综合练习:词频统计
Posted 有志气的骚年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了综合练习:词频统计相关的知识,希望对你有一定的参考价值。
1.英文词频统计
下载一首英文的歌词或文章
a = \'\'\'Waking up I see that everything is ok The first time in my life and now it\'s so great Slowing down I look around and I am so amazed I think about the little things that make life great I wouldn\'t change a thing about it This is the best feeling This innocence is brilliant, I hope that it will stay This moment is perfect, please don\'t go away, I need you now And I\'ll hold on to it, don\'t you let it pass you by I found a place so safe, not a single tear The first time in my life and now it\'s so clear Feel calm I belong, I\'m so happy here It\'s so strong and now I let myself be sincere I wouldn\'t change a thing about it This is the best feeling This innocence is brilliant, I hope that it will stay This moment is perfect, please don\'t go away, I need you now And I\'ll hold on to it, don\'t you let it pass you by It\'s the state of bliss you think you\'re dreaming It\'s the happiness inside that you\'re feeling It\'s so beautiful it makes you wanna cry It\'s the state of bliss you think you\'re dreaming It\'s the happiness inside that you\'re feeling It\'s so beautiful it makes you wanna cry It\'s so beautiful it makes you want to cry This innocence is brilliant, it makes you want to cry This innocence is brilliance, please don\'t go away Cause I need you now And I\'ll hold on to it, don\'t you let it pass you by This innocence is brilliant, I hope that it will stay This moment is perfect, please don\'t go away, I need you now And I\'ll hold on to it, don\'t you let it pass you by \'\'\'
将所有,.?!’:等分隔符全部替换为空格
b = \'\'\':.,?!\'\'\' for c in b: news=a.replace(c,\'\')
将所有大写转换为小写
news=news.lower()
生成单词列表
wordList=news.split()
生成词频统计
wordDict = {} wordLSet=set(wordList) for w in wordLSet: wordDict[w]=wordList.count(w) for w in wordList: print(w,wordDict[w])
排序
dictList = list(wordDict.items())
dictList.sort(key=lambda x: x[1],reverse=True)
排除语法型词汇,代词、冠词、连词
exclude={\'the\',\'and\',\'of\',\'to\'}
wordLSet=set(wordList)-exclude
输出词频最大TOP20
for i in range(20): print(dictList[i])
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f = open("xx.txt", "r",encoding=\'utf-8\') news=f.read() f.close() print(news)
2.中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open(\'a.txt\',\'r\',encoding = \'utf-8\')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
import jieba file = open("a.txt", \'r\', encoding="utf-8") news = file.read(); file.close(); sep = \'\'\':。,?!;∶ ...“”\'\'\' for i in sep: news = news.replace(i, \' \'); news_list = list(jieba.cut(news)); news_dict = {} for w in news_list: news_dict[w] = news_dict.get(w, 0) + 1for w in news_dict: print(w, news_dict[w])
排序
dictList = list(news_dict.items()) dictList.sort(key=lambda x: x[1], reverse=True);
排除语法型词汇,代词、冠词、连词
exclude = [\' \', \'\\n\', \'你\', \'我\', \'他\', \'但\', \'了\', \'的\', \'来\', \'是\', \'去\', \'在\', \'上\'] for w in exclude: del (news_dict[w]);
输出词频最大TOP20
for i in range(20): print(dictList[i])
(或把结果存放到文件里)
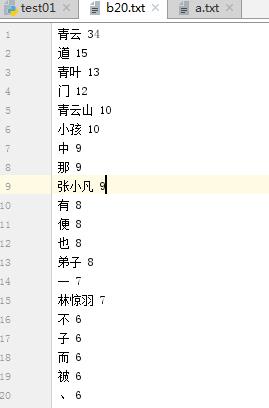
outfile = open("b20.txt","a",encoding=\'utf-8\') for i in range(20): outfile.write(dictList[i][0]+" "+str(dictList[i][1])+"\\n") outfile.close();
将代码与运行结果截图发布在博客上。
以上是关于综合练习:词频统计的主要内容,如果未能解决你的问题,请参考以下文章