问题背景:好吧,文章标题是瞎取得。平常用cmd运行python代码问题不大,我在学习《机器学习实战》这本书时,发现cmd无法运行
import numpy as np以及import matplotlib*这条语句,原因是没有安装numpy和matplotlib。虽然用Anaconda的prompt以及Spyder等都可以成功运行,但如何在cmd环境下使用代码中含有numpy和matplotlib代码的文件呢?
至于如何安装,直接给答案:
用pip install numpy和pip install matplotlib命令即可,如图:

接下来的代码不是给你们看的,是给我自己看的(っ•̀ω•́)っ✎⁾⁾
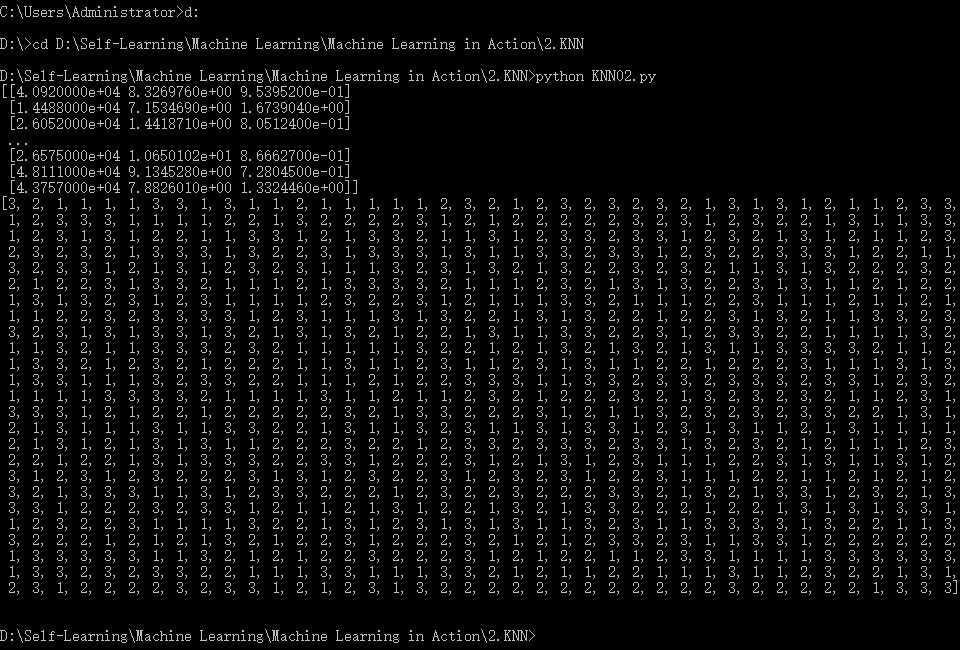
现在我们试着运行代码:
这里的文件名为KNN02.py,内容来自《机器学习实战》
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 29 11:14:25 2018
@author: CHJ
"""
import numpy as np
"""
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
"""
def file2matrix(filename):
#打开文件
fr = open(filename)
#读取文件所有内容
array0Lines = fr.readlines()
#print(array0Lines)
#得到文件行数
numberOfLines = len(array0Lines)
#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3)) #zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
#返回的分类标签向量
classLabelVector = []
#行的索引值
index = 0
for line in array0Lines:
#s.strip(rm),当rm空时,默认删除空白符(包括\'\\n\',\'\\r\',\'\\t\',\' \')
line = line.strip()
#print(line)
#使用s.split(str ="",num = string,cout(str))将字符串根据\'\\t\'分隔符进行切片。
listFromLine = line.split(\'\\t\') #将上一步得到的整行数据分割成一个元素列表
#print(listFromLine)
# 每列的属性数据
returnMat[index,:] = listFromLine[0:3] #将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
#print(returnMat[index,:])
#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == \'didntLike\': #索引值-1表示列表中最后一列元素
classLabelVector.append(1)
elif listFromLine[-1] == \'smallDoses\':
classLabelVector.append(2)
elif listFromLine[-1] == \'largeDoses\':
classLabelVector.append(3)
index += 1
return returnMat,classLabelVector
if __name__ == "__main__":
#打开的文件名
filename = \'datingTestSet.txt\'
#打开并处理数据
datingDataMat, datingLables = file2matrix(filename)
print(datingDataMat)
print(datingLables)
#print(len(datingLabel))
看看结果:
__现在要用到matplotlib,同样也是cmd -> pip install matplotlib __
安装成功了,现在我试着在cmd环境下运行以下代码:
文件名:KNN02.py
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 29 11:14:25 2018
@author: CHJ
"""
import numpy as np
"""
函数说明:打开并解析文件,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
"""
def file2matrix(filename):
#打开文件
fr = open(filename)
#读取文件所有内容
array0Lines = fr.readlines()
#print(array0Lines)
#得到文件行数
numberOfLines = len(array0Lines)
#返回的NumPy矩阵,解析完成的数据:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3)) #zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
#返回的分类标签向量
classLabelVector = []
#行的索引值
index = 0
for line in array0Lines:
#s.strip(rm),当rm空时,默认删除空白符(包括\'\\n\',\'\\r\',\'\\t\',\' \')
line = line.strip()
#print(line)
#使用s.split(str ="",num = string,cout(str))将字符串根据\'\\t\'分隔符进行切片。
listFromLine = line.split(\'\\t\') #将上一步得到的整行数据分割成一个元素列表
#print(listFromLine)
# 每列的属性数据
returnMat[index,:] = listFromLine[0:3] #将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
#print(returnMat[index,:])
#根据文本中标记的喜欢的程度进行分类,1代表不喜欢,2代表魅力一般,3代表极具魅力
if listFromLine[-1] == \'didntLike\': #索引值-1表示列表中最后一列元素
classLabelVector.append(1)
elif listFromLine[-1] == \'smallDoses\':
classLabelVector.append(2)
elif listFromLine[-1] == \'largeDoses\':
classLabelVector.append(3)
index += 1
return returnMat,classLabelVector
"""编写一个可以将数据可视化的showdatas函数"""
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
def showdatas(datingDataMat,datingLabels):
#设置汉字格式(这里选择:华文新魏 常规)
font = FontProperties(fname = r\'C:\\Windows\\Fonts\\STXINWEI.TTF\', size = 14)
#将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
#当nrow=2, ncols = 2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig,axs = plt.subplots(nrows =2,ncols=2,sharex=False,sharey = False,figsize = (13,8))
#numberOfLabels = len(datingLabels)
LabelsColors = []
for i in datingLabels:
if i ==1:
LabelsColors.append(\'black\')
if i ==2:
LabelsColors.append(\'blue\')
if i ==3:
LabelsColors.append(\'red\')
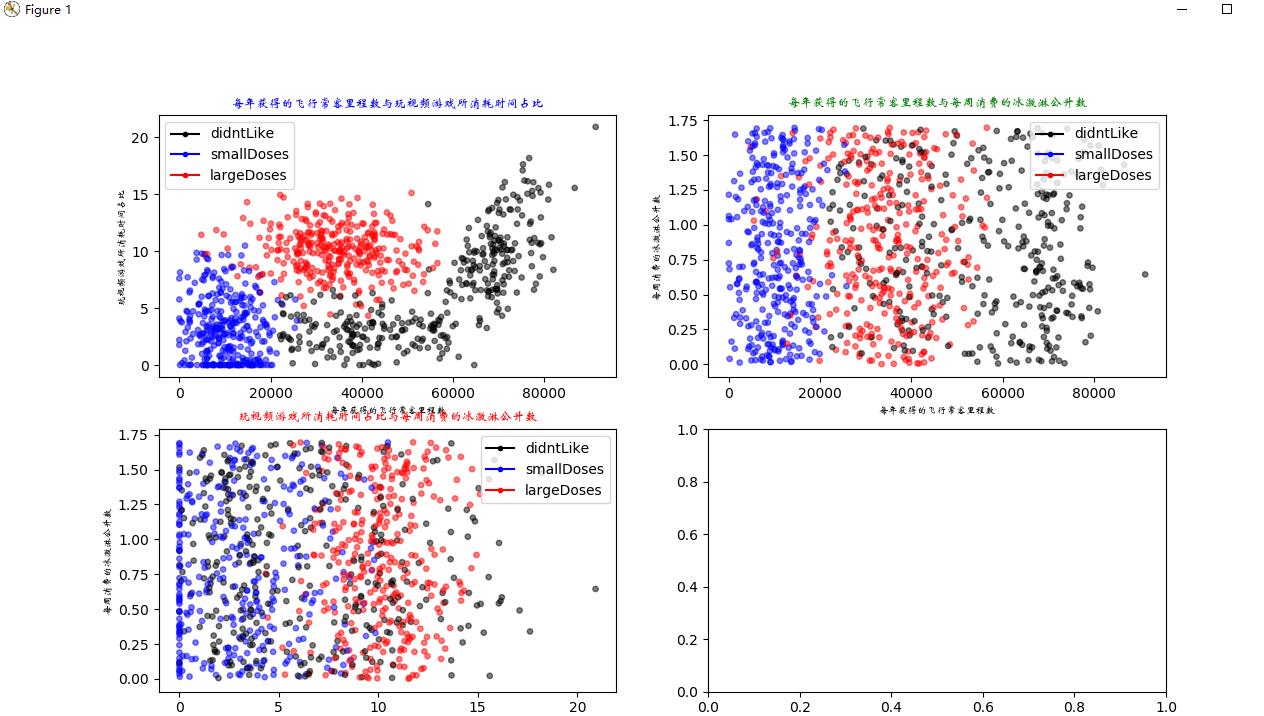
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x = datingDataMat[:,0],y = datingDataMat[:,1],color = LabelsColors,s = 15,alpha = 0.5)
#设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title(u\'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比\',FontProperties = font)
axs0_xlabel_text = axs[0][0].set_xlabel(u\'每年获得的飞行常客里程数\',FontProperties = font)
axs0_ylabel_text = axs[0][0].set_ylabel(u\'玩视频游戏所消耗时间占比\',FontProperties = font)
plt.setp(axs0_title_text, size = 9,weight = \'bold\',color = \'blue\')
plt.setp(axs0_xlabel_text,size = 7,weight = \'bold\',color = \'black\')
plt.setp(axs0_ylabel_text,size = 7,weight = \'bold\',color = \'black\')
#画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title(u\'每年获得的飞行常客里程数与每周消费的冰激淋公升数\',FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u\'每年获得的飞行常客里程数\',FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u\'每周消费的冰激淋公升数\',FontProperties=font)
plt.setp(axs1_title_text, size=9, weight=\'bold\', color=\'green\')
plt.setp(axs1_xlabel_text, size=7, weight=\'bold\', color=\'black\')
plt.setp(axs1_ylabel_text, size=7, weight=\'bold\', color=\'black\')
#画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[1][0].scatter(x=datingDataMat[:,1], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs2_title_text = axs[1][0].set_title(u\'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数\',FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u\'玩视频游戏所消耗时间占比\',FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u\'每周消费的冰激淋公升数\',FontProperties=font)
plt.setp(axs2_title_text, size=9, weight=\'bold\', color=\'red\')
plt.setp(axs2_xlabel_text, size=7, weight=\'bold\', color=\'black\')
plt.setp(axs2_ylabel_text, size=7, weight=\'bold\', color=\'black\')
#设置图例
didntLike = mlines.Line2D([], [], color=\'black\', marker=\'.\',
markersize=6, label=\'didntLike\')
smallDoses = mlines.Line2D([], [], color=\'blue\', marker=\'.\',
markersize=6, label=\'smallDoses\')
largeDoses = mlines.Line2D([], [], color=\'red\', marker=\'.\',
markersize=6, label=\'largeDoses\')
#添加图例
axs[0][0].legend(handles=[didntLike,smallDoses,largeDoses])
axs[0][1].legend(handles=[didntLike,smallDoses,largeDoses])
axs[1][0].legend(handles=[didntLike,smallDoses,largeDoses])
#显示图片
plt.show()
if __name__ == "__main__":
#打开的文件名
filename = \'datingTestSet.txt\'
#打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
# =============================================================================
# print(datingDataMat)
# print(datingLables)
# #print(len(datingLabel))
# =============================================================================
showdatas(datingDataMat, datingLabels) #显示图像
在cmd下运行如图:

发现它会自动唤醒我安装的Python3.6
输出图像: