Scrapy项目创建已经目录详情
一、新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
PS C:\\scrapy> scrapy startproject sp1
You can start your first spider with:
cd sp1
scrapy genspider example example.com
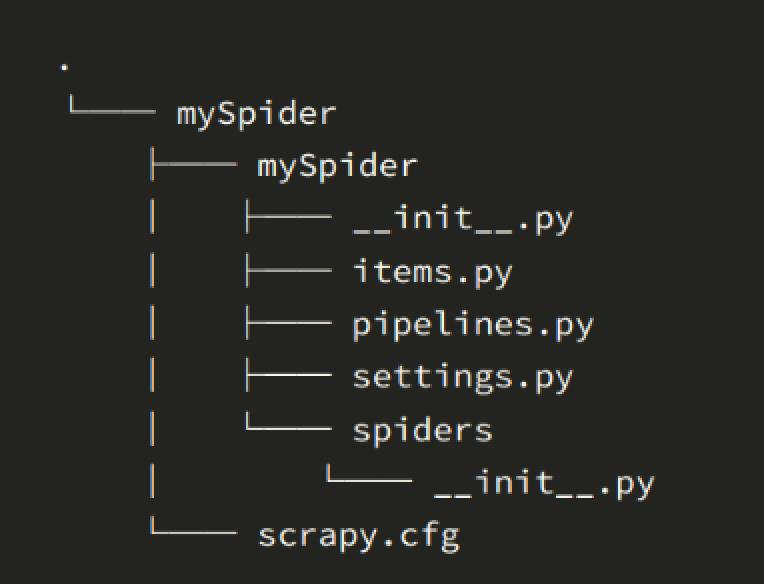
- scrapy.cfg # 项目的配置文件
- sp1/ # 项目的Python模块,将会从这里引用代码
- sp1/items.py # 项目的目标文件
- sp1/pipelines.py # 项目的管道文件用于文件持久化
- sp1/settings.py # 项目的设置文件
- sp1/middlewares.py # 中间件
- sp1/spiders/ # 存储爬虫代码目录
settings.py内容详情
settings.py
# 项目名
BOT_NAME = \'sp1\'
# 爬虫所在的位置
SPIDER_MODULES = [\'sp1.spiders\']
NEWSPIDER_MODULE = \'sp1.spiders\'
# 爬虫是否遵循 robots 协议
ROBOTSTXT_OBEY = False
# 爬虫的并发量 默认 16 个
# CONCURRENT_REQUESTS = 32
# 下载延时 3 s
#DOWNLOAD_DELAY = 3
# 是否禁用cookies 默认不禁用
#COOKIES_ENABLED = False # 表示为禁用
# 请求包头
DEFAULT_REQUEST_HEADERS = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/64.0.3282.186 Safari/537.36\',
\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\',
# 语言可以关闭,按照服务器返回值为准
# \'Accept-Language\': \'en\',
}
# 下载中间件,值越小优先级越高
DOWNLOADER_MIDDLEWARES = {
\'sp1.middlewares.Sp1DownloaderMiddleware\': 543,
}
# 下载后的数据如何处理,存储过程
ITEM_PIPELINES = {
\'sp1.pipelines.FilePipeline\': 300,
}
创建一个爬虫文件
在当前目录下输入命令,将在sp1/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
PS C:\\scrapy> cd sp1
# scrapy genspider关键字 chouti 爬虫名 chouti.com 一般指定站点域名
PS C:\\scrapy\\sp1> scrapy genspider chouti chouti.com
Created spider \'chouti\' using template \'basic\' in module:
sp1.spiders.chouti
通过pycharm调试scrapy项目
1.使用pycharm打开项目
2.在项目等级目录创建main.py
from scrapy.cmdline import execute
import sys
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
print(BASE_DIR)
execute(["scrapy","crawl","chouti"])