机器学习工作流程与模型调优
Posted 在那不遥远的地方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习工作流程与模型调优相关的知识,希望对你有一定的参考价值。
上一讲中主要描述了机器学习特征工程的基本流程,其内容在这里:机器学习(一)特征工程的基本流程
本次主要说明如下:
1)数据处理:此部分已经在上一节中详细讨论
2)特征工程:此部分已经在上一节中详细讨论
3)模型选择
4)交叉验证
5)寻找最佳超参数
首先看下总图:
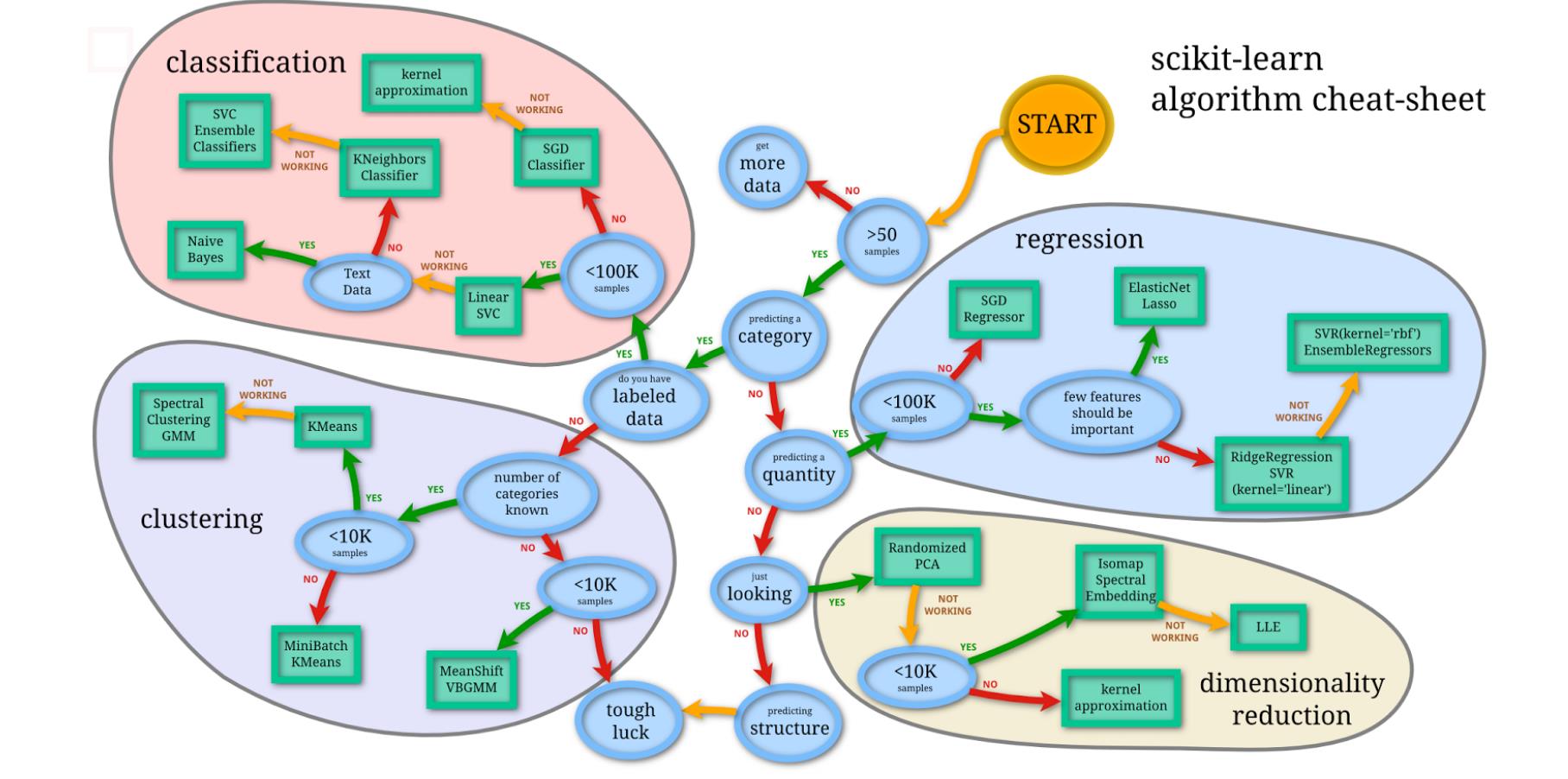
(一)模型选择:
1)交叉验证
- 交叉验证集做参数/模型选择
- 测试集只做模型效果评估
2)K折交叉验证:
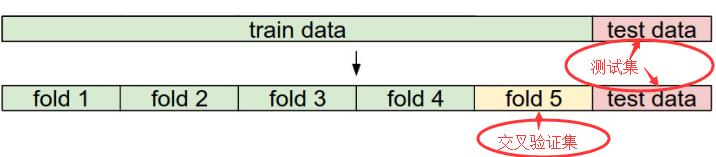
在Python中有这样的函数用于在交叉验证过程中对参数的选择
(二)模型的状态
a. 过拟合:过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
b. 欠拟合 :模型在训练过程中没有训练充分,导致模型很好的表现出数据原有性质。
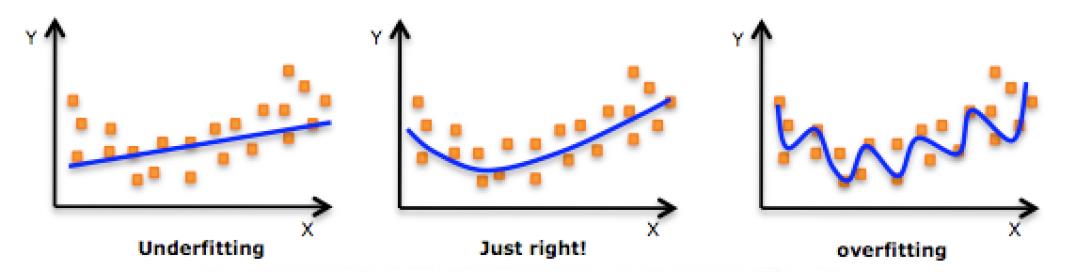
模型状态验证工具:学习曲线
通过在给定训练样本增加的时候,测试机和训练集中准确率的变化趋势可以看到现在模型的状态。
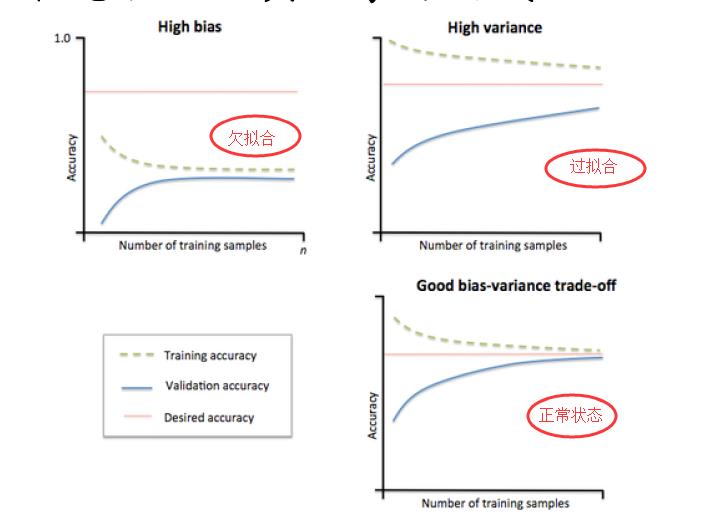
怎么防止过拟合呢?
- 获取更多数据: 让模型「看见」尽可能多的「例外情况」,它就会不断修正自己,从而得到更好的结果;
a)从数据源头采集更多数据
b) 通过一定规则扩充数据集,如加入随机噪声,图的旋转平移缩放
c) 采样技术
- 减小模型的复杂度:减少数的棵树,网络层数等;
- 减少训练时间 Early stopping:提前终止(当验证集上的效果变差的时候);
- 加入正则项 / 增大正则化系数:这类方法直接将权值的大小加入到 Cost 里,在训练的时候限制权值变大;
- 使用集成学习:综合多个学习器的结果;
- Dropout:类似于集成学习,是的网络结构发生了改变
怎样防止欠拟合? (一般很少出现)
- 找更多的特征
- 减小正则化系数
(三)模型分析
1)线下模型权重分析:线性或者线性kernel的model
- Linear Regression
- Logistic Regression
- LinearSVM
2)对权重绝对值高/低的特征
- 做更细化的工作
- 特征组合
3) Bad-case分析
分类问题
- 哪些训练样本分错了?
- 我们哪部分特征使得它做了这个判定?
- 这些bad cases有没有共性
- 是否有还没挖掘的特性
回归问题
- 哪些样本预测结果差距大,为什么?
(四)模型融合
1)平均法
1. 简单平均法(simple averaging)

2. 加权平均法(weighted averaging)
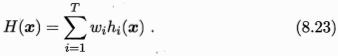
注意:必须使用非负权重才能确保集成性能优于单一最佳个体学习器,因此在集成学习中一般对学习器的权重法以非负约束。
简单平均法其实是加权平均法令w=1/T的特例。集成学习中的各种结合方法其实都可以视为加权平均法的特例或变体。加权平均法的权重一般是从训练数据中学习而得。由于现实任务中样本不充分或存在噪声,使得学得的权重不完全可靠,有时加权平均法未必一定优于简单平均法。
2)投票法
对分类任务来说,最常见的结合策略使用投票法
1. 绝对多数投票法(majority voting):即若某标记得票过半数,则预测为该标记;否则拒绝预测

2. 相对多数投票法(plurality voting):即预测为得票最多的标记,若同时有多个标记获最高票,则从中随机选取一个。

3. 加权投票法(weighted voting):绝对多数投票法在可靠性要求较高的学习任务中是一个很好的机制,若必须提供结果,则使用相对多数投票法。

- 类标记:使用类标记的投票亦称“硬投票”(hard voting)。
- 类概率:使用类概率的投票亦称“软投票”(soft voting)。
以上两种不能混用,若基学习器产生分类置信度,例如支持向量机的分类间隔值,需使用一些技术如Platt缩放、等分回归、等进行校准后才能作为类概率使用。若基学习器的类型不同,则其类概率值不能直接进行比较,可将类概率输出转化为类标记输出然后再投票。
3)Stacking:Stacking方法是指训练一个模型用于组合其他各个模型。首先我们先训练多个不同的模型,然后把之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。理论上,Stacking可以表示上面提到的两种Ensemble方法,只要我们采用合适的模型组合策略即可。但在实际中,我们通常使用logistic回归作为组合策略。
关于集成学习这里也有更详细的描述:集成学习
参考
- 七月在线机器学习课程
- 周志华:机器学习西瓜书
以上是关于机器学习工作流程与模型调优的主要内容,如果未能解决你的问题,请参考以下文章