第一次工作报告
Posted WHYDD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次工作报告相关的知识,希望对你有一定的参考价值。
要求
1. 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
2. 使用性能测试工具进行分析,找到性能的瓶颈并改进
3. 对代码进行质量分析,消除所有警告
4. 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
5. 使用Github进行代码管理
6. 撰写博客
基本功能
1. 统计文件的字符数
2. 统计文件的单词总数
3. 统计文件的总行数
4. 统计文件中各单词的出现次数
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
7. 在Linux系统下,进行性能分析,过程写到blog中(附加题)
PSP:

前期的分析:
首先看到了题目就立刻想到了会有巨大的数据需要进行处理,自然就会联想应该如何去解决数据的存放问题与查找问题,从功能需求中一步步想到了使用哈希表对此进行存储,于是便有了初步的想法:
1、打开一个文件,读取文件内容;
2、将读取的信息进行处理;
3、构造一个哈希函数,创建一个哈希表。
之后有关测试文件出来了,便遇到了一个很棘手的问题:对于文件的遍历,这个起初是打算用C语言中的fopen函数,但仔细一分析发现并不能实现具体的要求,于是便寻求一个可以遍历文件的操作,在查阅资料后找到了C++语言中的findfirst和findnext函数可以实现文件操作,于是便开始对其的学习,由于之前未接触过C++,对于其中过程的了解耗费了很长的时间,于是便对测试文件进行了初步的遍历实验,起初的结果很不近人意,只能遍历文件的第一个子目录里的文件,无法进入子文件夹,进过判定条件的修改,最终实现了所有文件的遍历。
此刻第一步便达到了目的,于是开始了文件读取问题的思考,找到了两个函数,get和getline函数,首先get函数可以很好的读取文件中的字符,依靠对文件是否结束的判定可以持续读取,这个的好处就在于可以无所谓文件中全部的字符总量,可以一边读一边根据判定条件进行对单词与词组的操作,并且可以按照换行符的数量判断一个文件中的行数,这个可以说是很理想;其次是getline函数,它可以一次读取一行,这个可以省去单独统计换行符的工作,每次调用的时候就可以进行行数的累加,然后可以直接用一行一行的处理单词与词组,这个可以更加模块化,但是缺点便是文件中会出现一行中有数十万的字符,就会使得数组溢出导致失败;经过考虑,我选择了getline函数。
然后就是开始对这个项目进行框架的搭建,从字符、单词到词组,每一个都单独进行搭建,互不相关,为了达到这个目的,分别为单词与词组设计了各自的哈希表,由于要同时对出现频率的统计,决定构造一个结构体数组,里面存储字符串与整型数据,而数组的地址则用设计的哈希函数进行计算。
代码设计:
1、 文件遍历
利用已经试验过的findfirst与findnext函数进行操作;
2、 文件读取
利用ifstream函数打开文件,再利用getline函数对文件内容进行读取,在文件函数中直接调用字符的函数、单词的函数、词组的函数;
3、 字符统计
对传入的字符数组,进行遍历,并随之进行数据的统计;
4、 单词统计
对传入的字符数组进行有条件的遍历,筛选出符合条件的单词,调用单词的哈希表构造函数
(1) 单词哈希表构造
消除大小写的影响,即在计算哈希函数时使用单词前四个字母时,全部化为小写进行求解,利用平方取中法构造哈希函数,利用开放定址发解决冲突,其中需要调用单词比较函数和单词优先级比较函数;
1) 单词比较函数
比较新单词与哈希表中同一位置单词是否为相同单词;
2)单词优先比较函数
比较两个相同单词在字典输出的情况下的先后次序;
5、 词组统计
对传入的字符数组进行有条件的遍历,筛选出符合条件的词组,调用词组的哈希表构造函数 ,其中判断词组需要大量的判定条件;
(1) 词组哈希表构造
消除大小写的影响,即在计算哈希函数时使用第一个单词与第二个单词各前四个字母时,全部化为小写进行求解,利用平方取中法构造哈希函数,利用开放定址发解决冲突,其中需要调用词组比较函数和词组优先级比较函数;
1) 词组比较函数
比较新词组与哈希表中同一位置词组是否为相同单词;
2) 单词优先比较函数
比较两个相同词组在字典输出的情况下的先后次序;
6、 排序
利用冒泡排序法对哈希结构体进行排序,将前十出现频率的结构体返回主函数
7、文件输出
利用ofstream函数进行reasult.txt文件的构造;
具体编码:
1、 文件遍历函数:
利用findfirst函数与findnext函数,不断利用文件地址对文件进行遍历,在遍历的同时将地址字符串传入到文件读取子函数中;
2、 文件读取函数:
在文件遍历中调用此函数,利用传入的地址和ifstream函数对文件进行打开操作,设置一个字符数组,再用getline函数将文件中的数据传入数组中,由于getline是读取文件的一行,此时便可以记录行数的变化,当生成一个数组时便调用字符统计子函数并返回一个值代表字符数,调用单词统计子函数并返回一个单词数,调用词组统计子函数不返回值。
3、 字符统计函数:
判断从文件读取子函数传入的字符数组中的字符,并计数
4、 单词统计函数:
从字符数组的首地址开始依次判断,符合单词的条件便调用单词哈希构造子函数;
(1)单词哈希构造函数:
利用单词的前四位相同的条件,将其ASCLL码值进行求和,再平方取模,得到的便是存入的地址,为了同时统计单词的个数,构造了结构体数组,在结构体中存入单词与频率,在存入哈希表中时,如果地址处已存单词,需要进行相同性的比较与优先级的比较,于是调用单词比较子函数与单词优先比较子函数;
(2)单词比较函数:
比较传入的两个单词,依次字符进行比较,遇见不同地方便进行判断,如果相同字符数小于4个,则返回不同,如果大于4,则判断之后是否全是数字;
(3)单词优先比较函数:
此函数在单词比较之后调用,此时传入的两个单词均为相同,则先判断相同字符的优先,如果相同则判断不同的优先;
5、 词组统计函数:
为了不与单词发生交互,进行单独构造,遇见单词则判断之后是否有单词出现,如果没有,从新的地址进行第一个单词的判断,如果有则调用词组哈希构造,之后重复;
(1) 词组哈希构造函数:
利用词组的第一个单词前4个字符与第二个单词前4个字符的ASCLL值求和,平方取模,获得地址,存入哈希表,构造一个结构体存储词组与频率,在存储的时候调用词组比较与词组优先比较函数,类似单词哈希构造
(2) 词组比较函数:
先判断第一个单词是否相同,再判断第二个,具体操作类似单词比较;
(3) 词组优先判断函数:
先判断第一个单词的优先,再判断第二个,具体操作类似单词优先比较;
6、 排序函数:
将单词哈希表与词组哈希表中的频率进行排序,采取的是冒泡排序方法,为了同时输出字符串和频率,单独构造了一个结构体存储,此结构体存储的是前十的字符串与频率;
7、 文件输出函数:
利用ofstream函数生成result.txt文件,并将答案写入文件。
8、 main函数
主函数中调用了一次文件遍历子函数,便是输出的代码。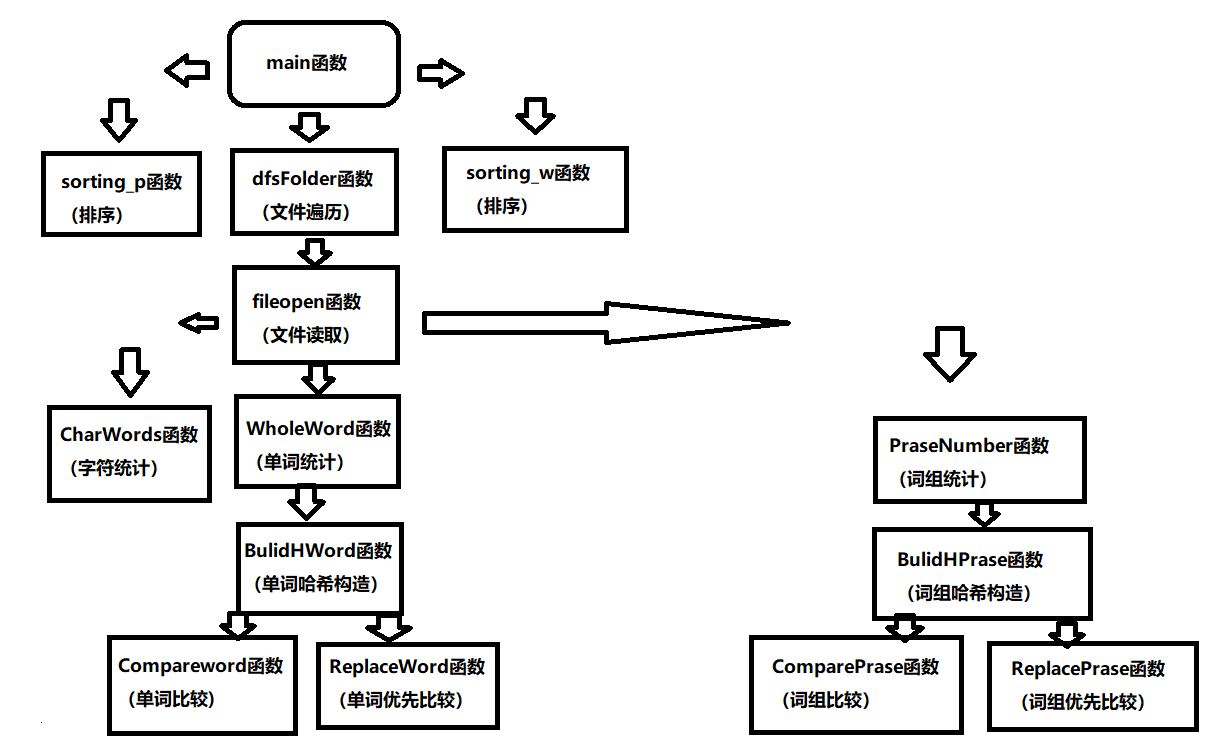
测试结果:
自己构造的测试集:
文件小的时候只能输出正确的行数、字符数与单词数,文件一大程序就会崩溃;
助教给的测试集:
无法全部跑完;
崩溃原因分析:
1、 在读取字符的时候使用的是getline,但之后的调试与编译的时候,出现了数组溢出的事情,所以在get与getline的选择上出现了错误,应该选择更加安全的get,
2、 对于哈希表的构造不够好,由于自己是用结构体数组,也会出现数据溢出的问题,还有关于哈希函数的构造也不够好,容易发生冲突,导致的大量的计算与调用函数,使得程序运行很慢;
3、 在判断单词与词组的时候,需要考虑的东西很多,很容易就会忽视一个,导致程序无法正常运行,由于多条条件的判断导致自己很容易出错;
4、 比较难以实现的是对哈希表的排序,最终确定了使用冒泡排序,这也导致了运行时间过长;
5、 各类细节问题,例如一开始使用的是int型数据,到最后才意识到了需要使用长整型,导致了代码很多地方需要修改,以至于发生了一些不可描述的问题;
代码优化:
1、 在一些循环语句中,例如for循环,一开始判定的条件是到达数组地址最大值的时候停止,经过考虑,于是使用了计算字符串长度的函数,将条件表达式的里的值改成了字符串真正懂得长度,但任然大量的调用了strlen函数,在代码交上以后又想到了可以直接使用do……while循环,直接判断数组为空,便可停止循环;
2、 尽量使用有符号长整型,但为了答案不会出错,我选择了无符号,这会大量浪费运行时间,应该将不需要无符号的数改为有符号;
3、 函数调用过于深,这次的程序发生了5层函数的调用,最好可以将其简化;
4、 有一点没用注意,便是没用多使用const,因为如果一个const声明的对象的地址不被获取,允许编译器不对它分配储存空间。这样可以使代码更有效率,而且可以生成更好的代码。
5、 热行分析

由于采用了无比慢的排序方法导致的两个sorting函数运行所占时间很多;
教训与总结
首先从架构来说,自己在项目一开始的时候没有确定一个特别明确的架构,导致在编码的时候发现了思路不清楚的问题,之后才逐渐完善了架构,便浪费了不少时间,一个好的架构不仅在开发上有助于代码的实现,还能解决程序耦合的问题;其次是没有一个明确的设计方案,只是大致一想,就开始编码,一边编一边想解决方案,导致了很深的函数调用,最终不易于调试与修改;再是自己在编码的时候忘记了先编好输出以便于一边编一边测试,导致了自己苦于编好了很多函数却在测试时跳出了无数的bug,而且不易于修改,这个问题老师很早在课堂上提到过,要编几行就进行测试,而自己却没有注意,运行的时候十分的后悔,过于复杂的程序导致了我不知如何去修改;最后就是书到用时方恨少,对于文件遍历的问题自己将近花费了五分之一的时间,就是由于自己对于这个方面了解的太少,只能临时抱佛脚,还有本来可以用C++的一些类就可以很容易解决的问题,只能自己利用C语言复杂的进行编写,例如同学使用了一个C++中map的类就可以解决存储的问题,自己感觉用的方法都很“蠢”,不够灵活。
在这次个人作业中,我深深地感受到了自己在编码方面的严重不足,不仅是对于各个语言的理解,还有是对于它们的灵活运用,由于自己知识储备的严重不足,遇到问题都无法及时给出一个合适的解决方案,需要一个个去百度,甚至是去从头去看书,在这个地方花费的时间将近有四分之一,导致了自己的思路不够流畅,所以要加强自己对于编程书的阅读,不能再拘泥于老师布置的任务,从现在开始要学习C++等更加便捷的语言,还有以后在编程之前要进行一次对于设计的思考,等到自己感觉设计已经明确并且可行时,再进行编码,还有就是要注意好每一个细节,尽量在编码的时候就最好注意到,最后也是我印象最深刻的就是随时编码随时测试,多写注释,避免遗忘。综上所述,简言之就是“无他,唯手熟尔”,以后自己要多思考、多编程。
以上是关于第一次工作报告的主要内容,如果未能解决你的问题,请参考以下文章