集合类关系
Posted 千彧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集合类关系相关的知识,希望对你有一定的参考价值。
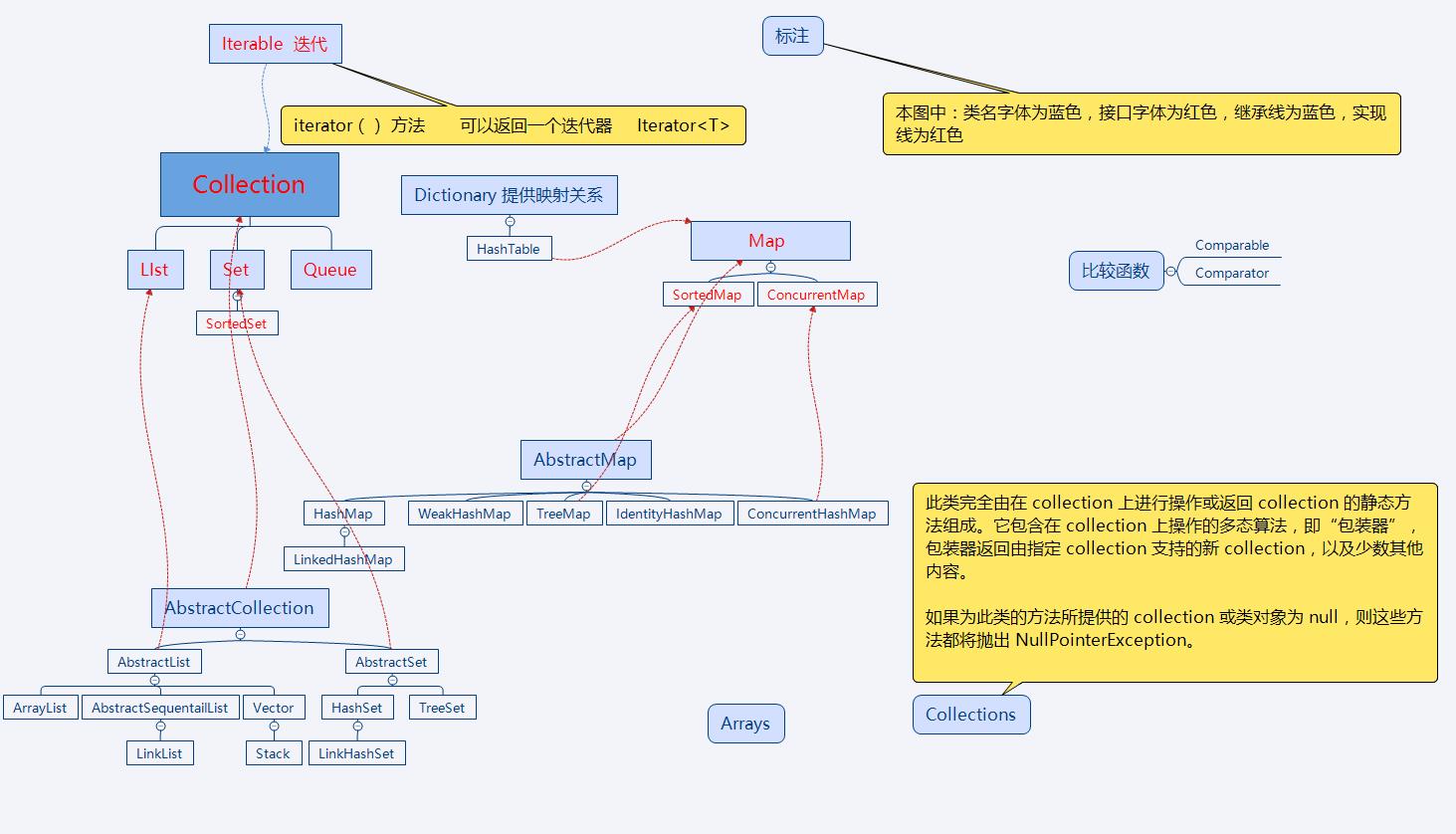
Iterator,所有的集合类,都实现了Iterator接口,可以获得Iterator(迭代器),这是一个用于遍历集合中元素的接口,主要包含以下三种方法:
1.hasNext()是否还有下一个元素。
2.next()返回下一个元素。
3.remove()删除当前元素。
一、主要接口简介:
1、Set 无序,不能包含重复元素,
2、List有序,可以包含重复元素,提供了按位索引
3、Map :包含了key-value对 ,key不能重复,value可以重复,根据键得到值,对map集合遍历时先得到键的set集合,对set集合进行遍历,得到相应的值
二、遍历
1、Iterator: 迭代输出,使用最多
2、ListIterator:是Iterator的子接口,专门用于输出List
3、foreach
4、for循环
三、Map
1、HashMap 最常用的Map 遍历时取得数据顺序随机,键对象不可重复。
2、Hashtable 是Hashtable的线程安全版,支持线程同步,不允许记录键或值为null,同时效率较低。
3、ConcurrentHashMap 线程安全,并且锁分离,ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
4、LinkedHashMap 保存了记录的插入顺序, 遍历有序,遍历时比HashMap慢,有HashMAp全部特性
5、TreeMap 实现 SortMap接口, 能够把记录按键排序,默认升序,也可指定比较器,不允许key为空,非同步
四、map遍历
1、keySet()
先将键值存入set,在遍历set ,根据键值取值。
1 //先获取map集合的所有键的set集合,keyset() 2 Iterator it = map.keySet().iterator(); 3 //获取迭代器 4 while(it.hasNext()){ 5 Object key = it.next(); 6 System.out.println(map.get(key)); 7 }
2、entrySet()
Set<Map.Entry<K,V>> entrySet() 把(key-value)作为一个整体,一对一地存放到Set集合当中。Map.Entry表示映射关系。
1 //将map集合中的映射关系取出,存入到set集合 2 Iterator it = map.entrySet().iterator(); 3 while(it.hasNext()){ 4 Entry e =(Entry) it.next(); 5 System.out.println("键"+e.getKey () + "的值为" + e.getValue()); 6 }
五、主要实现类区别
1、ArrayList和LinkList
ArrayList用于查询较多,LinkList用于增删改较多
2、Vector和ArrayList(都是数组方式存储)
1)Vector线程同步,ArrayLIst线程异步,不考虑线程ArrayList效率较高。
2)如果结合中的元素,数目大于目前集合长度,Vector增长率为目前的100%,ArrayList为50%,如果在集合中使用数据量比较大的数据,用Vector有优势。
3、HashMap和TreeMap
1)HashMap通过hashcode查找,TreeMap元素保持固定顺序,如有需要得到有序结果,使用TreeMap
2)在Map中插入、删除、定位元素,使用HashMap
4、HashMap、HashTable和ConcurrentHashMap
1)HashMap允许键和值是null(只允许一个键是null),而HashTable不允许键或者值是null。
2)HashMap不是线程同步,适合单线程,HashTable是线程同步,适合多线程。
3)HashMap提供了可供迭代的键的集合,因此HashMap是快速失败的,HashTable提供了对键的列举(Enumeration)
4)HashMap是非线程安全的,HashTable是线程安全的, 因为线程安全问题,HashMap效率比HashTable要高。线程安全主要在与put() 函数,当向map里添加数据达到阈值时,map会进行自动的扩充,而扩充的机制在于先建立一个新的table在将原本的数据进行填入,而此时如果有多个线程进行put(),便会产生多个newTable,先生成的table会被覆盖。而HashTable使用Synchronized标记put方法解决线程问题,而且为了保证数据同步,get方法甚至都会加锁,造成效率低下。一般认为HashTable是一个遗留的类,一般不推荐使用,因为遗留内部很多没有优化,即使在多线程环境下,也有同步的ConcurrentHashMap代替,没必要用。
ConcurrentHashMap 在内部建立分段Segment, 将数据进行分段存储。修改为对某一段数据进行加锁,其他线程仍然可以处理其他的数据。在查找数据时采用重哈希分别来确定段位和数据位。
以上是关于集合类关系的主要内容,如果未能解决你的问题,请参考以下文章