中文编码问题
Posted 机械狂魔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文编码问题相关的知识,希望对你有一定的参考价值。
1,了解为什么java内存编码用utf-16,网络传输用utf-8
2,java web的编码问题
URL httpHeader POST表单 HttpBody
JS编码
其他编码
3,常见问题分析
中文编程看不懂字符
一个汉字变成一个问号
一个汉字变成两个问号
一、为什么要编码?
计算机储存信息的最小单元是1个字节,能表示的字符范围是0-255
我们要表示的字符号太多,1个字节远远不够,因此要有一个新的类型char,从char到byte必须编码。
二、常见编码格式有哪些?
1,ASCII码
用一个字节的低7位表示,00-7F(即0-127)范围,0-31是回车、换行、删除等控制字符,32-126是打印字符,可以用键盘输入并显示出来。
2,ISO-8856-1
ASCII码共128个字符是远远不够的,ISO组织又制定了这个标准。以单字节表示,共256个字符。对于英文字符是足够了。
3,GB2312
中文全称为 “信息交换用汉字编码字符集” ,双字节的。GB2312 共收录有 7445 个字符,其中简化汉字 6763 个,字母和符号 682 个
4,GBK
全称“汉字内码扩展规范”,为了扩展GB2312,故兼容GB2312,能表示21003个汉字。
5,GB18030
是我国强制标准,但实际应用系统并不多。
6,UTF-16
Unicode,是ISO视图创建一个全新的超语言字典,可以互相翻译全世界所有语言。UTF-16定义了Unicode在计算机的存取方法,用两个字节表示Unicode的转化格式,两个字节是16位,故叫UTF-16。UTF-16表示字符很方便,简化了字符串操作,因此Java以UTF-16作为内存的字符存储格式。
7,UTF-8
UTF-16统一用量个字节表示一个字符,虽然表示很简单方便,但缺点是很大一部分字符可以用一个字节表示,缺占了两个字节,存储空间上放大了一倍。在网络带宽有限的情况下,增大网络流量。UTF-8采用变长技术,不同类型的字符可以由1-6个字节组成。故网络编码多用UTF-8
编码格式对比,GB2312与GBK,GBK范围更大,选GBK。
UTF-8与UTF-16,UTF-16的编码效果高,转换简单,适合在内存和磁盘中操作,JAVA内存编码就是UTF-16。
对于网络传输,容易损坏字节流,加上传输量因素,选择UTF-8更好。编码效率而言,GBK<UTF-8<UTF-16,故中文编码的网络传输采用UTF-8最理想。
三、JAVA中要编码的场景
1,磁盘IO操作
文件读写类,FileOutputStream和FileInputStream,只要统一设置编解码字符集,一般不会出现乱码问题。要注意的是有些应用程序不指定编码格式,中文环境中会用操作系统默认编程,换成其他操作系统环境可能会出问题。强烈建议指定编码格式。
2,内存操作中
String和byte[]的互相转换,设置统一编解码格式也不会出现问题。
3,Java Web中的编码,这个问题是重中之重
从使用中文角度来说,有IO的地方就有编码。网络传输中是以字节为单位的,所有数据都要能被序列化成字节。
(1)URL编码
从浏览器发情一次HTTP请求,存在编码的地方是URL、Cookie、Paramiter
完整URL:http://localhost:8080/oa/base/userServlet/张三.do?name=张三
Domain:localhost
port:8080
ContextPath:oa
ServletPath:base/userServlet
PathInfo:张三.do
QueryString:name=张三
URI部分:oa/base/userServlet/张三.do
以谷歌浏览器为例,F12打开调试,可以看到是UTF-8编码的。
chrome下无论请求地址和参数,均经过utf-8编码;但其他浏览器不一定是这样,比如IE是GBK编码。
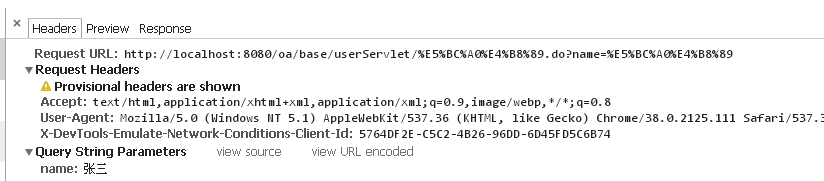
如360浏览器,请求地址是这样,PathInfo是GBK编码,QueryString是utf-8编码.可能你的结果不同,但是PathInfo和QueryString编码不同是存在的。
http%3A%2F%2Flocalhost%3A8080%2Foa%2Fbase%2FuserServlet%2F%D5%C5%C8%FD%2Edo%3Fname%3D%25E5%25BC%25A0%25E4%25B8%2589
编码和解码不是程序中能完全控制的,所以要尽量避免在URL中使用非ASCII字符。最好在服务端设置。以tomcat为例
在tomcat的server.xml下的connetor属性中增加URIEncoding或者useBodyEncodingForURI属性,如果不设置则tomcat按默认ISO-8856-1来解码。
(2)HTTP Header编码
浏览器发起 http请求,Header中cookie等参数也存在编码问题。tomcat从byte到char转化同样默认是ISO-8856-1。
(3)POST表单的编解码
在页面点提交按钮时,先根据ContentType对表单填写项编码,在服务端同样用这个编码来解码,一般不会有问题。这个编码个是我们程序可以控制的,如rquset.setCharacterEncoding(charset)。如果不设置,按系统默认编码来解析。包括上传文件也是字节流。
(4)HTTP BODY
这些内容通过Response返回给客户端浏览器。也是先经过编码,再到浏览器解码。可以通过response.setCharacterEncoding(charset)设置,浏览器客户端根据html中的 <meta http-equiv=content-type content="text/html; charset=utf-8">来解码
4,Js中的编码
如果外部js文件与当前页面编码不一致,可能会出现编码问题。所以统一引入 js文件时加编码
<script type ="text/javascript" src="resource/js/ueditor/ueditor.config.js" charset="utf-8" ></script>
js发起一步调用的URL也受浏览器影响,也要encodeURI()这样的函数来UTF-8编码,彻底解决编码问题
5,Js编码,后台java解码
自然全部UTF-8
6,其他
开发环境IDE,设置文件的编码格式。 xml 设置, jsp contentType="text/html; charset=UTF-8"
四、常见问题分析
1,一个汉字变成两个乱码字符
字节数没丢,说明编码没错可能是GBK,解码用了ISO-8856-1。
2,每个汉字变成一个问号
如:"天气很好" 变成 "? ? ? ?"。编码时字节丢失,使用了ISO-8856-1,码值为3F,ISO-8856-1解码时都变成3F对应的?号
3,一个汉字变成两个问号
如:"天气很好" 变成 "? ? ? ? ? ? ? ?"这种比较复杂,中文经过多次编码,有一次编码或解码使用了ISO-8856-1。要每个编解码环节仔细查看。
4,国际化问题
首先要用支持多语言的UTF-8编码,又一个使用UTF-8的必要性。国际化有springi18见其他相关文章。
以上是关于中文编码问题的主要内容,如果未能解决你的问题,请参考以下文章