中文词频统计
Posted BennyKuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文词频统计相关的知识,希望对你有一定的参考价值。
下载一长篇中文文章。
从文件读取待分析文本。
news = open(\'gzccnews.txt\',\'r\',encoding = \'utf-8\')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
import jieba
fo = open("xiyouji.txt", "r", encoding=\'utf-8\')
novel = fo.read()
fo.close()
delword = [\'我\', \'他\', \'你\', \'了\', \'那\', \'又\', \'-\', \'\\n\', \',\', \'。\', \'?\', \'!\', \'“\', \'”\', \':\', \';\', \'、\', \'.\', \'‘\', \'’\']
wordDict = {}
wordList = list(jieba.cut(novel))
for i in wordList:
wordDict[i] = wordList.count(i)
for i in delword:
if i in wordDict:
del wordDict[i]
sort = sorted(wordDict.items(), key=lambda item: item[1], reverse=True)
for i in range(20):
print(sort[i])
运行结果:
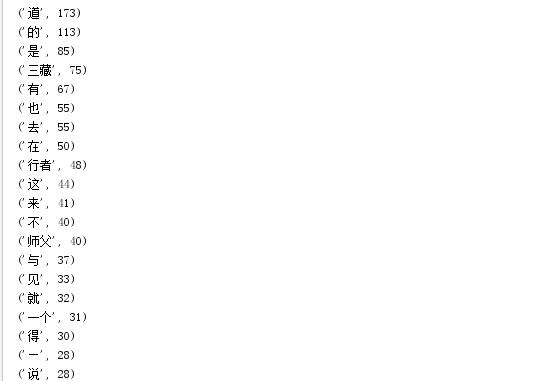
以上是关于中文词频统计的主要内容,如果未能解决你的问题,请参考以下文章