数据结构与算法分析算法分析
Posted MenAngel
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法分析算法分析相关的知识,希望对你有一定的参考价值。
算法是为了求解一个问题需要遵循的、被清楚地指定的简单指令的集合。对于一个问题,一旦给定某种算法并且其是正确的,那么重要的一步就是确定该算法将需要多少诸如时间或空间等资源量的问题。
此篇博客将讨论:
1.如何估计一个程序所需要的时间;
2.如何降低程序运行所需要的时间;
3.粗心使用递归的后果;
4.将一个数自乘得到其幂以及计算两个数的最大公因数的非常有效的算法;
(1)算法分析的数学基础
估计算法资源消耗所需的分析需要一套正式的系统架构:
使用四个定义:
1.如果存在正常数c和n0,使得当N>=n0时T(N)<=cf(N),则记为T(N)=O(f(N)); T(N)的增长率小于等于f(N)的增长率
2.如果存在正常数c和n0,使得当N>=n0时T(N)>=cg(N),则记为T(N)=Ω(g(N)); T(N)的增长率大于等于g(N)的增长率
3.T(N)=Θ (h(N))当且仅当T(N)=O(h(N)) ,则T(N)=Ω(h(N)); T(N)的增长率等于h(N)的增长率
4.如果T(N)=O(p(N))且T(N)≠Θ(p(N)),则T(N)=o(p(N)); T(N)的增长率小于p(N)的增长率
这些定义的目的是要在函数间建立一种相对的级别。给定两个函数,通常存在一些点,在这些点上一个函数的值小于另一个函数的值,因此,像f(N)<g(N)这样的声明是没有意义的。于是我们比较他们的相对增长率。
例子:虽然N较小时1000N要比N^2要大,但最终N^2要更大。这种情况下,N=1000是转折点。第一个定义是说最后总会存在某个点n0使得从它以后c*f(N)至少与T(N)一样大,从而若忽略常数因子,则f(N)也至少与T(N)一样大。在此例中,T(N)=1000N,f(N)=N^2,n0=1000而c=1。我们也可以让n0=10,而c=100。因此我们可以说1000N=O(N^2)。这种记法称为大O记法。
需要掌握的结论:
法则1:如果T1(N)=O(f(N)),且T2(N)=O(g(N)),那么:
(a)T1(N)+T2(N)=max(O(f(N),O(g(N)));
(b)T1(N)*T2(N)=O(f(N)*g(N));
法则2:如果T(N)是一个k次多项式,则T(N)=Θ(N^k);
法则3:对任意常数k,(logN)^k=O(N)。他们告诉我们对数增长十分缓慢。
法则4:任何对数,无论底数如何都具有相同的增长率。
典型的增长率:
| 函数 | 名称 |
| c | 常数 |
| logN | 对数级 |
| (logN)^2 | 对数平方根 |
| N | 线性级 |
| NlogN | |
| N^2 | 平方级 |
| N^3 | 立方级 |
| 2^N | 指数级 |
用大O表示法时要注意:
1.不要将常数或者低阶放进大O表示法的表达式;
2.我们能通过计算极限(n趋向于无穷大)f(N)/g(N)来确定两个函数的相对增长率,必要的时候可以使用洛必达法则。
极限是0:这一点意味着f(N)=o(g(N));
极限是常数c:这意味着f(N)=Θ(g(N));
极限是无穷大:意味着g(N)=o(f(N));
3.在用大O表示法时,不能包含小于号,例如:f(N)<=O(g(N))就是没有意义的,因为定义已经隐含有不等式了。
(2)模型
为了在正式的框架中分析算法,我们需要一个计算模型。我们的模型基本上是一台标准的计算机,它有如下特点:
1.在机器中指令被顺序的执行;
2.该模型有一个标准的简单指令系统;
3.模型机做任何一个简单的工作都恰好花费一个时间单元;
4.模型机有无限的内存;
这些假设都是为了我们能够简单的定量分析一个算法所需要的运算量和运算时间。
(3)要分析的问题
要分析的而最终要的资源就是运行时间。影响的因素:
1.所使用的算法;
2.对于该算法的输入;
示例:最大的子序列和的问题
给定整数A1,A2......AN,求序列中连续项之和的最大值。(如果所有数均为负数,则最大子序列和为0)
例:输入-2,11,-4,13,-5,-2时,答案为20(从第二个到第四个的和)。
这个问题之所以有吸引力,主要是因为存在求解它的很多算法,而这些算法的性能差异又很大。后面将讨论这求解这个问题的四种效率不同的算法。
计算最大子序列和的几种算法的运行时间(理论值):
| 算法 | 1 | 2 | 3 | 4 |
| 时间 | O(N^3) | O(N^2) | O(NlogN) | O(N) |
| N=10 | 0.00103 | 0.00045 | 0.00066 | 0.00034 |
| N=100 | 0.4705 | 0.01112 | 0.00486 | 0.00063 |
| N=1000 | 448.77 | 1.1233 | 0.05843 | 0.00333 |
| N=10000 | NA | 111.13 | 0.68631 | 0.03042 |
| N=100000 | NA | NA | 8.0113 | 0.29832 |
从表中可以看出:
1.对于少量输入,无论什么算法,瞬间即可完成;此时花费大量努力去设计聪明的算法就不太值得了!
2.表中给出的数据不包括读入数据所需要的时间。对于算法4,可能读入数据所需要的时间比求解问题需要的时间还长。
3.低效算法只能解决微量输入,即是数据输入量的大小是适当的,低效算法依旧无用;
(4)运行时间的计算
进行算法分析的能力有助于洞察到如何设计有效的算法,分析还能准确确定编码的瓶颈。在大O表示法进行算法分析时,大O是一个上界,因此我们必须仔细,绝不要低估程序运行的时间。分析的结果为程序在一定的时间内结束提供了保障。程序可能提前结束,但绝不可能拖后。
如果两个程序花费的时间大致相同,要确定哪个程序更快的方法很可能就是将他们编码并运行;
下面通过一个例子来示范如何用大O表示法进行算法分析:
1 //计算立方的累加和 2 int 3 Sum(int N){ 4 int i,PartialSum; 5 6 PartialSum=0; 7 for( i=1;i<=N;i++){ 8 PartialSum+=i*i*i; 9 return PartialSum; 10 } 11 }
分析:1).声明不计时间,第6行和第9行各占一个时间单元。
2).第3行每执行一次占用4个时间单元(两次乘法一次加法一次赋值),而执行N次总共4N个时间单元。
3).第2行在初始化i(1个),测试i<=N(N+1个)和对i的自增运算(N个)中隐藏着开销。总共是2N+2个时间单元。
总的开销是6N+2,因此我们说该函数是O(N)。
快速进行运算时间的算法分析的一般法则:
1)法则1--for循环:
一次for循环的运行时间至多是该for循环内语句(包括测试)的运行时间乘以迭代的次数;
2)法则2--嵌套的for循环
从里向外进行分析:在一组嵌套循环内部的一条语句总的运行时间为该语句的运行时间乘以改组所有的for循环的大小的乘积;
3)法则3--顺序语句
将各个语句的运行时间求和即可。其中的最大值就是所得的运行时间。
for(){ } for(){ for(){} }//这个例子先用去O(N),再花费O(N^2),总的开销也是O(N^2);
4)法则4--if/else语句
对于程序片段
if(Condition) s1 else s2
一条if/else语句的运行时间从不超过判断再加上s1和s2中运行时间长者的运行时间。(会估高但绝不会估低)
其他的法则都是显然的在此就不做赘述,但是分析基本上是从内部向外部展开,如果由函数调用,那么这些调用要首先分析。如果有递归的话,存在几种选择;
1.递归只是被薄面纱遮住的for循环,其运行时间为O(N):
long int Factorial(int n){ if(N<=1) return 1; else return N*Factorial(N-1); }
2.如果递归是被正常使用的话将其转化为一个简单的循环结构是非常困难的。在这种情况下分析将设计求解一个递推关系。
long int Fib(int N){ if(N<=1) return 1; else return Fib(N-1)+Fib(N-2); }
初看起来,该程序似乎对递归的使用非常聪明,但是如果将程序编码,赋予N=30的话将会发现程序让人感到效率低的吓人。
由于求解Fib(N)需要用到Fib(N-1)和Fib(N-2),而Fib(N-1)的求解又会用到Fib(N-2),计算时他们不是直接将算好的拿过来直接用而是让计算机根据递归重新迭代。因此当N逐渐变大时,计算量将按指数形式增加,效率严重低下。违反了使用递归的第四条原则合成效益原则。
(5)最大子序列和的解:
1)算法1:穷举式地尝试所有的可能,算法的开销为Θ(N^3)。
1 #include<stdio.h> 2 3 int MaxSubsequenceSum(const int a[],int N){ 4 int ThisSum,MaxSum,i,j,k; 5 MaxSum=0; 6 for(i=0;i<N;i++){ 7 for(j=0;j<N;j++){ 8 ThisSum=0; 9 for(k=i;k<=j;k++){ 10 ThisSum+=a[k]; 11 } 12 if(ThisSum>MaxSum){ 13 MaxSum=ThisSum; 14 } 15 } 16 } 17 return MaxSum; 18 } 19 int main(){ 20 int numGroup[8]={ 21 8,-10,7,23,-14,31,19,-43 22 }; 23 printf("数组的最大子序列和为%d",MaxSubsequenceSum(numGroup,8)); 24 }

2)算法二:在算法一的基础上,通过撤销一个for循环来避免立方运行时间,算法的消耗为O(N^2):
1 #include<stdio.h> 2 3 int MaxSubsequenceSum(const int A[],int N){ 4 int ThisSum,MaxSum,i,j; 5 MaxSum=0; 6 for(i=0;i<N;i++){ 7 ThisSum=0; 8 for(j=i;j<N;j++){ 9 ThisSum+=A[j]; 10 if(ThisSum>MaxSum){ 11 MaxSum=ThisSum; 12 } 13 } 14 } 15 return MaxSum; 16 } 17 int main(){ 18 int numGroup[8]={ 19 8,-10,7,23,-14,31,19,-43 20 }; 21 printf("数组的最大子序列和为%d",MaxSubsequenceSum(numGroup,8)); 22 }
3)算法3,采用一种分治的策略,其想法是把问题分成两个大致相等的子问题,然后递归的对他们求解,算法的消耗为O(NlogN):
1 #include<stdio.h> 2 3 int maxBetweenTwo(int a,int b){ 4 return a>b?a:b; 5 } 6 int maxBetweenThree(int a,int b,int c){ 7 return maxBetweenTwo(maxBetweenTwo(a,b),c); 8 } 9 int MaxSubSum(const int A[],int left,int right){ 10 int maxleftsum,maxrightsum; 11 int maxleftbordersum,maxrightbordersum; 12 int leftbordersum,rightbordersum; 13 int center,i; 14 if(left==right){ 15 if(A[left]>0){ 16 return A[left]; 17 }else{ 18 return 0; 19 } 20 } 21 center=(left+right)/2; 22 maxleftsum=MaxSubSum(A,left,center); 23 maxrightsum=MaxSubSum(A,center+1,right); 24 //找到左序列中包括center的最大的一串序列值 25 maxleftbordersum=0;leftbordersum=0; 26 for(i=center;i>=left;i--){ 27 leftbordersum+=A[i]; 28 if(leftbordersum>maxleftbordersum){ 29 maxleftbordersum=leftbordersum; 30 } 31 } 32 //找到右边序列包括center+1的最大的一串序列值 33 rightbordersum=0;maxrightbordersum=0; 34 for(i=center+1;i<=right;i++){ 35 rightbordersum+=A[i]; 36 if(rightbordersum>maxrightbordersum){ 37 maxrightbordersum=rightbordersum; 38 } 39 } 40 return maxBetweenThree(maxleftsum,maxrightsum,maxleftbordersum+maxrightbordersum); 41 } 42 //注意数组大小为8,最大下标为8-1=7; 43 int MaxSubsequenceSum(const int A[],int N){ 44 return MaxSubSum(A,0,N-1); 45 } 46 int main(){ 47 int numGroup[8]={ 48 8,-10,7,23,-14,31,19,-43 49 }; 50 printf("数组的最大子序列和为%d",MaxSubsequenceSum(numGroup,8)); 51 }
4)解决这个问题的联机算法:(数据只被进行一次扫描,顺序读入,一旦一个数据被处理就不需要被记忆;而且在任意时刻算法都能给出求解问题的正确答案。)
1 #include<stdio.h> 2 3 int MaxSubsequenceSum(const int A[],int N){ 4 int ThisSum=0,MaxSum=0; 5 int i; 6 for(i=0;i<N;i++){ 7 ThisSum+=A[i]; 8 if(ThisSum>MaxSum){ 9 MaxSum=ThisSum; 10 }else if(ThisSum<0){ 11 ThisSum=0; 12 } 13 } 14 return MaxSum; 15 } 16 int main(){ 17 int numGroup[8]={ 18 8,-10,7,23,-14,31,19,-43 19 }; 20 printf("数组的最大子序列和为%d",MaxSubsequenceSum(numGroup,8)); 21 }
(6)运行时间的对数:
分析算法最混乱的地方大概集中在对数方面。某些分治算法将以O(NlogN)时间运行。
对数最常出现的一般规律:
如果一个算法用常数时间O(1)将问题的大小削减为其一部分(通常为1/2),那么该算法就是O(logN)。
下面我们提供具有对数特点的三个例子:
1)对分查找:
给定一个整数X和整数数组,后者已经预先排序,求使得A[i]=X的下标i,如果X不在数据中,则返回-1。
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<time.h> 4 5 //用二分法查找数组中的数。 6 int searchNum(int a[],int x,int low,int high){ 7 int mid=(low+high)/2; 8 if(a[mid]==x){ 9 return mid; 10 }else if(a[mid]>x){ 11 high=mid-1; 12 }else if(a[mid]<x){ 13 low=mid+1; 14 } 15 return searchNum(a,x,low,high); 16 } 17 int BinarySearch(int a[],int x,int N){ 18 int Low,Mid,High; 19 Low=0;High=N-1; 20 while(Low<=High){ 21 Mid=(Low+High)/2; 22 if(a[Mid]<x){ 23 Low=Mid+1; 24 }else 25 if(a[Mid]>x){ 26 High=Mid-1; 27 }else 28 return Mid; 29 } 30 return -1; 31 } 32 int main(){ 33 srand((int)time(NULL)); 34 int i,x; 35 int a[1000],b[100];//数组a辅助产生不重复的随机数并排序 36 for(i=0;i<1000;i++){ 37 a[i]=0; 38 } 39 for(i=0;i<100;i++){ 40 //保证数组a中有99个数为1 41 L: x=rand()%1000; 42 if(a[x]==1){ 43 goto L; 44 }else{ 45 a[x]=1; 46 } 47 } 48 int j; 49 //随机产生的99个数放到数组b中 50 for(i=0,j=0;j<1000;j++){ 51 if(a[j]==1){ 52 b[i]=j; 53 i++; 54 }else{ 55 continue; 56 } 57 } 58 59 for(i=0;i<100;i++){ 60 printf("%4d",b[i]); 61 if((i+1)%20==0){ 62 printf("\\n"); 63 } 64 } 65 printf("请输入需要用二分法查找的数:\\n"); 66 scanf("%d",&x); 67 printf("你要找的数在数组中的位置是:\\n%d(不用递归),%d(用递归)。\\n", 68 BinarySearch(b,x,100),searchNum(b,x,0,100)); 69 return 0; 70 }
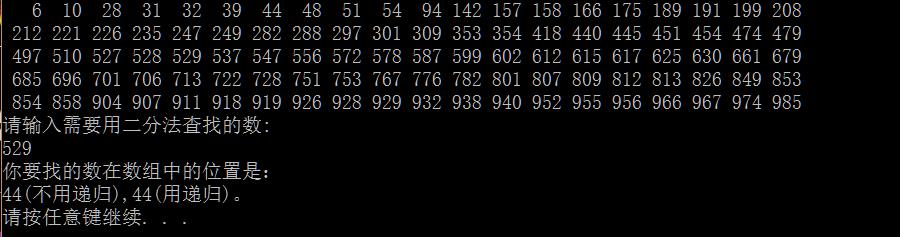
对分查找也可以运用到查元素周期表的例程中。这个表示相对稳定的,偶尔会加入新的元素。元素名可以始终是排序的。大概只有110中元素,因此找到一个元素最多需要访问8次。要是执行顺序查找,则需要多得多的访问次数。
2)欧几里得算法
计算最大公约数的有效算法:
1 #include<stdio.h> 2 //欧几里德算法 3 unsigned int Gcd(unsigned int M,unsigned int N){ 4 unsigned int Rem; 5 if(N>M){ 6 int temp=M; 7 M=N; 8 N=temp; 9 } 10 //必须保证进入循环时M>=N 11 while(N>0){ 12 Rem=M%N; 13 M=N; 14 N=Rem; 15 } 16 return M; 17 } 18 //普通算法: 19 unsigned int Ordinary(int M,int N){ 20 int smller=M>N?N:M; 21 int i; 22 for(i=smller;i>0;i--){ 23 if(M%i==0&&N%i==0){ 24 return i; 25 } 26 } 27 } 28 int main(){ 29 printf("请输入两个整数,以便求他们的最大公约数:\\n"); 30 int a,b; 31 scanf("%d,%d",&a,&b); 32 printf("用欧几里德算法计算%d和%d最大公约数为:%d\\n",a,b,Gcd(a,b)); 33 printf("用普通的算法计算%d和%d的最大公约数为:%d\\n",a,b,Ordinary(a,b)); 34 }
欧几里德算法运行时间的估计:
定理:如果M>N,则M mode N < M/2;欧几里德算法在平均情况下的性能需要大量篇幅的高度复杂的数学分析,其迭代的平均次数为(12ln2lnN)/(PI^2)+1.47。
3)幂运算
计算个整数的幂(X^N):
1 #include<stdio.h> 2 3 int isEven(int n){ 4 if(n%2==0){ 5 数据结构与算法复杂度分析