Spark在Yarn上运行Wordcount程序
Posted sunajing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark在Yarn上运行Wordcount程序相关的知识,希望对你有一定的参考价值。
前提条件
1.CDH安装spark服务
2.下载IntelliJ IDEA编写WorkCount程序
3.上传到spark集群执行
一.下载IntellJ IDEA编写Java程序
1.下载IDEA
官网地址:http://www.jetbrains.com/idea/ 下载IntlliJ IDEA后,进行安装。
2.新建Java项目
1.点击File
2.点击New Project
3.点击Java
注意:Project SDK要选择本机安装的JDK的位置,由于我的JDK是1.7,所以下面的Java EE version我选择的是Java EE 7
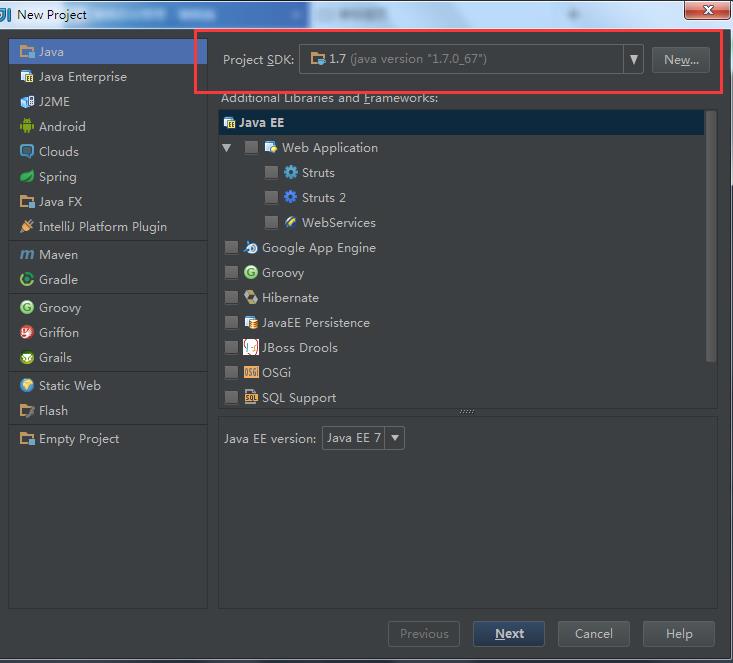
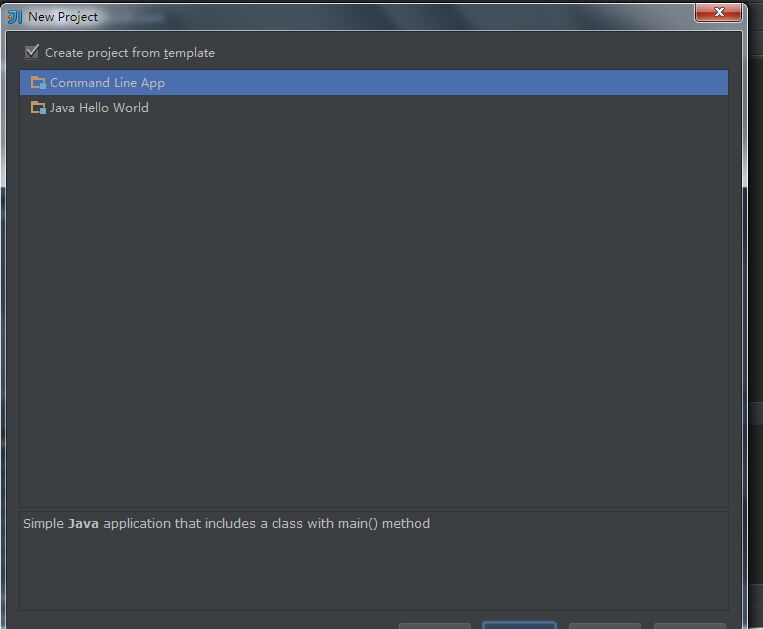
4.点击Next后,出现如下界面,勾选Create project from template,然后点击Next
5.点击Next,填写相应的项目名称,package等相关信息

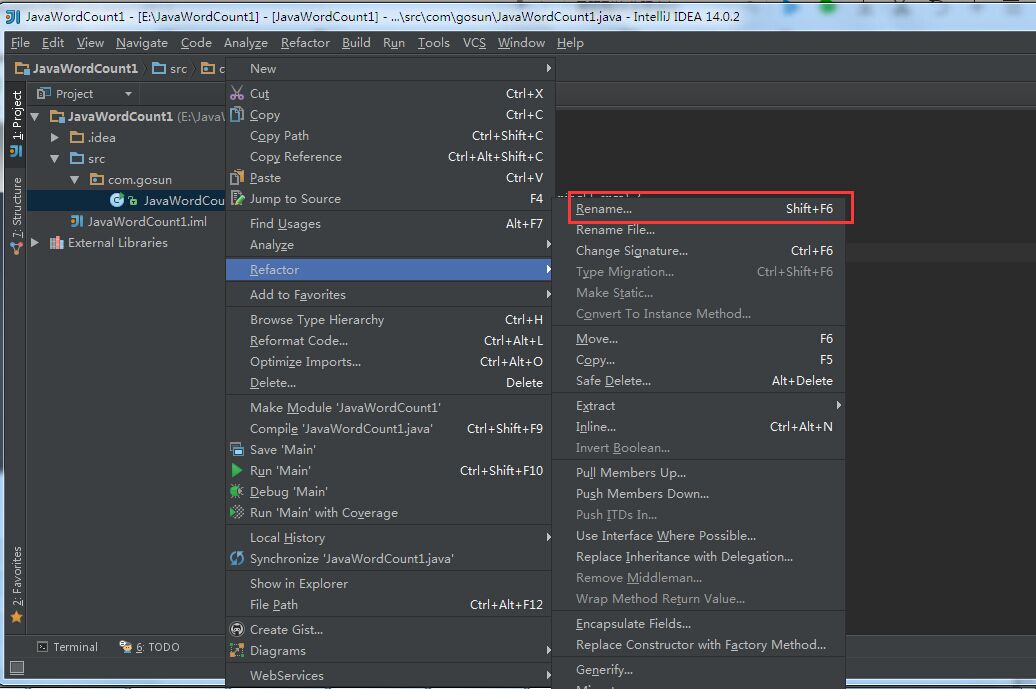
6.点击Finish,,出现如下界面,右键选择Refactor->Rename修改类名为自己想要的类名即可。
7.添加spark-assembly-1.3.0-cdh5.4.2-hadoop2.6.0-cdh5.4.2.jar到项目中
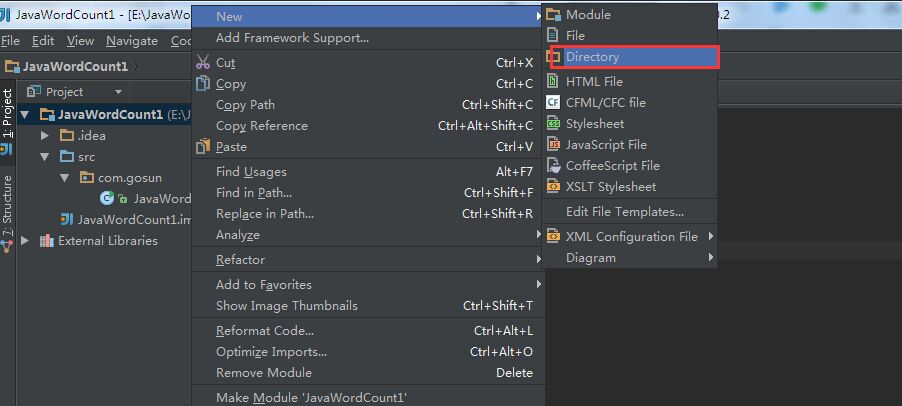
7.1创建名称为lib的目录
7.2将spark-assembly-1.3.0-cdh5.4.2-hadoop2.6.0-cdh5.4.2.jar (在spark集群的位置为:/usr/lib/spark/assembly/lib目录下)copy到lib目录下
然后右键点击jar包选择add Library,完成该动作后,在项目中就可以引用此jar包中的类了。
8.用Java实现WordCount功能
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; import java.util.Arrays; import java.util.List; import java.util.regex.Pattern; public final class JavaWordCount { private static final Pattern SPACE = Pattern.compile(" "); public static void main(String[] args) { if(args.length<1){ System.err.print("Usage:JavaWordCount<file>"); System.exit(1); } SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount"); JavaSparkContext ctx = new JavaSparkContext(sparkConf); JavaRDD<String> lines = ctx.textFile(args[0],1); System.out.println(System.getenv("SPARK_HOME")); JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String s) throws Exception { return Arrays.asList(SPACE.split(s)); } }); JavaPairRDD<String,Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<String, Integer>(s,1); } }); JavaPairRDD<String,Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer i1, Integer i2) throws Exception { return i1+i2; } }); List<Tuple2<String, Integer>> output = counts.collect(); for (Tuple2<?, ?> tuple : output) { System.out.println(tuple._1() + ": " + tuple._2()); } ctx.stop(); } }
9.打成jar包
9.1点击File
9.2选择Project Structure
9.3选择Artifacts
可修改右边Name生成jar包的名称
9.4点击OK,完成生成jar包,可在对应的目录下找到刚才生成的jar包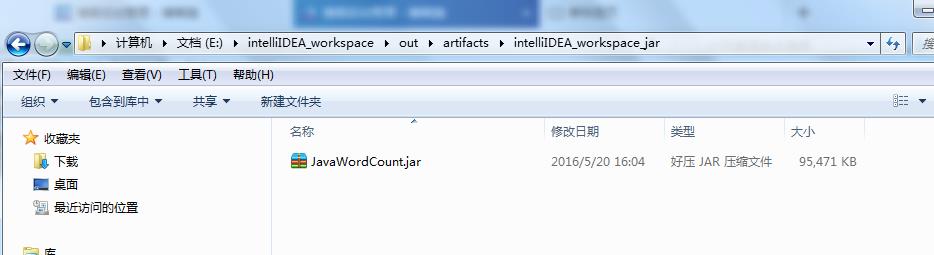
10.将生成的jar包上传到spark某个目录下
11.spark-submit --master yarn-client --name JavaWordCount --class JavaWordCount --executor-memory 1G --total-executor-cores 2 /etc/spark/JavaWordCount.jar hdfs://master:8020/suajing/install.log
其中,红色标注部分根据实际的项目进行修改,
我的项目名称为JavaWordCount,则--name 为JavaWordCount,
我的Class没有pacakage,如果你的class是在某个pacakage底下,则需要将class修改成包+类名全路径,例如:com.gosun.JavaWordCount。
我的jar包放在/etc/spark/目录下,写成/etc/spark/JavaWordCount.jar
hdfs上的文件路径为上面所示。
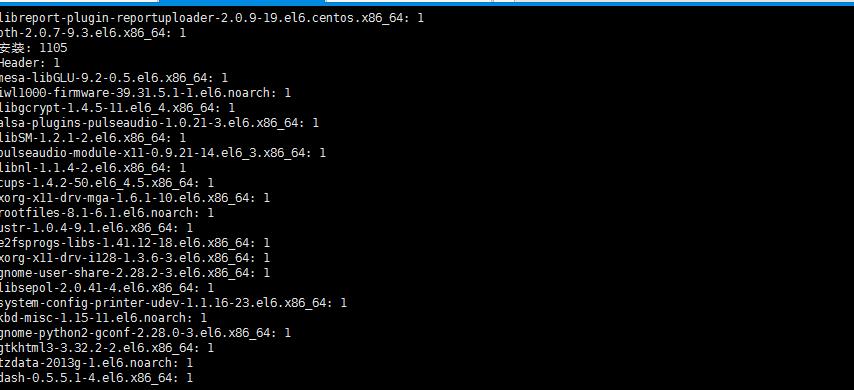
12.执行结果:未报错就表示执行成功了,可以看到如下统计的结果
以上是关于Spark在Yarn上运行Wordcount程序的主要内容,如果未能解决你的问题,请参考以下文章