综合练习:词频统计
Posted cgq丶虾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了综合练习:词频统计相关的知识,希望对你有一定的参考价值。
f = open(\'test.txt\',\'r\')
news = f.read()
f.close()
sep = \'\'\'.,\'?!:"\'\'\'
exclude = {\'the\',\'and\',\'to\',\'a\',\'of\',\'was\',\'on\',\'with\',\'i\',\'s\',\'is\',\'were\',\'that\',\'back\',\'at\',\'little\',\'have\'}
for w in sep:
news = news.replace(w,\' \')
wordList = news.lower().split()
wordDict = {}
\'\'\'
for v in wordList:
wordDict[v] = wordDict.get(v, 0)+1
for v in exclude
del( wordDict[v])
\'\'\'
wordset = set(wordList) - exclude
for v in wordset:
wordDict[v] = wordList.count(v)
dictList = list(wordDict.items())
dictList.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
print(dictList[i])
f = open(\'newscount.txt\',\'a\')
for i in range(25):
f.write(dictList[i][0]+\' \'+str(dictList[i][1])+\'\\n\')
运行结果:

中文统计
import jieba
f = open(\'text.txt\', \'r\', encoding = \'utf-8\')
news = f.read()
f.close()
sep=\'\'\',。‘’“”:;()!?、《》 \'\'\'
exclude={\'我\', \'在\', \'不\', \'一\', \'了\', \'那\', \'是\', \'来\', \'他\', \'个\', \'行\', \'你\', \'的\',
\'者\',\'有\',\'\\n\',\'-\',\'出\',\'这\',\'时\',\'没\',\'她\',\'到\',\'上\',\'们\',\'会\',\'着\',\'说\',\'要\'
, \'为\',\'过\',\'看\',\'得\',\'里\',\'克\',\'去\',\'想\',\'好\',\'天\',\'小\',\'后\',\'地\',\'么\',\'都\'
, \'还\',\'以\',\'对\',\'能\',\'大\',\'也\',\'很\',\'而\',\'然\',\'下\',\'但\',\'吕\',\'把\',\'开\',\'从\'
, \'让\',\'就\',\'一个\',\'可\',\'点\',\'跟\',\'样\',\'向\',\'事\',\'起\',\'中\',\'面\'}
for c in sep:
news = news.replace(c,\' \')
wordList=list(jieba.cut(news))
wordDict={}
words=list(set(wordList)-exclude)
for w in range(0,len(words)):
wordDict[words[w]]=news.count(str(words[w]))
dictList = list(wordDict.items())
dictList.sort(key=lambda x:x[1],reverse=True)
f = open(\'new.txt\', \'a\',encoding="utf-8")
for i in range(20):
f.write(dictList[i][0] + \':\' + str(dictList[i][1]) + \'\\n\')
f.close()
结果:
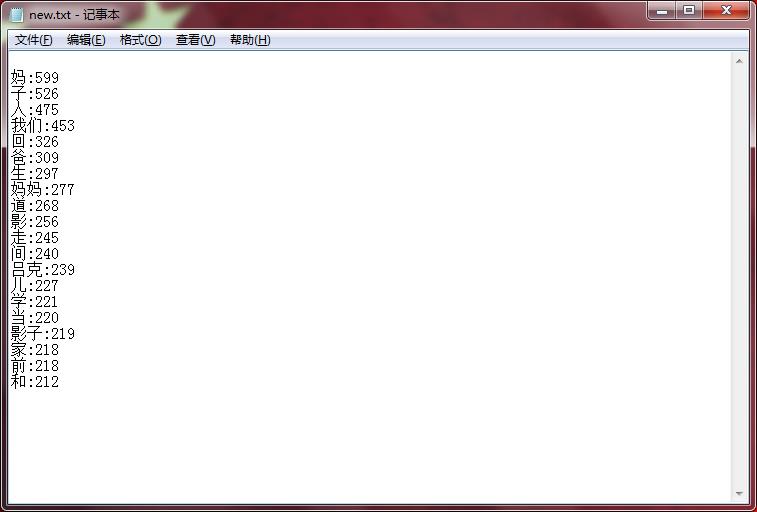
以上是关于综合练习:词频统计的主要内容,如果未能解决你的问题,请参考以下文章