编码非常方便,每两个字节表示一个字符,这个在字符串操作时大大简化了操作。
2、UTF-8。UTF-16统一采用了两个字节表示一个字符,虽然在表示上非常 简单,但是很大一部分字符用一个字节表示就够了,现在需要两个字节,存储空间放大了一倍。UTF-8就采取了一种变长技术,每个编码区域有不同的字码长 度,不同类型的字符可以是由1~6个字节组成。
两种编码方式比较,相对来说,UTF-16的编码效率较高,从字符到字节的相互转 换可以更简单,进行字符串操作也更好,它更适合在本地磁盘和内存之间使用,可以进行字符和字节之间的快速切换。但是UTF-16并不适合在网络之间传输, 因为网络传输易损坏字节流,一旦字节流损坏将很难恢复,所以相比较而言UTF-8更适合网络传输。另外UTF-8对ASCII字符采用单字节存储,单个字 符损坏也不会影响后面的其他字符,在编码效率上介于GBK和UTF-16之间,所以,UTF-8在编码效率和编码安全性上做了平衡,是理想的中文编码方 式。
Java与字符编码
Java中的字符使用的都是Unicode字符集,编码方式为UTF-16,Java技术在通过Unicode保证跨平台特性的前提下也支持了全扩展的本地平台字符集,而显示输出和键盘输入都是采用的本地编码。因此,免不了二者的转化问题。
看一个很简单的例子:

public static void main(String[] args) throws Exception
{
// 这里将字符串通过getBytes()方法,编码成GB2312
byte b[] = "大家一起来学习Java语言".getBytes("GB2312");
File file = new File("D:/Files/encoding.txt");
OutputStream out = new FileOutputStream(file);
out.write(b);
out.close();
}
看一下文件中是什么:

正常输出,无编码问题,但是如果这样:
public static void main(String[] args) throws Exception
{
// 这里将字符串通过getBytes()方法,编码成GB2312
byte b[] = "大家一起来学习Java语言".getBytes("ISO8859-1");
File file = new File("D:/Files/encoding.txt");
OutputStream out = new FileOutputStream(file);
out.write(b);
out.close();
}
再看一下文件中是什么:

乱码问题就出现了,通过上述操作的完整过程分析一下原因。
要再次说明的是,Java中的String都是Unicode字符集的。 Java中的各个类,对于英文字符的支持都非常好,可以正常地写入文件中,但对于中文字符就未必了。从Java源代码到输入文件正确的内容,要经 过"Java源代码->Java字节码->虚拟机->文件"几个步骤,在上述过程中的每一步都必须正确地处理汉字的编码,才能够使最终 有我们期望的结果。
"Java源代码->Java字节码",标准的Java编译器Javac使 用的字符集是系统默认的字符集,比如在中文Windows操作系统上就是GBK(上面GBK的部分已经说明过了),而在Linux操作系统上就是 ISO8859-1,所以大家会发现Linux操作系统上编译的类中源文件中的中文字符都出现了问题,解决办法就是在编译的时候添加encoding参 数,这样才能够与平台无关,用法是:javac -encoding GBK。
"Java字节码->虚拟机->文件",Java运行环境(JRE) 分英文版和国际版,但只有国际版才支持非英文字符。Java开发工具包(JDK)肯定支持多国字符,但并非所有的计算机用户都安装了JDK。很多操作系统 应用软件为了能够更好地支持Java,都内嵌了JRE的国际版本,为支持自己多国字符提供了方便。
问题就出"Java源代码->Java字节码上",这是由于JDK设置环境变量引起的。用程序看一下JDK环境变量:
public static void main(String[] args)
{
System.getProperties().list(System.out);
}
看一下输出的全部信息,有点长:
1 -- listing properties --
2 java.runtime.name=Java(TM) SE Runtime Environment
3 sun.boot.library.path=E:\\MyEclipse10\\Common\\binary\\com.sun....
4 java.vm.version=11.3-b02
5 java.vm.vendor=Sun Microsystems Inc.
6 java.vendor.url=http://java.sun.com/
7 path.separator=;
8 java.vm.name=Java HotSpot(TM) 64-Bit Server VM
9 file.encoding.pkg=sun.io
10 user.country=CN
11 sun.java.launcher=SUN_STANDARD
12 sun.os.patch.level=
13 java.vm.specification.name=Java Virtual Machine Specification
14 user.dir=F:\\代码\\MyEclipse\\TestIO
15 java.runtime.version=1.6.0_13-b03
16 java.awt.graphicsenv=sun.awt.Win32GraphicsEnvironment
17 java.endorsed.dirs=E:\\MyEclipse10\\Common\\binary\\com.sun....
18 os.arch=amd64
19 java.io.tmpdir=C:\\Users\\dell1\\AppData\\Local\\Temp\\
20 line.separator=
21
22 java.vm.specification.vendor=Sun Microsystems Inc.
23 user.variant=
24 os.name=Windows Vista
25 sun.jnu.encoding=GBK
26 java.library.path=E:\\MyEclipse10\\Common\\binary\\com.sun....
27 java.specification.name=Java Platform API Specification
28 java.class.version=50.0
29 sun.management.compiler=HotSpot 64-Bit Server Compiler
30 os.version=6.2
31 user.home=C:\\Users\\dell1
32 user.timezone=
33 java.awt.printerjob=sun.awt.windows.WPrinterJob
34 file.encoding=GBK
35 java.specification.version=1.6
36 user.name=dell1
37 java.class.path=F:\\代码\\MyEclipse\\TestIO\\bin
38 java.vm.specification.version=1.0
39 sun.arch.data.model=64
40 java.home=E:\\MyEclipse10\\Common\\binary\\com.sun....
41 java.specification.vendor=Sun Microsystems Inc.
42 user.language=zh
43 awt.toolkit=sun.awt.windows.WToolkit
44 java.vm.info=mixed mode
45 java.version=1.6.0_13
46 java.ext.dirs=E:\\MyEclipse10\\Common\\binary\\com.sun....
47 sun.boot.class.path=E:\\MyEclipse10\\Common\\binary\\com.sun....
48 java.vendor=Sun Microsystems Inc.
49 file.separator=\\
50 java.vendor.url.bug=http://java.sun.com/cgi-bin/bugreport...
51 sun.cpu.endian=little
52 sun.io.unicode.encoding=UnicodeLittle
53 sun.desktop=windows
54 sun.cpu.isalist=amd64
注意一下34行,表明了JDK使用的是GBK字符集(GBK是GB2312上的扩展,所以用GB2312字符集当然是没有问题的),这意味着Java对String的操作,都做了Unicode到GBK的转换。既然JDK用的GBK编码,那么用ISO8859-1字符集显示GBK编码出来的中文当然是有问题的。
这只是一个例子,在我们的应用程序中涉及I/O操作时,一般只要注意指定统一的编解码Charset集,就不会出现乱码问题。对有些应用程序如果不注意指定字符编码,则在中文环境中会使用操作系统的默认编码。如果编解码都在中文环境中,通常也没有问题,但还是强烈建议不要使用操作系统的默认编码,因为这样会使你的应用程序的编码格式和运行时环境绑定起来,这样在跨环境时很可能出现乱码问题。
以上是关于Java IO4:字符编码的主要内容,如果未能解决你的问题,请参考以下文章
片段(Java) | 机试题+算法思路+考点+代码解析 2023
java缓冲字符字节输入输出流:java.io.BufferedReaderjava.io.BufferedWriterjava.io.BufferedInputStreamjava.io.(代码片段
通过 Java 正则表达式提取 semver 版本字符串的片段