(1)GitHub项目地址
https://github.com/AnotherLZ/SoftwareTesting/tree/master
(2)PSP表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planing | 计划 | 30 | 30 |
| ·Estimate | ·估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 600 | 850 |
| ·Analysis | ·需求分析(包括学习新技术) | 40 | 60 |
| ·Design Spec | ·生成设计文档 | 20 | 20 |
| · Design Review | 设计复审 (和同事审核设计文档 | 15 | 15 |
| · Coding Standard | ·代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| ·Design | ·具体设计 | 30 | 30 |
| ·Coding | ·具体编码 | 300 | 500 |
| ·Code Review | ·代码复审 | 60 | 60 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 150 | 210 |
| ·Test Report | ·测试报告 | 60 | 120 |
| ·Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 780 | 1090 |
(3)解题思路
这次的题目分为基础功能、拓展功能和高级功能几部分。对题目进行简略的分析后,我觉得可以先着手解决基础功能,后面两部分的要求可以在此基础上继续进行实现。基础功能要求对一个文件进行字符统计,单词统计和行数统计,以及将结果输出到指定目录。这实现起来其实并不难,用BufferedReader这个类读文件,然后逐个字符进行分析就可以了。
对于拓展功能,要在前面的基础上加上递归处理目录文件、统计单词时忽略指定stopList.txt中的单词进行计数和对行进行分类——代码行/空行/注释行这样的处理。忽略停用词表这个只要在前面的基础上,先获取 停用词,再统计单词,统计过程中有属于停用词的单词不计数。行分类只要逐行进行分析即可。但是对于递归处理文件这个功能,我编码调试了很久,仍然是有bug。跟同学讨论后发现其实我的思路也是正确的,可能在实现的编码方式上有问题,总是抛出NullPointerException这类的错误。调试了许久之后我,,,,放弃了这一个功能的实现,可能是前面的功能实现代码太乱了,我自己也不懂怎么整理了.......
最后,高级功能,因为时间和精力还有能力等各方面原因,也没有实现。
(4)程序设计实现过程
主要是对统计字符、统计单词、统计行数这三个功能的实现,分别对应characterCount()、wordCount()和lineCount()函数。其余的对此加以调用或修改即可。
(5)代码说明
基础功能中统计字符的函数countCharacte():
public int countCharacter(String fileName){ //统计字符数);
File file=new File(fileName);
if(!file.exists()){
return 0;
}
int count=0;
InputStream inputStream=null;
try{
inputStream=new FileInputStream(file);
int temp=0;
while((temp=inputStream.read())!=-1){
if(temp!=13 && temp!=10) //把回车和换行符排除掉
count++;
}
inputStream.close();
}catch(IOException e){
e.printStackTrace();
}
characterCount=count;
//System.out.println(fileName+",字符数:"+characterCount);
writeC(fileName, resultFile);
return characterCount;
}
统计单词的函数wordCount():
public int countWord(String fileName){ //统计单词数
File file=new File(fileName);
if(!file.exists()){
return 0;
}
int count=0;
BufferedReader reader=null;
try{
reader=new BufferedReader(new FileReader(file));
int pre=10;
int temp=0;
while((temp=reader.read())!=-1){
if(temp==44 || temp==32 || temp==10 || temp==13){ //如果遇到空格或者逗号
if(pre!=10 && pre!=13 && pre!=44 && pre!=32){ //判断前一个字符是不是空格、回车、换行、逗号
count++;
}
}
pre=temp;
}
}catch(IOException e){
e.printStackTrace();
}
wordCount=count;
System.out.println(fileName+",单词数:"+wordCount);
writeW(fileName, resultFile);
return wordCount;
}
统计行数的函数lineCount():
public int countLine(String fileName){ //统计行数
File file=new File(fileName);
if(!file.exists()){
return 0;
}
int count=0;
BufferedReader reader=null;
try{
reader=new BufferedReader(new FileReader(file));
while(reader.readLine()!=null){
count++;
}
reader.close();
}catch(IOException e){
e.printStackTrace();
}
lineCount=count;
//System.out.println(fileName+",行数:"+lineCount);
writeL(fileName, resultFile);
return lineCount;
}
主流程处理函数,传入的参数commanList是来自命令行的参数
public void doWork(ArrayList<String> commandList){
if(commandList.contains("-s")){ //这个是递归处理文件。。。。。还没写好
commandList.remove("-s");
sFlag=true;
}
if(commandList.contains("-e")){ //如果包含-e,获取停用词表
eFlag=true;
int index=commandList.indexOf("-e");
stopList=commandList.get(index+1);
commandList.remove(index); //删除 -e
commandList.remove(index); //删除 stoplist.txt
}
if(commandList.contains("-o")){ //包含-o则指定输出文件
oFlag=true;
int index=commandList.indexOf("-o");
output=commandList.get(index+1);
commandList.remove(index);
commandList.remove(index);
}
if(commandList.size()==0){
System.err.println("errer");
System.exit(0);
}
if( batchFlag )
file_name=commandList.get(commandList.size()-1); //如果不是批量处理就获取文件名
if(sFlag && batchFlag){ //如果要进行批量处理
batchFlag=false;
batchProcessing(file_name, "", commandList);
}
else{
if(commandList.contains("-c")){ //统计字符并写到result.txt
cFlag=true;
countCharacter(file_name);
}
if(commandList.contains("-w")){ //统计单词数
wFlag=true;
//System.out.println("wwwwww");
countWord(file_name);
}
if(eFlag){ //忽略停用表统计单词
countWordWithS(file_name, stopList);
}
if(commandList.contains("-l")){ //统计行数
lFlag=true;
countLine(file_name);
}
if(commandList.contains("-a")){ //行分三类
aFlag=true;
differentLine(file_name);
putLine(resultFile);
}
if(oFlag){ //如果指定了输出文件
if(cFlag)
writeC(file_name, output);
if(wFlag || eFlag)
writeW(file_name, output);
if(lFlag)
writeL(file_name, output);
if(aFlag)
putLine(output);
//writeFile(file_name, output);
}
}
}
其余详细完整的代码可前往GitHub查看
(6)测试设计流程
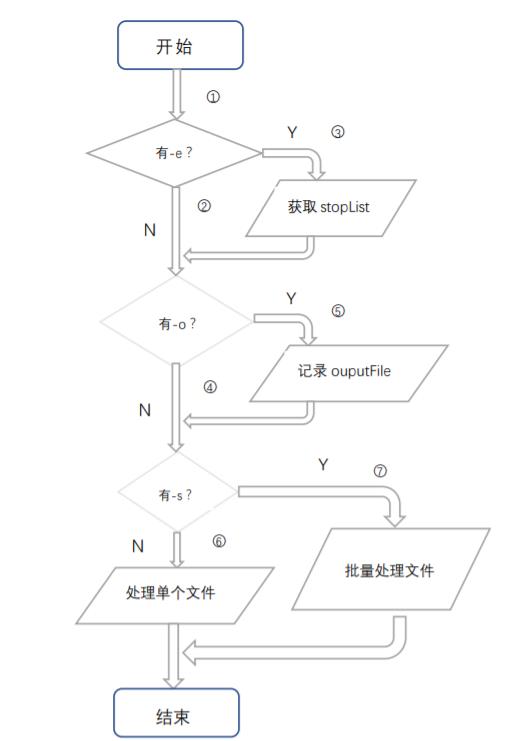
测试用例如下:
| 用例 | 说明 | 路径 |
|---|---|---|
| wc.exe -c file.c | 统计file.c中的字符数 | 1-2-4-6 |
| wc.exe -c -w -l file.c | 同时统计file.c中的字符数、单词数和行数 | 1-2-4-6 |
| wc.exe -w -l file.c -o outputFile.txt | 统计file.c中的单词数和行数,并将结果输出到outputFile.txt中 | 1-2-5-6 |
| wc.exe -a file.c -e stopList.txt -o outputFile.txt | 统计file.c中的代码行/空行/注释行,统计file.c中除stopList.txt中的单词外的单词数,最后将结果输出到outputFile.c中 | 1-3-5-6 |
| wc.exe -s -w -c -l *.c -o outputFile.txt | 批量处理当前目录及子目录中所有的.c文件,并将结果输出到outputFile.txt中 **此功能并未实现 | 1-2-5-7 |
(7)参考文献
[1]http://www.cnblogs.com/math/p/se-tools-001.html
[2]https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000