综合练习:词频统计
Posted yinjinxiu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了综合练习:词频统计相关的知识,希望对你有一定的参考价值。
词频统计预处理
下载一首英文的歌词或文章
news = \'\'\' She hangs out every day near by the beach . Havin’ a HEINEKEN fallin’ asleep She looks so sexy when she’s walking the sand Nobody ever put a ring on her hand She is the story the story is she She sings to the moon and the stars in the sky Shining from high above you shouldn’t ask why She is the one that you never forget She is the heaven-sent angel you met Oh, she must be the reason why God made a girl She is so pretty all over the world She puts the rhythm, the beat in the drum She comes in the morning and the evening she’s gone Every little hour every second you live Trust in eternity that’s what she gives She looks like Marilyn, walks like Suzanne Suzanne She talks like Monica and Marianne Monica Marianne She wins in everything that she might do And she will respect you forever just you She is the one that you never forget She is the heaven-sent angel you met Oh, she must be the reason why God made a girl She is so pretty all over the world She is so pretty all over the world She is so pretty She is like you and me Like them like we She is in you and me She is the one that you never forget She is the heaven-sent angel you met Oh, she must be the reason why God made a girl She is so pretty all over the world (She is the one) She is the one (That you never forget) That you never forget She is the heaven-sent angel you met She’s the reason (oh she must be the reason) why God made a girl She is so pretty all over the world (oh...) Na na na na na …. \'\'\'
将所有,.?!’:等分隔符全部替换为空格
sep = \'\'\'.,?!\'\'\' for c in sep: news = news.replace(c,\'\')
将所有大写转换为小写
生成单词列表
wordList = news.lower().split() for w in wordList: print(w)

生成词频统计
wordDict = {}
wordSet = set(wordList)
for w in wordSet:
wordDict[w] = wordList.count(w)
排序
dictList = list(wordDict.items()) dictList.sort(key = lambda x: x[1], reverse=True)
排除语法型词汇,代词、冠词、连词
exclude ={\'she\',\'the\',\'you\',\'a\',\'and\',\'why\',\'that\',\'one\',\'she’s\',\'me\',\'by\',\'when\'}
wordSet = set(wordList)-exclude
for w in wordSet:
wordDict[w] = wordList.count(w)

输出词频最大TOP20
for i in range(20): print(dictList[i])
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f = open(\'news.txt\',\'r\',encoding=\'utf-8\')
news = f.read()
f.close()
print(news)
f = open(\'newscount.txt\',\'a\')
for i in range(20):
f.write(dictList[i][0]+\'\'+str(dictList[i][1])+\'\\n\')
f.close()
2.中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open(\'gzccnews.txt\',\'r\',encoding = \'utf-8\')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20(或把结果存放到文件里)
import jieba
f = open(\'princekin.txt\',\'r\',encoding=\'utf-8\')
princekin = f.read()
f.close()
str1 = \'\'\'“”,。?:、()’!\\n …\'\'\'
exclude = {\'那\',\'你\',\'的\',\'我\',\'一\',\'它\',\'他\',\'这\',\'人\',\'了\',\'啊\',\'呢\',\'唉\'}
jieba.add_word(\'小王子\')
for i in str1:
princekin = princekin.replace(i,\'\')
result = list(jieba.cut(princekin))
wordDict = {}
words = list(set(result)-exclude)
for i in words:
wordDict[i]= result.count(i)
wordList = list(wordDict.items())
wordList.sort(key = lambda x: x[1], reverse=True)
print(wordList)
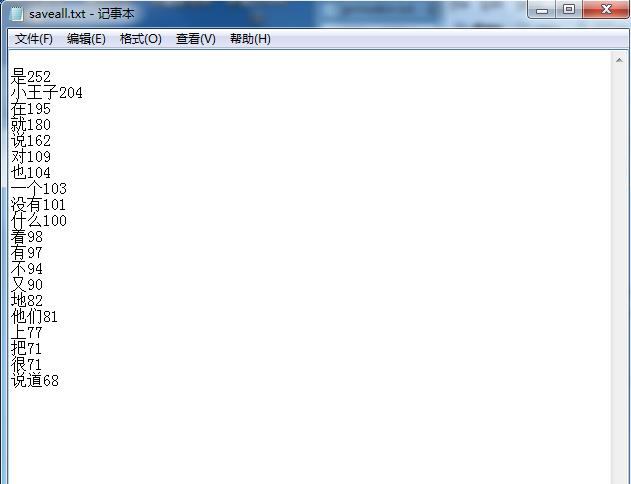
f = open(\'saveall.txt\',\'a\',encoding=\'utf-8\')
for i in range(20):
f.write(wordList[i][0] + \'\' + str(wordList[i][1]) + \'\\n\')
f.close()
以上是关于综合练习:词频统计的主要内容,如果未能解决你的问题,请参考以下文章