Day2 列表,元组,集合,字典
Posted 大橡皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day2 列表,元组,集合,字典相关的知识,希望对你有一定的参考价值。
一,列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素.
list=[\'alex\', \'jack\', \'chen\', \'shaoye\'] #创建一个列表.
特性:
1.可存放多个值
2.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序.
3.索引位置的值是可以被修改的.
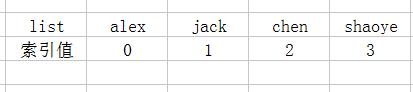
1 # 列表的操作 2 # 切片 3 list[0] #获取列表第一个元素 4 list[0:3] # 获取列表1-4之间的元素,不包括第4个. 5 list[-1] # 取列表最后一个元素 6 # 索引 7 list.index(\'chen\') # 获取chen在列表中的索引位置. 8 # 追加 9 list.append(\'nick\') # 添加一个元素到列表的尾部 10 # 删除 11 list.remove(\'alex\') # 删除alex这个元素. 12 list.clear() # 清空列表 13 list.pop() # 默认删除列表中最后一个元素,并返回该元素. 14 # 插入 15 list.insert(1, \'maya\') # 在列表1的位置,插入一个元素. 16 # 修改 17 list[1] = \'junkec\' # 把索引值是1的元素修改成junkec 18 # 统计次数 19 list.count(\'shaoye\') # 统计shaoye在列表中出现的次数.
二,元组
定义:tu = (1,2,3) 定义一个元组,元素用逗号隔开.
tup = (1,2,3,4,5,6,5,4,3) # 定义一个元组
特性:
1.元组里的元素不可变.不能被修改.
2.可以存放多个值.
3.元组的下标从0开始.
作用:
由于元组具有不可变的性质,可以用元组来定义连接数据库等操作.
# 元组的操作 # 切片 tup[0] # 获取元组第一个元素值. tup[0:3] #获取1-4之间的元素值,不包括第四个. # 连接元组,由于元组不可修改.我们无法修改元素值.但是可以把2个元组合成一个. tup1 = (1,2,6) tup2 = (\'a\', \'b\', \'c\') tup3 =tup1 + tup2 #删除整个元组 del tup
三,字典
定义:{\'k1\':\'v1\', \'k2\':\'v2\', \'k3\':\'v3\'} # k1和v1构成一个键值对,键和值用:分开,键值对之间使用逗号隔开.
特性:
1.键的类型必须是可hash且为不可变的数据类型,必须唯一
2.可以存放多个值,值可以不唯一.
3.结构是key-value
4.无序.字典是没有顺序的.
dic = {\'k1\':\'v1\', \'k2\':\'v2\', \'k3\':\'v3\'}
dic2 = {\'a\':\'1\', \'b\':2}
# 增加
dic[\'k4\'] = \'v4\' # 增加一个k4的键值对.
print(dic)
# {\'k1\': \'v1\', \'k2\': \'v2\', \'k3\': \'v3\', \'k4\': \'v4\'}
# 取键,键值,键值对
dic.keys() # 获取字典中所有的key以列表的形式.
print(dic.keys())
# dict_keys([\'k1\', \'k2\', \'k3\', \'k4\'])
dic.values() # 获取字典中所有的value以列表的形式.
print(dic.values())
dic.items()
print(dic.items()) # 获取字典中所有的key-value以元组的形式.
# dict_items([(\'k1\', \'v1\'), (\'k2\', \'v2\'), (\'k3\', \'v3\'), (\'k4\', \'v4\')])
# 删除
dic.pop(\'k1\') # 删除指定的键值对.如果键值对不存在,报错.
print(dic)
# {\'k2\': \'v2\', \'k3\': \'v3\', \'k4\': \'v4\'}
dic.clear() # 清空字典
# 修改
dic[\'k1\'] = \'kkk\' #修改k1的键值为kkk
dic.update(dic2) # 将dic2的键值对添加到dic中.
print(dic)
# {\'k1\': \'v1\', \'k2\': \'v2\', \'k3\': \'v3\', \'a\': \'1\', \'b\': 2}
# 查看
dic.get(\'k5\',\'nothing\') # 获取k5的键
# nothing
dic[\'k1\'] # 如果key不在字典中,会报错.
for k in dic.items(): # 输出所有的键值对.
print(k)
\'\'\'
(\'k1\', \'v1\')
(\'k2\', \'v2\')
(\'k3\', \'v3\') \'\'\'
for k in dic.keys(): #输出所有的key
print(k)
\'\'\'
k1
k2
k3
\'\'\'
for k in dic: #输出所有的key
print(k)
\'\'\'
k1
k2
k3
\'\'\'
四,集合
定义:{1,2,3,4} 定义一个集合.也是使用花括号.看上去和字典类型差不多.不要弄混淆了.
特性:
1.去重.
2.关系运算.
3.无序.因为无序特性的存在,所以{2,4,5,6,7}和{4,6,2,5,7}是同一个集合.
1 set = {\'alex\',\'ago\',\'marry\',\'jack\',\'lucy\'} 2 set1 = {\'lili\',\'tiger\',\'eric\',\'ago\',\'jack\'} 3 #集合的运算关系 4 # 交集,取即在set中又在set1的元素. 5 print(set.intersection(set1)) # 获取2个集合的交集 6 print(set&set1) # 使用连接符&也可以表示交集. 7 #并集,合并2个集合 8 print(set.union(set1)) 9 print(set|set1) #使用管道符|求并集. 10 # 差集 11 print(set.difference(set1)) # 取不在set1中的元素. 12 print(set-set1) 13 print(set1.difference(set)) # 取不在set中的元素 14 print(set1-set) 15 # 对称差集,只在set或set1里的元素 16 print(set.symmetric_difference(set1)) 17 print(set^set1) 18 # 集合判断 19 print(set.isdisjoint(set1)) #判断2个集合是不是不相交!注意是判断不相交 !返回False 表示相交,返回True表示不相交 20 print(set.issubset(set1)) # 判断集合是不是被其他集合所包含 21 print(set.issuperset(set1)) #判断集合是不是包含其他集合 22 #增加 23 set.add("mayun") # 向集合中添加一个元素. 24 print(set) 25 # {\'marry\', \'ago\', \'alex\', \'jack\', \'mayun\', \'lucy\'} 26 set.update(\'china\') # 增加集合序列,把传入的字符串,拆分成单个,然后添加到集合. 27 print(set) 28 # {\'c\', \'jack\', \'i\', \'lucy\', \'ago\', \'alex\', \'mayun\', \'n\', \'h\', \'a\', \'marry\'} 29 #删除 30 set.discard(\'alex\') # 删除alex这个元素,如果元素不存在集合中,不会报错. 31 print(set) 32 # {\'n\', \'jack\', \'ago\', \'lucy\', \'mayun\', \'h\', \'c\', \'i\', \'a\', \'marry\'} 33 set.remove(\'lucy\') #删除一个元素,如果元素不在集合中,报keyerror错误. 34 print(set) 35 # {\'n\', \'ago\', \'c\', \'jack\', \'a\', \'mayun\', \'i\', \'marry\', \'h\'} 36 set.pop() #由于集合无序,所以被删除的元素是随机的. 37 print(set) 38 # {\'lucy\', \'jack\', \'marry\', \'ago\'} 39 set.clear() #清空集合 40 print(set) 41 # set() 42
以上是关于Day2 列表,元组,集合,字典的主要内容,如果未能解决你的问题,请参考以下文章