K-均值算法(数据挖掘无监督学习)
Posted 如许之秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K-均值算法(数据挖掘无监督学习)相关的知识,希望对你有一定的参考价值。
一、无监督学习
1、聚类:是一个将数据集中在某些方面相似的数据成员进行分类组织的过程。因此,一个聚类就是一些数据实例的集合。聚类技术经常被称为无监督学习。
二、K-均值聚类
1、k—均值算算法:是发现给定数据集k个簇的算法
2、步骤:
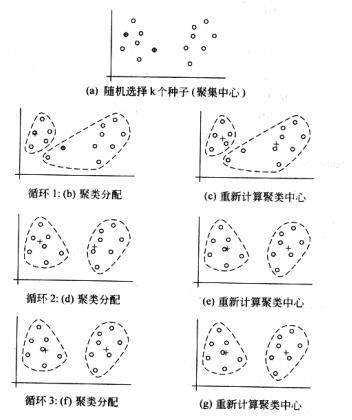
1)、随机选取k个数据点作为初始的聚类中心(要求发现k个簇)。
2)、把每个数据点分配给距离它最近的聚类中心(对图中的所有点求到这K个种子点的距离,假如点P离种子点S最近,那么P属于S点群。)
3)、重新确定聚类中心(x,y),一旦全部的数据点都被分配,每个聚类的聚类中心会更具现有数据点重新计算。x = (x1+x2+……xn)/n,y = (y1+y2+……yn)/n。
4)、2)3)过程不断重复,知道满足一下三个终止(收敛)条件:
a、满足重复次数,比如要求循环执行五十次,第五十一次停止。
b、没有聚类中心再次发生变化。
c、误差和(SSE)局部最小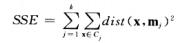 。
。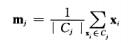

3、伪代码 :
1 Algorithm K-means(k,D) 2 choose k data points as the initial centroids(cluster centers) 3 repeat 4 for each data point x->D do 5 compute the distance from x to each centroid; 6 assign x to the closest centroid 7 endfor 8 re-computer the centroid using the current cluster memberships 9 until the stopping criterion
以上是关于K-均值算法(数据挖掘无监督学习)的主要内容,如果未能解决你的问题,请参考以下文章