中文词频统计
Posted 司徒春燕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文词频统计相关的知识,希望对你有一定的参考价值。
import jieba f = open(\'article.txt\',\'r\',encoding=\'utf-8\') text = f.read() f.close() stri = \'\'\'一!“”,。?;’"\',.、:\\n\'\'\' for s in stri: text = text.replace(s,\' \') wordlist = list(jieba.cut(text)) exclude = {\'你\',\'你们\',\'的\',\'他\',\'了\',\'她\',\'是\',\'在\',\'—\',\'他们\',\'着\',\'把\',\'不\',\'也\',\'我\',\'人\',\'而\', \'与\',\'有\',\'可是\',\'自己\',\'就\',\'又\',\'什么\',\'和\',\'一个\',\' \',\'呢\',\'很\',\'象\',\'一点\',\'都\',\'去\', \'没有\',\'个\',\'上\',\'给\',\'来\',\'还\',\'到\',\'这\',\'要\',\'不是\',\'得\',\'但是\',\'已经\',\'那么\',\'只\',\'因为\',} set = set(wordlist) - exclude dict = {} for key in set: dict[key]=wordlist.count(key) dictlist = list(dict.items()) dictlist.sort(key=lambda x: x[1], reverse=True) f1 = open(\'articleCount.txt\', \'a\',encoding=\'utf-8\') for i in range(20): f1.write(str(dictlist[i])+\'\\n\') print(dictlist[i]) f1.close()
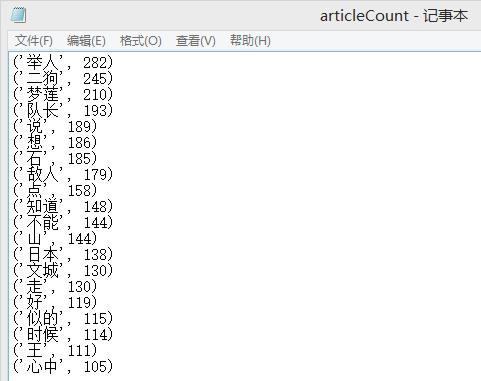
结果截图:

以上是关于中文词频统计的主要内容,如果未能解决你的问题,请参考以下文章