wordcount
Posted 海弢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了wordcount相关的知识,希望对你有一定的参考价值。
GitHub地址:https://github.com/ht-insatiable/word-count
1.psp表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
| planning | 计划 | 10 | 10 |
| estimate | 估计这个任务需要多久 | 10 | 20 |
| development | 开发 | ||
| analysis | 需求分析(包括学习新技术) | 40 | 60 |
| design spec | 生成设计文档 | 60 | 80 |
| design review | 设计复审(和同事审核设计文档) | 20 | 30 |
| coding standard | 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| design | 具体设计 | 180 | 300 |
| coding | 具体编码 | 240 | 500 |
| code review | 代码复审 | 40 | 50 |
| test |
测试(自我测试,修改代码,提交测试) |
100 | 180 |
| reporting | 报告 | 90 | 120 |
| test report | 测试报告 | 20 | 20 |
| size measurement | 计算工作量 | 20 | 20 |
| postmortem&process improvement plan | 事后总结,并提出过程改进计划 | 30 | 40 |
| 合计 | 870 | 1440 |
2.解题思路
开始看到题目首先是分析需求,开始觉得基本功能问题不大,扩展功能需要多去思考一下。于是开始查找在Java中计算字符的思路和不同方法【1】,根据需求进行不同的尝试和调整。运用面向对象的思想将所要处理的事物抽象分为三个类,分别为counter类(解析控制台传来的参数,根据相应参数完成获取待处理文件,完成预处理为统计文件做准备件的操作),stat类(作为统计量,针对单词字符提供统计的方法),test类(作为测试),进行设计后开始具体编码。
3.程序设计实现过程
运用面向对象的思路来抽象对象
类:

counter:解析控制台传来的参数,根据相应参数完成获取待处理文件,完成预处理为统计文件做准备文件的操作
stat:作为统计量,针对单词字符提供统计的方法
test:作为测试
函数:
public Counter(String[] args) throws IOException 构造函数
private void parse(String[] args) 解析输入参数
private void execCmds() throws IOException 执行输入命令
private void parseStoplist() throws IOException 解析禁用词表
private void parseDir(String dir) 递归处理目录
public void write(Stat fstat) throws IOException 写统计结果
public int countChars() throws IOException 统计字符
public int[] countDifferentLines() throws IOException 统计不同种类的行数
4.代码说明
public class Test {
public static void main(String[] args) throws IOException {
Counter ctr=new Counter(args);
for(int i=0;i<ctr.ipfiles.size();i++)
{
Stat fstat=new Stat(ctr.ipfiles.get(i));
System.out.println("precessing "+ctr.ipfiles.get(i));
ctr.write(fstat);
}
}
}
//进行测试,输入字符并得到统计结果模块
private void parse(String[] args)
{
if(args.length==0)
System.out.println("缺少必要参数");
String lastCommand=null;
for (int i = 0; i < args.length; ++i)
{
if (args[i].startsWith("-"))
{
lastCommand=args[i];
switch (args[i])
{
case "-c":
commands[0] = true;
break;
case "-w":
commands[1] = true;
break;
case "-l":
commands[2] = true;
break;
case "-o":
commands[3] = true;
break;
case "-a":
commands[4] = true;
break;
case "-s":
commands[5] = true;
break;
case "-e":
commands[6] = true;
}
}
else
{
switch (lastCommand)
{
case "-c":case "-w":case "-l":case "-a":
ipfiles.add(args[i]);
break;
case "-o":
opfile=args[i];
case "-e":
slfile=args[i];
}
}
}
//根据不同节点分为不同的情况,对传来的参数进行解析。
for(int i=0;i<content.length();i++)
{
char ch=content.charAt(i);
if(ch==\' \'||ch==\',\'||ch==\',\'||ch==\'\\t\') {
if(inWord) {
if(!sl.isEmpty())
{
if(!beingStopped(word,sl))
words++;
}
else
words++;
word="";
inWord=false;
}
}
else {
if(!inWord)
inWord=true;
word+=ch;
}
}
//识别空格,逗号,水平制表符对字符进行计数
5.测试设计
测试用例是为某个特殊目标而编制的一组测试输入、执行条件以及预期结果,以便测试某个程序路径或核实是否满足某个特定需求,通俗的讲:就是把我们测试系统的操作步骤用按照一定的格式用文字描述出来。【2】【3】
首先分析测试需求,得到测试点,再将测试点简单的分配一下优先级。根据测试点,细化出具体的测试用例。利用测试用例画出流程图,进行路径覆盖设计测试用例。需要考虑的就是测试点细化到什么程度的问题,也就是一个度的问题,我们要把握好测试点细化的一个度的问题,太粗的测试点没有指导意义,太细的测试点容易让我们纠的太细,忽略整体的测试,反而也起不到一个指导的效果,所以一定要把握好测试点细化的度。由于需求会有变动,测试用例也要进行及时更新和维护。设计测试用例时根据是否统计单词字符是否统计行数等节点设计了十个测试用例。
测试用例的风险来自于超出预期设计的用例即没有在起始设计功能范围内的输入,代码缺陷造成的输入后程序无法正常运行以及用户环境的缺陷使得字符无法正常识别。每一个高风险必须被正向测试用例及负向测试用例所覆盖。另外,至少50%与高风险相关的测试用例应该具有最高等级的测试用例优先级。中间等级的风险主要由正向测试用例覆盖,并且可以分布于最高的三个测试用例优先级中等。
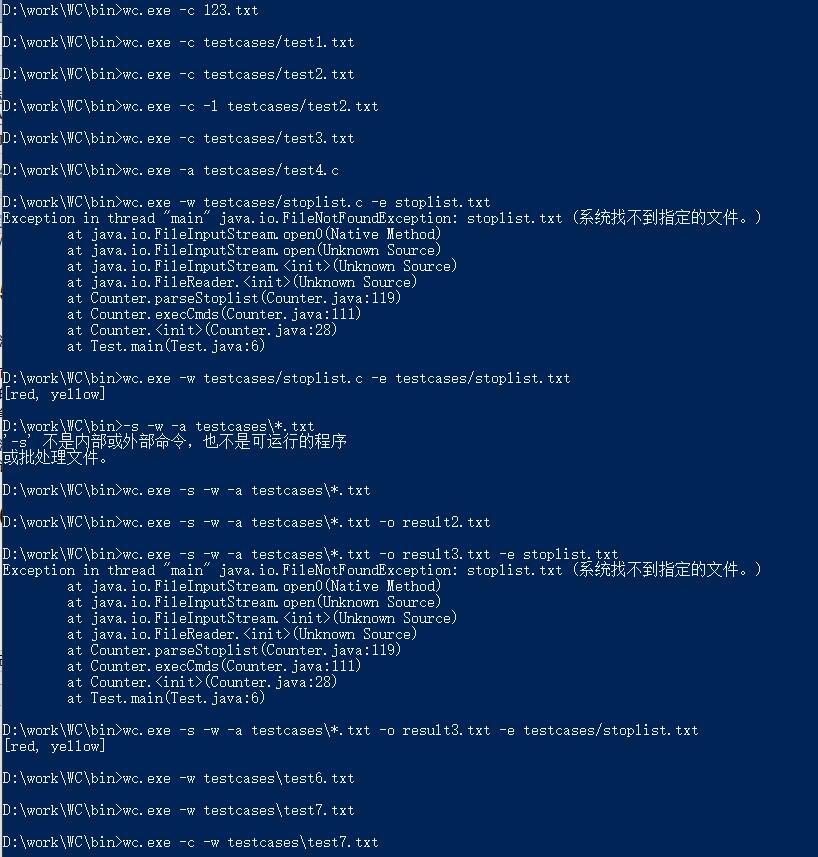

6.参考文献
【1】http://blog.csdn.net/liaction/article/details/47663833
【2】https://www.cnblogs.com/hanxiaomin/p/6132811.html
【3】http://qualtech.newsweaver.ie/startester/18wsevk2e6v1nkk3ly7um2
以上是关于wordcount的主要内容,如果未能解决你的问题,请参考以下文章