问题描述
Markdown 是一种很流行的轻量级标记语言(lightweight markup language),广泛用于撰写带格式的文档。例如以下这段文本就是用 Markdown 的语法写成的:
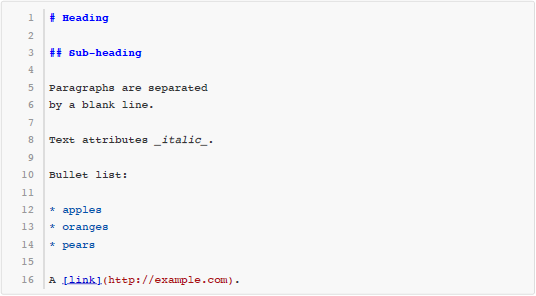
这些用 Markdown 写成的文本,尽管本身是纯文本格式,然而读者可以很容易地看出它的文档结构。同时,还有很多工具可以自动把 Markdown 文本转换成 html 甚至 Word、PDF 等格式,取得更好的排版效果。例如上面这段文本通过转化得到的 HTML 代码如下所示:
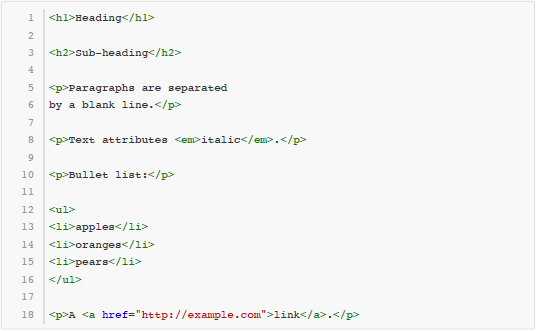
本题要求由你来编写一个 Markdown 的转换工具,完成 Markdown 文本到 HTML 代码的转换工作。简化起见,本题定义的 Markdown 语法规则和转换规则描述如下:
●区块:区块是文档的顶级结构。本题的 Markdown 语法有 3 种区块格式。在输入中,相邻两个区块之间用一个或多个空行分隔。输出时删除所有分隔区块的空行。
○段落:一般情况下,连续多行输入构成一个段落。段落的转换规则是在段落的第一行行首插入 `<p>`,在最后一行行末插入 `</p>`。
○标题:每个标题区块只有一行,由若干个 `#` 开头,接着一个或多个空格,然后是标题内容,直到行末。`#` 的个数决定了标题的等级。转换时,`# Heading` 转换为 `<h1>Heading</h1>`,`## Heading` 转换为 `<h2>Heading</h2>`,以此类推。标题等级最深为 6。
○无序列表:无序列表由若干行组成,每行由 `*` 开头,接着一个或多个空格,然后是列表项目的文字,直到行末。转换时,在最开始插入一行 `<ul>`,最后插入一行 `</ul>`;对于每行,`* Item` 转换为 `<li>Item</li>`。本题中的无序列表只有一层,不会出现缩进的情况。
●行内:对于区块中的内容,有以下两种行内结构。
○强调:`_Text_` 转换为 `<em>Text</em>`。强调不会出现嵌套,每行中 `_` 的个数一定是偶数,且不会连续相邻。注意 `_Text_` 的前后不一定是空格字符。
○超级链接:`[Text](Link)` 转换为 `<a href="Link">Text</a>`。超级链接和强调可以相互嵌套,但每种格式不会超过一层。
这些用 Markdown 写成的文本,尽管本身是纯文本格式,然而读者可以很容易地看出它的文档结构。同时,还有很多工具可以自动把 Markdown 文本转换成 html 甚至 Word、PDF 等格式,取得更好的排版效果。例如上面这段文本通过转化得到的 HTML 代码如下所示:
本题要求由你来编写一个 Markdown 的转换工具,完成 Markdown 文本到 HTML 代码的转换工作。简化起见,本题定义的 Markdown 语法规则和转换规则描述如下:
●区块:区块是文档的顶级结构。本题的 Markdown 语法有 3 种区块格式。在输入中,相邻两个区块之间用一个或多个空行分隔。输出时删除所有分隔区块的空行。
○段落:一般情况下,连续多行输入构成一个段落。段落的转换规则是在段落的第一行行首插入 `<p>`,在最后一行行末插入 `</p>`。
○标题:每个标题区块只有一行,由若干个 `#` 开头,接着一个或多个空格,然后是标题内容,直到行末。`#` 的个数决定了标题的等级。转换时,`# Heading` 转换为 `<h1>Heading</h1>`,`## Heading` 转换为 `<h2>Heading</h2>`,以此类推。标题等级最深为 6。
○无序列表:无序列表由若干行组成,每行由 `*` 开头,接着一个或多个空格,然后是列表项目的文字,直到行末。转换时,在最开始插入一行 `<ul>`,最后插入一行 `</ul>`;对于每行,`* Item` 转换为 `<li>Item</li>`。本题中的无序列表只有一层,不会出现缩进的情况。
●行内:对于区块中的内容,有以下两种行内结构。
○强调:`_Text_` 转换为 `<em>Text</em>`。强调不会出现嵌套,每行中 `_` 的个数一定是偶数,且不会连续相邻。注意 `_Text_` 的前后不一定是空格字符。
○超级链接:`[Text](Link)` 转换为 `<a href="Link">Text</a>`。超级链接和强调可以相互嵌套,但每种格式不会超过一层。
输入格式
输入由若干行组成,表示一个用本题规定的 Markdown 语法撰写的文档。
输出格式
输出由若干行组成,表示输入的 Markdown 文档转换成产生的 HTML 代码。
样例输入
# Hello
Hello, world!
Hello, world!
样例输出
<h1>Hello</h1>
<p>Hello, world!</p>
<p>Hello, world!</p>
评测用例规模与约定
本题的测试点满足以下条件:
●本题每个测试点的输入数据所包含的行数都不超过100,每行字符的个数(包括行末换行符)都不超过100。
●除了换行符之外,所有字符都是 ASCII 码 32 至 126 的可打印字符。
●每行行首和行末都不会出现空格字符。
●输入数据除了 Markdown 语法所需,内容中不会出现 `#`、`*`、`_`、`[`、`]`、`(`、`)`、`<`、`>`、`&` 这些字符。
●所有测试点均符合题目所规定的 Markdown 语法,你的程序不需要考虑语法错误的情况。
每个测试点包含的语法规则如下表所示,其中“√”表示包含,“×”表示不包含。
●本题每个测试点的输入数据所包含的行数都不超过100,每行字符的个数(包括行末换行符)都不超过100。
●除了换行符之外,所有字符都是 ASCII 码 32 至 126 的可打印字符。
●每行行首和行末都不会出现空格字符。
●输入数据除了 Markdown 语法所需,内容中不会出现 `#`、`*`、`_`、`[`、`]`、`(`、`)`、`<`、`>`、`&` 这些字符。
●所有测试点均符合题目所规定的 Markdown 语法,你的程序不需要考虑语法错误的情况。
每个测试点包含的语法规则如下表所示,其中“√”表示包含,“×”表示不包含。
| 测试点编号 | 段落 | 标题 | 无序列表 | 强调 | 超级链接 |
| 1 | √ | × | × | × | × |
| 2 | √ | √ | × | × | × |
| 3 | √ | × | √ | × | × |
| 4 | √ | × | × | √ | × |
| 5 | √ | × | × | × | √ |
| 6 | √ | √ | √ | × | × |
| 7 | √ | × | × | √ | √ |
| 8 | √ | √ | × | √ | × |
| 9 | √ | × | √ | × | √ |
| 10 | √ | √ | √ | √ | √ |
提示
由于本题要将输入数据当做一个文本文件来处理,要逐行读取直到文件结束,C/C++、Java 语言的用户可以参考以下代码片段来读取输入内容。
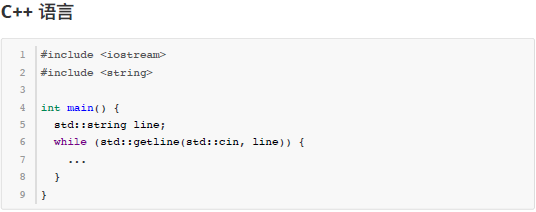
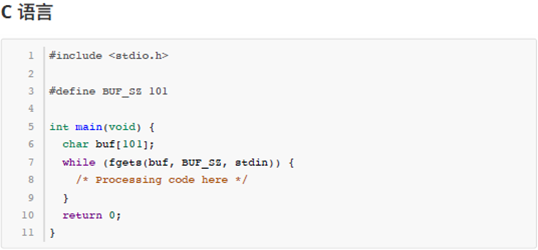
分析
开始没有理解给的表格的意思,以为是这些都可以嵌套,后来发现只是一个区块中可以出现的语法。
可以嵌套的就超级链接和强调,并且会出现在其他语法中。
代码是别人的,还挺好理解的
1 #include <iostream> 2 #include <iomanip> 3 #include <sstream> 4 #include <cstdio> 5 #include <string.h> 6 #include <cstring> 7 #include <algorithm> 8 #include <cmath> 9 #include <string> 10 #include <queue> 11 #include <map> 12 #include <vector> 13 #include <set> 14 #include <list> 15 using namespace std; 16 typedef long long ll; 17 const int INF = 0x3f3f3f3f; 18 const int NINF = 0xc0c0c0c0; 19 const int maxn = 105; 20 int MonthDay[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}; 21 string MonthName[] = {"Jan","Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"}; 22 string DayName[] = {"Sun", "Mon","Tue","Wed","Thu","Fri","Sat"}; 23 string s[maxn]; 24 void output(string str) 25 { 26 for(int i = 0; i < str.length(); i++) { 27 if(str[i] == ‘_‘) { 28 int pos = str.find(‘_‘, i+1); 29 string temp = "<em>" + str.substr(i+1,pos-i-1) + "</em>"; 30 output(temp); 31 i = pos; 32 } 33 else if(str[i] == ‘[‘) { 34 int pos = str.find(‘]‘, i+1); 35 string text = str.substr(i+1,pos-i-1); 36 int pos1 = str.find(‘(‘, pos+1); 37 int pos2 = str.find(‘)‘, pos+1); 38 string link = str.substr(pos1+1, pos2-pos1-1); 39 string temp = "<a href=\"" + link + "\">" + text + "</a>"; 40 output(temp); 41 i = pos2; 42 } 43 else cout << str[i]; 44 } 45 46 } 47 void solve_l(int cnt) 48 { 49 cout << "<ul>" << endl; 50 for(int i = 0; i < cnt; i++) { 51 int len = s[i].length(); 52 int pos = len; 53 for(int j = 1; j < len; j++) { 54 if(s[i][j] != ‘ ‘) { 55 pos = j; 56 break; 57 } 58 } 59 cout << "<li>"; 60 output(s[i].substr(pos)); 61 cout << "</li>" << endl; 62 } 63 cout << "</ul>" << endl; 64 } 65 void solve_p(int cnt) 66 { 67 cout << "<p>"; 68 for(int i = 0; i < cnt; i++) { 69 output(s[i]); 70 if(i == cnt-1) cout << "</p>"; 71 cout << endl; 72 } 73 } 74 void solve_h() 75 { 76 int len = s[0].length(); 77 int pos = len, cnt = 0; 78 for(int i = 0; i < len; i++) { 79 if(s[0][i] == ‘#‘) cnt++; 80 if(s[0][i] != ‘#‘ && s[0][i] != ‘ ‘) { 81 pos = i; 82 break; 83 } 84 } 85 cout << "<h" << cnt << ">"; 86 output(s[0].substr(pos)); 87 cout << "</h" << cnt << ">" << endl; 88 } 89 int main() { 90 freopen("/Users/kangyutong/Desktop/in.txt","r",stdin); 91 // freopen("/Users/kangyutong/Desktop/out.txt","w", stdout); 92 string line; 93 int cnt = 0; 94 while(getline(cin,line)) { 95 if(line == "") { 96 if(cnt == 0) continue; 97 if(s[0][0] == ‘#‘) solve_h(); 98 else if(s[0][0] == ‘*‘) solve_l(cnt); 99 else solve_p(cnt); 100 cnt = 0; 101 continue; 102 } 103 s[cnt++] = line; 104 } 105 if(cnt) { 106 if(s[0][0] == ‘#‘) solve_h(); 107 else if(s[0][0] == ‘*‘) solve_l(cnt); 108 else solve_p(cnt); 109 } 110 return 0; 111 }