综合练习:词频统计
Posted 标弟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了综合练习:词频统计相关的知识,希望对你有一定的参考价值。
综合练习
词频统计预处理
1、下载一首英文的歌词或文章
将所有,.?!’:等分隔符全部替换为空格
将所有大写转换为小写
生成单词列表
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
输出词频最大TOP20
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f=open("file.txt","r") news=f.read() f.close() sep=\'\'\',().;--\'\'\' exclude={\'the\',\'to\',\'and\',\'of\',\'in\',\'for\',\'on\',\'a\',\'when\',\'as\',\'not\',\'with\',\'that\'} for c in sep: news = news.replace(c,\'\') wordList=news.lower().split() wordDict={} wordSet=set(wordList)-exclude for w in wordSet: wordDict[w]=wordList.count(w) dictList = list(wordDict.items()) dictList.sort(key=lambda x:x[1],reverse=True) for i in range(20): print(dictList[i])

2、下载一长篇中文文章。
从文件读取待分析文本。
news = open(\'gzccnews.txt\',\'r\',encoding = \'utf-8\')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
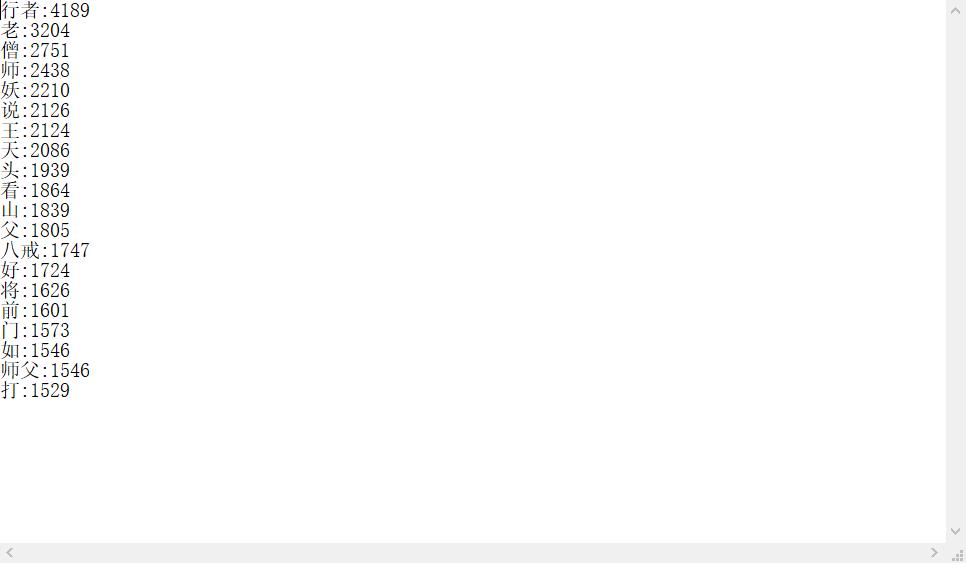
输出词频最大TOP20(或把结果存放到文件里)
import jieba f = open(\'gzccnews.txt\',\'r\',encoding = \'utf-8\') story=f.read() f.close() jieba.add_word(\'行者\') jieba.add_word(\'八戒\') jieba.add_word(\'师父\') sep=\'\'\',。‘’“”:;()!?、《》 \'\'\' exclude={\'的\',\'\\n\',\'曰\',\'之\',\'不\',\'人\', \'行\',\'者\',\'来\',\'德\',\'有\',\'于\',\'下\',\'兵\',\'此\', \'玄\',\'公\',\'见\',\'为\',\'何\',\'中\',\'而\',\'可\',\'吾\', \'出\',\'也\',\'以\',\'与\',\'上\',\'后\',\'今\',\'其\',\'去\', \'日\',\'明\',\'言\',\'道\',\'了\',\'那\',\'我\',\'是\',\'他\', \'个\',\'你\',\'得\',\'这\',\'在\',\'子\',\'里\',\'行\',\'者\', \'却\',\'大\',\'又\',\'就\',\'八\',\'戒\',\'三\',\'着\',\'只\', \'儿\',\'一\',\'只\',\'把\',} for c in sep: story = story.replace(c,\'\') tem=list(jieba.cut(story)) wordDict={} words=list(set(tem)-exclude) for w in range(0,len(words)): wordDict[words[w]]=story.count(str(words[w])) dictList = list(wordDict.items()) dictList.sort(key=lambda x:x[1],reverse=True) f = open(\'Count.txt\', \'a\',encoding="utf-8") for i in range(20): f.write(dictList[i][0] + \':\' + str(dictList[i][1]) + \'\\n\') f.close()
以上是关于综合练习:词频统计的主要内容,如果未能解决你的问题,请参考以下文章