node.js
Posted 倒立的蜗牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了node.js相关的知识,希望对你有一定的参考价值。
javascript单线程的误解
在我接触JavaScript(无论浏览器还是NodeJS)的时间里,总是遇到有朋友有多线程的需求。而在NodeJS方面,有朋友甚至直接说到,NodeJS是单线程的,无法很好的利用多核CPU。
诚然,在前端的浏览器中,由于前端的JavaScript与UI占据同一线程,执行JavaScript确实为UI响应造成了一定程度上的麻烦。但是,除非用到超大的循环语句执行JavaScript,或是用阻塞式的Ajax,或是太过频繁的定时器执行外,JavaScript并没有给前端应用带来明显的问题,所以也很少有朋友抱怨JavaScript是单线程而不能很好利用多核CPU的问题,因为没有因此出现性能瓶颈。
但是,我们可以用Ajax和Web Worker回应这个误解。当Ajax请求发送之后,除非是同步请求,否则其余的JavaScript代码会很快被执行到。在Ajax发送完成,直到接收到响应的这段时间里,这个网络请求并不会阻塞JavaScript的执行,而网络请求已经发生,这是必然的事。那么,答案就很明显了,JavaScript确实是执行在单线程上的,但是,整个Web应用执行的宿主(浏览器)并非以单线程的方式在执行。而Web Worker的诞生,就是直接为了解决JavaScript与UI占用同一线程造成的UI响应问题的,它能新开一条线程去执行JavaScript。
同理,NodeJS中的JavaScript也确实是在单线程上执行,但是作为宿主的NodeJS,它本身并非是单线程的,NodeJS在I/O方面又动用到一小部分额外的线程协助实现异步。程序员没有机会直接创建线程,这也是有的同学想当然的认为NodeJS的单线程无法很好的利用多核CPU的原因,他们甚至会说,难以想象由多人一起协作开发一个单线程的程序。
NodeJS封装了内部的异步实现后,导致程序员无法直接操作线程,也就造成所有的业务逻辑运算都会丢到JavaScript的执行线程上,这也就意味着,在高并发请求的时候,I/O的问题是很好的解决了,但是所有的业务逻辑运算积少成多地都运行在JavaScript线程上,形成了一条拥挤的JavaScript运算线程。NodeJS的弱点在这个时候会暴露出来,单线程执行运算形成的瓶颈,拖慢了I/O的效率。这大概可以算得上是密集运算情况下无法很好利用多核CPU的缺点。这条拥挤的JavaScript线程,给I/O形成了性能上限。
但是,事情又并非绝对的。回到前端浏览器中,为了解决线程拥挤的情况,Web Worker应运而生。而同样,Node也提供了child_process.fork来创建Node的子进程。在一个Node进程就能很好的解决密集I/O的情况下,fork出来的其余Node子进程可以当作常驻服务来解决运算阻塞的问题(将运算分发到多个Node子进程中上去,与Apache创建多个子进程类似)。当然child_process/Web Worker的机制永远只能解决单台机器的问题,大的Web应用是不可能一台服务器就能完成所有的请求服务的。拜NodeJS在I/O上的优势,跨OS的多Node之间通信的是不算什么问题的。解决NodeJS的运算密集问题的答案其实也是非常简单的,就是将运算分发到多个CPU上。请参考文章后的multi-node的性能测试,可以看到在多Node进程的情景下,响应请求的速度被大幅度提高。
在文章的写作中,Node最新发布的0.5.10版本新增了cluster启动参数。参数的使用方式如下:
node cluster server.js
启动Node的时候,在附加了该参数的情况下,Node会检测机器上的CPU数量来决定启动多少进程实例,这些实例会自动共享相同的侦听端口。详情请参阅官方文档。在之前的解决运算密集问题中,工程师需要multi-node这样的库或者其他方案去手动分发请求,在cluster参数的支持下,可以释放掉工程师在解决此问题上的大部分精力。
事件式编程
延续上一节的讨论。我们知道NodeJS/JavaScript具有异步的特性,从NodeJS的API设计中可以看出来,任何涉及I/O的操作,几乎都被设计成事件回调的形式,且大多数的类都继承自EventEmitter。这么做的好处有两个,一个是充分利用无阻塞I/O的特性,提高性能;另一个好处则是封装了底层的线程细节,通过事件消息留出业务的关注点给编程者,从而不用关注多线程编程里牵扯到的诸多技术细节。
从现实的角度而言,事件式编程也更贴合现实。举一个业务场景为例:家庭主妇在家中准备中餐,她需要完成两道菜,一道拌黄瓜,一道西红柿蛋汤。以php为例,家庭主妇会先做完拌黄瓜,接着完成西红柿蛋汤,是以顺序/串行执行的。但是现在突然出了一点意外,凉拌黄瓜需要的酱油用光了,需要她儿子出门帮她买酱油回来。那么PHP家庭主妇在叫她儿子出门打酱油的这段时间都是属于等待状态的,直到酱油买回来,才会继续下一道菜的制作。那么,在NodeJS的家庭主妇又会是怎样一个场景呢,很明显,在等待儿子打酱油回来的时间里,她可以暂停凉拌黄瓜的制作,而直接进行西红柿蛋汤的过程,儿子打完酱油回来,继续完成她的凉拌黄瓜。没有浪费掉等待的时间。实例伪代码如下:
var mother = new People();
var child = new People();
child.buySoy(function (soy) {
mother.cook("cucumber", soy);
});
mother.cook("tomato");
接下来,将上面这段代码转换为基于事件/任务异步模式的代码:
var proxy = new EventProxy();
var mother = new People();
proxy.bind("cook_cucumber", function (soy) {
mother.cook("cucumber", soy);
});
proxy.bind("cook_tomato", function () {
mother.cook("tomato");
});
var child = new People();
child.buySoy(function (soy) {
proxy.trigger("cucumber", soy);
});
proxy.trigger("tomato");
代码量多了很多,但是业务逻辑点都是很清楚的:通过bind方法预定义了cook_cucumber和cook_tomato两个任务。这里的bind方法可以认为是await的消息式实现,需要第一个参数来标识该任务的名字,流程在执行的过程中产生的消息会触发这些任务执行。可以看出,事件式编程中,用户只需要关注它所需要的几个业务事件点就可以,中间的等待都由底层为你调配好了。这里的代码只是举例事件/任务异步模式而用,在简单的场景中,第一段代码即可。做NodeJS的编程,会更感觉是在做现实的业务场景设计和任务调度,没有顺序保证,程序结构更像是一个状态机。
个人觉得在事件式编程中,程序员需要转换一下思维,才能接受和发挥好这种异步/无阻塞的优势。同样,这种事件式编程带来的一个问题就在于业务逻辑是松散和碎片式的。这对习惯了顺序式,Promise式编程的同学而言,接受它是比较痛苦的事情,而且这种散布的业务逻辑对于非一开始就清楚设计的人而言,阅读存在相当大的问题。
我提到事件式编程更贴近于现实生活,是更自然的,所以这种编程风格也导致你的代码跟你的生活一样,是一件复杂的事情。幸运的是,自己的生活要自己去面对,对于一个项目而言,并不需要每个人都去设计整个大业务逻辑,对于架构师而言,业务逻辑是明了的,借助事件式编程带来的业务逻辑松耦合的好处,在设定大框架后,将业务逻辑划分为适当的粒度,对每一个实现业务点的程序员而言,并没有这个痛苦存在。二八原则在这个地方非常有效。
深度嵌套回调问题
JavaScript/NodeJS对单个异步事件的处理十分容易,但容易出现问题出现的地方是“多个异步事件之间的结果协作”。以NodeJS服务端渲染页面为例,渲染需要数据,模板,本地化资源文件,这三个部分都是要通过异步来获取的,原生代码的写法会导致嵌套,因为只有这样才能保证渲染的时候数据,模板,本地化资源都已经获取到了。但问题是,这三个步骤之间实际是无耦合的,却因为原生代码没有promise的机制,将可以并行执行(充分利用无阻塞I/O)的步骤,变成串行执行的过程,直接降低了性能。代码如下:
var render = function (template, data) {
_.template(template, data);
};
$.get("template", function (template) { // something
$.get("data", function (data) { // something
$.get("l10n", function (l10n) { // something
render(template, data);
});
});
});
面对这样的代码,许多工程师都表示不爽。这个弱点也形成了对NodeJS推广的一个不大不小的障碍。对于追求性能和维护性的同学,肯定不满足于以上的做法。本人对于JavaScript的事件和回调都略有偏爱,并且认为事件,回调,并行,松耦合是可以达成一致的。以下一段代码是用EventProxy实现的:
var proxy = new EventProxy();
var render = function (template, data, l10n) {
_.template(template, data);
};
proxy.assign("template", "data", "l10n", render);
$.get("template", function (template) { // something
proxy.trigger("template", template);
});
$.get("data", function (data) { // something
proxy.trigger("data", data);
});
$.get("l10n", function (l10n) { // something
proxy.trigger("l10n", l10n);
});
代码量看起来比原生实现略多,但是从逻辑而言十分清晰。模板、数据、本地化资源并行获取,性能上的提高不言而喻,assign方法充分利用了事件机制来保证最终结果的正确性。在事件,回调,并行,松耦合几个点上都达到期望的要求。
关于更多EventProxy的细节可参考其官方页面。
深度回调问题的延伸
EventProxy解决深度回调的方式完全基于事件机制,这需要建立在事件式编程的认同上,那么必然也存在对事件式编程不认同的同学,而且习惯顺序式,promise式,向其推广bind/trigger模式实在难以被他们接受。Jscex和Streamline.js是目前比较成熟的同步式编程的解决方案。可以通过同步式的思维来进行编程,最终执行的代码是通过编译后的目标代码,以此通过工具来协助用户转变思维。
结语
对于优秀的东西,我们不能因为其表面的瑕疵而弃之不用,总会有折衷的方案来满足需求。NodeJS在实时性方面的功效有目共睹,即便会有一些明显的缺点,但是随着一些解决方案的出现,相信没有什么可以挡住其前进的脚步。
附录(多核环境下的并发测试)
服务器环境:
- 网络环境:内网
- 压力测试服务器:
- 服务器系统:Linux 2.6.18
- 服务器配置:Intel(R) Xeon(TM) CPU 3.40GHz 4 CPUS
- 内存:6GB
- NodeJS版本: v0.4.12
客户端测试环境:
- 发包工具:apache 2.2.19自带的ab测试工具
- 服务器系统:Linux 2.6.18
- 服务器配置:Pentium(R) Dual-Core CPU E5800 @ 3.20GHz 2CPUS
- 内存:1GB
单线程Node代码:
var http = require(\'http\');
var server = http.createServer(function (request, response) {
var j = 0;
for (var i = 0; i & lt; 100000; i++) {
j += 2 / 3;
}
response.end(j + \'\');
});
server.listen(8881);
console.log(\'Server running at http://10.1.10.150:8881/\');
四进程Node代码:
var http = require(\'http\');
var server = http.createServer(function (request, response) {
var j = 0;
for (var i = 0; i & lt; 100000; i++) {
j += 2 / 3;
}
response.end(j + \'\');
});
var nodes = require("./lib/multi-node").listen({
port: 8883,
nodes: 4
}, server);
console.log(\'Server running at http://10.1.10.150:8883/\');
这里简单介绍一下multi-node这个插件,这个插件就是利用require("child_process").spawn()方法来创建多个子线程。由于浮点计算和字符串拼接都是比较耗CPU的运算,所以这里我们循环10W次,每次对j加上0.66666。最后比较一下,开多子进程node到底比单进程node在CPU密集运算上快多少。
以下是测试结果:
|
Comm. |
500/30 |
500/30 |
1000/30 |
1000/30 |
3000/30 |
3000/30 |
|
Type |
单进程 |
多子进程 |
单进程 |
多子进程 |
单进程 |
多子进程 |
|
RPS |
2595 |
5597 |
2540 |
5509 |
2571 |
5560 |
|
TPQ |
0.38 |
0.18 |
0.39 |
0.19 |
0.39 |
0.18 |
|
80% REQ |
72 |
65 |
102 |
85 |
157 |
142 |
|
Fail |
0 |
0 |
0 |
0 |
0 |
0 |
说明:
- 单进程:只开一个node.js进程。
- 多子进程:开一个node.js进程,并且开3个它的子进程。
- 3000/30:代表命令 ./ab -c 3000 -t 30 http://10.1.10.150:8888/。3000个客户端,最多发30秒,最多发5W个请求。
- RPS:代表每秒处理请求数,并发的主要指标。
- TPQ:每个请求处理的时间,单位毫秒。
- Fail:代表平均处理失败请求个数。
- 80% Req:代表80%的请求在多少毫秒内返回。
从结果及图1~3上看:开多个子进程可以显著缓解node.js的CPU利用率不足的情况,提高node.js的CPU密集计算能力。
图1:单个进程的node.js在压力测试下的情况,无法充分利用4核CPU的服务器性能。
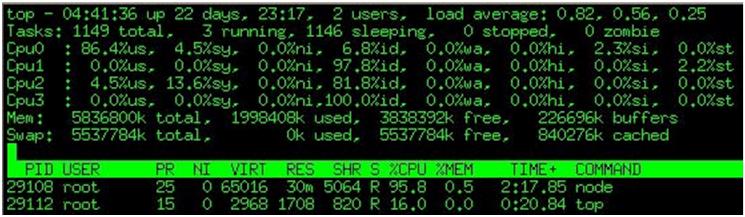
图2:多进程node,可以充分利用4核CPU榨干服务器的性能。
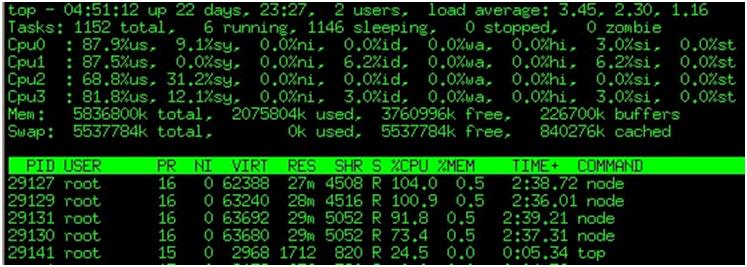
图3:多子进程截图,可以看到一共跑了4个进程。

以上是关于node.js的主要内容,如果未能解决你的问题,请参考以下文章