人工智能算法综述
Posted 鬼柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能算法综述相关的知识,希望对你有一定的参考价值。
“那一些被认作常识的东西,是不是只是时代的附属品?从整个历史的长河去看待,也许是一些莫名其妙或者残忍至极的怪事而已”
2017-2018 这两年因为一些爆炸式的AI应用,导致又把公众的视野转向这个方向发展,自图灵提出“图灵测试”之后,AI已经爆发了两次热潮,相应的也跌入了两次低谷,目前看应该是进入了第三次的热潮,但是之后是迎来“奇点”,还是第三次低谷,尚不可知。
强人工智能(也就是通用人工智能),或者说机器的自我意识,自然是一个终极目标,但是当我们朝着这个目标行进的时候,总会获得一些小奖励,这些小奖励就是现在的弱人工智能,一些很实用的算法理论跟应用,虽然落地还有一些难度,但是整体趋于成熟,商用的应用已经开始遍地开花,短时间内将会引发全行业AI+,所有业务都会被AI刷新一遍,当然有人会说一堆职业要消亡了,又有很多人要下岗了。但是也同样会创造出更多的职业与岗位。而且自有人类以来,这件事我们也干过不少次了(前三次工业革命),完全不用惊慌,历史的车轮滚滚而行,总会丢下一部分人,又载上另外一部分人,时代就是逆水行舟,不进则退,总要保持学习,保持上进,保持饥渴。如果时代抛弃了你连一句再见也不说,那你就得赶紧加快脚步上去揍它一顿。
--------------(这看上去像一根线)--------------------
闲话少说,为各位呈上各类流弊的算法简介(通俗易懂的说明,具体细节不表),可能会有些地方讲的不对,希望能得到一点友情提醒,我会立马修正。
CNN:卷积神经网络
我在上一篇关于 tensorflow(谷歌开源AI框架)的踩坑日志有说过一点关于卷积神经网络的基本原理。
就是卷积层+N层神经网络BP层(也叫全链接层) 关于 BP的原理我之前有写过一篇了,翻回去看看就有了。
那卷积层具体是什么呢?很像是一个滤镜层,我们知道实际上图像是由每个像素点组成的矩阵,然后每个像素点又可以由 RGB 3原色的数值表示范围是(0-255) 如果做一次灰度处理,那么每个像素点就是由0-255的灰度数值表示。那图像就等同于 一个 2维的 数字矩阵。 当然如果颜色想保留的话,不做灰度处理的话,RGB就等同于3个不同的矩阵,长宽是一样的。里面的数值不同而已。
那我们回到卷积层,就是拿一个卷积核在这个矩阵上滚一遍(矩阵相乘)得出一个新的矩阵。卷积核也是一个小的2维矩阵,不同数值的卷积核,可以对这张图片提取的信息不同,这就是图像的特征, 比如说把一个专门提取竖线的卷积核在原始图片上滚一遍,就能获得一个全部都是竖线的特征图。如果我们要做一个竹子的识别器,肯定要用这个特征了。但是如果要做一个篮球的识别器,就用不上了,用或者不用,这是由BP层决定的。但是提取的工作还是要做的,但是怎么决定卷积核应该是由什么数值构成呢?随机! 因为这个算法比较通用,可以做成识别各种东西,所以卷积核应该是任意特征都能提取的,那只要生成1000,1W ,或者1亿个卷积核,每个都在这个图像上滚一遍,就能提取1亿种特征了。如果最后BP层只用到其中一个特征就能识别竹子或者篮球。那岂不是非常浪费,所以卷积核的数量要根据识别复杂度而定。否则计算量很可怕。
当然CNN里面还有很多细节,比如池化层,归一化,dropout 。
池化层也有几种不同的方法,如果是求均值就是mean pooling,求最大值就是max pooling
池化就是降维比较好理解一点吧,为了减少计算量。
归一化(Normalization,也叫规范化)是为了让数据在网络中传输的时候不要太大,或者太小,或者太稀疏。
早前的一些归一化方法 看这篇 《归一化方法总结》 http://blog.csdn.net/junmuzi/article/details/48917361
后来google 有一篇论文讲了另外一种方式 Batch Normalization http://blog.csdn.net/zhikangfu/article/details/53391840
听说效果不错。
dropout是指随机的把一些特征失效掉来训练这个网络,这样泛化能力比较强。我自己实践过一次,但是感觉训练过程变得更久了,波动更大了。慎用。
全链接层的梯度下降方法也有很多种如:http://blog.csdn.net/xierhacker/article/details/53174558
这里列了一些tensorflow 内置的一些梯度下降优化器 GradientDescentOptimizer,AdagradOptimizer,MomentumOptimizer,AdamOptimizer
CNN的算法里面有很多参数要调,比如说网络的层数,初始学习率,dropout的概率等等,这类统称为超参数
有文章说现在很多CNN的工作都是很枯燥的调参数,因为训练一次周期很长,超参数的调整又跟具体的要识别的东西相关性很强,比如说训练10种类别,跟训练1000种类别的网络深度就是不同的,前面我写踩坑日志的时候就犯了这个错误,拿一个很简单的网络去训练很多种类,结果一直不收敛。loss很大。
当然关于调参数也有一些很实用的实践性经验分享,大家可以自行去找找。这里我就不细说了。
虽然我们刚才说的都是图像上的,但是文字跟音频也可以转化成这种输入,类似说1*N的矩阵。
----------------------(这看上去跟第一根线没什么区别)----------------------
RL:强化学习(reinforcement learning)
关于RL的详细内容可以看 Deepmind 的公开课
这里给大家分享一个B站带中文字幕的视频,每课100分钟左右,总共10课,16个小时也能看完,不过因为相对比较晦涩,我建议是不要一次性看完,不然一脸懵逼的进去,一脸懵逼的出来。遇到不懂的就去问问,懂了再继续看。 https://www.bilibili.com/video/av9831889/
强化学习核心的原理是:
造一个agent(智能代理者)跟环境(state)交互(action)然后根据获得的反馈(reward)反复训练后,这个agent可以在遇到任意的state时都能选择最优的决策(action),这个最优的决策会在未来带来最大化的reward。
RL解决的问题是连续决策问题,就是有一系列的决策之后才会获得奖励的现实问题。比方说某baby 3岁,暂且先叫A酱,A酱还不会拿杯子喝东西。我们知道最优策略就是
:靠近杯子,拿起来,倒进嘴巴里。
但是她一开始的时候并不知道看到一个杯子在远处,究竟是应该靠近,还是远离。而且就算反复做了这2件事,也没有一些立即奖励给她(喝到东西)。所以说奖励是滞后的,但是我们希望可以对动作的打分,根据分数的高低让智能体选出最佳的决策,比方说 靠近杯子10分,远离杯子-10分。如果每一步都有这样的标量作为衡量标准的话,那么她就可以知道要获得奖励的最优策略是什么了,当然有些动作在不同的场景下会导致不同的效果,所以这里的打分要针对 state-action pair(不同状态对应不同的动作) 评分。
所以RL的作用就是经过反复的训练,为每对state-action 提供一个分数。这就Value based(基于分数的算法,其中的一种的RL算法实现方式)。
如果先假设 最终的奖励分数是 100分。那么究竟前一步应该分配多少分呢?然后前前一步又是多少?这里就用到了贝尔曼方程
具体细节可以看这篇 http://blog.csdn.net/VictoriaW/article/details/78839929
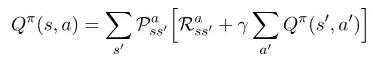
s :state
a:action
Q就是我上面讲的分数。然后Qπ 指的就是最优策略下的分数函数。
P是指状态s下决定某动作a之后 =》下一个状态s的转移概率。(比方说A酱虽然见到了杯子,然后她使用了动作a1(拿起来)但是不一定能够成功,这里有个转移概率P)。
R是指立即奖励。
 指折扣率,是一个0-1的数,就是指未来的Q值对当前Q的影响有多少,如果是1的话就是100%影响。
指折扣率,是一个0-1的数,就是指未来的Q值对当前Q的影响有多少,如果是1的话就是100%影响。
这里我们可以看到,当前的Q值是由两部分组成,当前R值+下一个状态的Q值。
假设 折扣率这里是0.5,最终的奖励分数是 100分。
反过来推导的话,A酱在喝到杯中物的时候 Q值等于R值,因为没有下一个状态了。在往前一个动作 (拿起杯子)因为只有1个动作,而且立即奖励R=0,所以Q值等于 0+ 0.5*100=50 。
然后再往前面一步,状态1(见到杯子)的时候 选择 (靠近),所以Q值 是 0+0.5*(0+ 0.5*100)=25
这是我们通过已知最优策略然后用贝尔曼方程反推Q值,这样便于理解Q值的含义。
虽然不知道最优策略,但是如果我们有一个所有状态所有动作的 记录Q值的表,只要反复通过上面的过程推导就能知道这个大表的所有值,最终就能通过这个大表知道最优策略。
这就是Q-learning 算法的逻辑。
当然Q-learning是不实用的,因为如果state 跟action有非常多,这个表数据量要爆炸的。
所以后续又发展好多算法,我推荐读一下DQN相关的算法。
RL很早很早就有了。
强化学习的历史发展
- 1956年Bellman提出了动态规划方法。
- 1977年Werbos提出只适应动态规划算法。
- 1988年sutton提出时间差分算法。
- 1992年Watkins 提出Q-learning 算法。
- 1994年rummery 提出Saras算法。
- 1996年Bersekas提出解决随机过程中优化控制的神经动态规划方法。
- 2006年Kocsis提出了置信上限树算法。
- 2009年kewis提出反馈控制只适应动态规划算法。
- 2014年silver提出确定性策略梯度(Policy Gradents)算法。
- 2015年Google-deepmind 提出Deep-Q-Network算法。
因为alphaGo 就是基于RL的,主要用了蒙特卡罗树搜索算法 (MCTS)然后RL这两年又被大神们推进了好多优化。
我摘一段放这里说明一下实现RL算法的几种类别:
- Model-free:不尝试去理解环境, 环境给什么就是什么,一步一步等待真实世界的反馈, 再根据反馈采取下一步行动。
-
Model-based:先理解真实世界是怎样的, 并建立一个模型来模拟现实世界的反馈,通过想象来预判断接下来将要发生的所有情况,然后选择这些想象情况中最好的那种,并依据这种情况来采取下一步的策略。它比 Model-free 多出了一个虚拟环境,还有想象力。
-
Policy based:通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动。
-
Value based:输出的是所有动作的价值, 根据最高价值来选动作,这类方法不能选取连续的动作。
-
Monte-carlo update:游戏开始后, 要等待游戏结束, 然后再总结这一回合中的所有转折点, 再更新行为准则。
-
Temporal-difference update:在游戏进行中每一步都在更新, 不用等待游戏的结束, 这样就能边玩边学习了。
-
On-policy:必须本人在场, 并且一定是本人边玩边学习。
- Off-policy:可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则。
RL现阶段比较实用的算法是:
DQN,DDPG, A3C,DPPO 等
摘一张图大家看看

横轴是训练次数,纵轴是超过人类水平百分比,100%就是等同于平均的人类玩游戏的水平,在57款雅达利游戏中的平均表现。
2017-2018年 一些很有趣的开源应用示例,以及使用的算法
CNN :图像识别 人脸识别 风格迁移
RL :alphaGO 游戏代打 机器人控制 阿里商品推荐系统
GANs:风格迁移 草图生成实体图 猫脸转狗脸 去掉图像遮挡 年龄转移 超分辨率
RNN LSTM:翻译模型,生成古诗,生成对联,PSD生成html代码
下一篇传送门:人工智能算法综述 (二)
以上是关于人工智能算法综述的主要内容,如果未能解决你的问题,请参考以下文章