Flink容错机制
Posted Asu_PC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink容错机制相关的知识,希望对你有一定的参考价值。
- Flink的Fault Tolerance,是在在Chandy Lamport Algorithm的基础上扩展实现了一套分布式Checkpointing机制,这个机制在论文"Lightweight Asynchronous Snapshots for Distributed Dataflows"中进行了详尽的描述。
1、State
所谓的Distributed Snapshot,就是为了保存分布式系统的State,那么首先我们需要定义清楚什么是分布式系统的State。考虑到上述分布式模型的定义,分布式系统State同样是由“进程状态”和“通道状态”组成的。
- Event:分布式系统中发生的一个事件,在类似于Flink这样的分布式计算系统中从Source输入的新消息相当于一个事件。
- 进程状态:包含一个初始状态(initial state),和持续发生的若干Events。初始状态可以理解为Flink中刚启动的计算节点,计算节点每处理一条Event,就转换到一个新的状态。
- 通道状态:我们用在通道上传输的消息(Event)来描述一个通道的状态。
在某一个时刻的某分布式系统的所有进程和所有通道状态的组合,就是这个分布式系统的全局状态。基于上述的双进程双通道的最简分布式系统,为了描述算法,可以设计一个“单令牌状态”转换系统,两个进程通过接收和发出令牌,会在S0、S1两个State之间转换,整个分布式系统则会在如下所示的4种全局状态(Global State)之间转换。

Flink 分布式Checkpointing是通过Asynchronous Barrier Snapshots的算法实现的,该算法借鉴了Chandy-Lamport算法的主要思想,同时做了一些改进,这些改进在论文"Lightweight Asynchronous Snapshots for Distributed Dataflows"中进行了详尽的描述。
在Asynchronous Barrier Snapshots(ABS)算法中用Barrier代替了C-L算法中的Marker,针对DAG的ABS算法执行流程如下所示:
- Barrier周期性的被注入到所有的Source中,Source节点看到Barrier后,会立即记录自己的状态,然后将Barrier发送到Transformation Operator。
- 当Transformation Operator从某个input channel收到Barrier后,它会立刻Block住这条通道,直到所有的Operator都收到Barrier,此时该Operator就会记录自身状态,并向自己的所有output channel广播Barrier。
- Sink接受Barrier的操作流程与Transformation Operator一样。当所有的Barrier都到达Sink之后,并且所有的Sink也完成了Checkpoint,这一轮Snapshot就完成了。
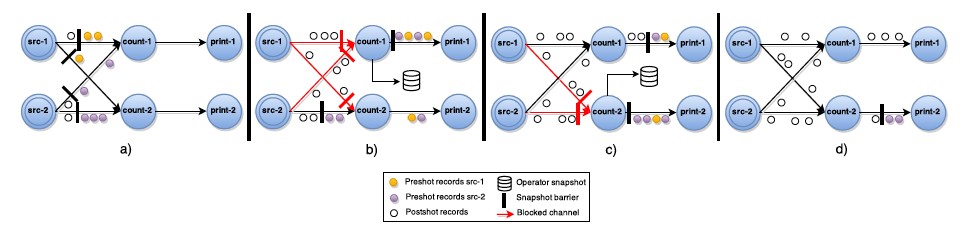
注意:
(1)、出现一个Barrier,在该Barrier之前出现的记录都属于该Barrier对应的Snapshot,在该Barrier之后出现的记录属于下一个Snapshot。来自不同Snapshot多个Barrier可能同时出现在数据流中,也就是说同一个时刻可能并发生成多个Snapshot。当一个中间(Intermediate)Operator接收到一个Barrier后,它会发送Barrier到属于该Barrier的Snapshot的数据流中,等到Sink Operator接收到该Barrier后会向Checkpoint Coordinator确认该Snapshot,直到所有的Sink Operator都确认了该Snapshot,才被认为完成了该Snapshot
如下图:

(2)、数据对齐
当Operator接收到多个输入的数据流时,需要在Snapshot Barrier中对数据流进行排列对齐:
① Operator从一个incoming Stream接收到Snapshot Barrier n,然后暂停处理,直到其它的incoming Stream的Barrier n(否则属于2个Snapshot的记录就混在一起了)到达该Operator
② 接收到Barrier n的Stream被临时搁置,来自这些Stream的记录不会被处理,而是被放在一个Buffer中。
③ 一旦最后一个Stream接收到Barrier n,Operator会emit所有暂存在Buffer中的记录,然后向Checkpoint Coordinator发送Snapshot n。
④ 继续处理来自多个Stream的记录

(3)、在这个算法中Block Input实际上是有负面效果的,一旦某个input channel发生延迟,Barrier迟迟未到,这会导致Transformation Operator上的其它通道全部堵塞,系统吞吐大幅下降。但是这么做的一个最大的好处就是能够实现Exactly Once。不过Flink还是提供了选项,可以关闭Exactly once并仅保留at least once,以提供最大限度的吞吐能力。
以上是关于Flink容错机制的主要内容,如果未能解决你的问题,请参考以下文章