LINUX网络编程Makefile文件
Posted dr1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LINUX网络编程Makefile文件相关的知识,希望对你有一定的参考价值。
《Linux网络编程》(第二版) 第2章的一些读书笔记 ↓
Makefile:在一个含有较多文件的工程中,定义一系列规则来指定编译文件的顺序,可用于管理工程。
Makefile指定了工程中的哪些源文件需要编译以及如何编译、需要创建那些库文件以及如何创建这些库文件、如何最后产生我们想要的可执行文件。为工程编写Makefile 的好处是能够使用一行命令来完成“自动化编译”,编译整个工程你所要做的唯一的一件事就是在shell 提示符下输入make命令,整个工程就完全自动编译。
首先来看一下Linux下的GCC(GNU Compiler Collection):这是一个工具集,包含gcc(跟大写的不一样), g++等编译器和ar, nm等工具集。
GCC编译器对程序的编译有4个阶段:预编译 -> 编译和优化 -> 汇编 -> 链接,下面以c代码作例子:
源代码(*.c) 【预编译 -E】 预处理后的代码(*.i) 【编译和优化 -S】 汇编代码(*.s) 【汇编 -c】 目标文件(*.o) 【链接】 可执行文件
预编译过程是将程序中引用的头文件包含进源代码中,并对一些宏进行替换
编译和优化通常是翻译成汇编语言,汇编与机器操作码之间有一对一的关系
目标文件是指经过编译器的编译和汇编生成的CPU可识别的二进制代码,但是其中的一些函数过程没有相关的指示和说明,所以一般不能执行
目标文件需要用某种方式组合起来才可以运行,这就是链接
一些命令选项(假设文件名为hello.c):
gcc hello.c /* 生成可执行文件,名字为默认的 a.out。gcc后面的不只可以是*.c文件,同样也可以是*.o或其他,以下的选项也是如此,只要被处理的文件的阶段在生成文件的阶段之前即可 */
gcc -o hello hello.c /* 生成可执行文件,名字接在-o后面,即hello */
gcc -E hello.c /* 经过预编译的过程,默认名字格式,产生了hello.i */
gcc -S hello.c /* 经过了预编译和编译优化的过程,名字为默认的 hello.s */
gcc -c hello.c /* (常用) 经过了预编译和编译优化以及汇编的过程,产生了目标文件,名字为默认的 hello.o */
其他选项:
gcc -D宏名 , gcc -DOS_LINUX 则相当于在预编译的时候添加了 #define OS_LINUX,即当出现 #ifdef OS_LINUX 的时候,就会满足条件
gcc -Idir (大写i),将头文件的搜索路径扩大,包含dir目录 (后面会用到)
gcc -Ldir,将链接时使用的链接库搜索路径扩大,包含dir目录,gcc优先使用共享程序库
gcc -static,仅选用静态程序库进行链接
gcc -On,n为数字,优化程序执行速度和占用空间(同时会加长编译速度),常用的是2,gcc -O2
了解了一些基本选项之后,给出一个小项目的例子,分别用手动编译和Makefile“自动化编译”的方式来说明:
目录结构:
project/
main.c
add/
add_int.c
add_float.c
sub/
sub_int.c
sub_float.c
main.c:可以注意到add.h和sub.h并没有跟main.c同一级目录,这时就要用到 gcc -I目录 的选项了,扩大头文件搜索路径,才找到真正的*.h。至于没有定义的add_int等函数,需要在链接的时候同时包含有具体定义的.o文件
/* main.c */
#include <stdio.h>
#include "add.h"
#include "sub.h"
int main(void){
int a = 10, b = 12;
float x = 1.23456, y = 9.87654321;
printf("int a+b IS:%d\\n",add_int(a,b));
printf("int a-b IS:%d\\n",sub_int(a,b));
printf("float a+b IS:%f\\n",add_float(x,y));
printf("float a-b IS:%f\\n",sub_float(x,y));
return 0;
}
add/add.h
/* add.h */ #ifndef __ADD_H__ #define __ADD_H__ extern int add_int(int a, int b); extern float add_float(float a, float b); #endif
add/add_int.c
/* add_int.c */
int add_int(int a, int b){
return a+b;
}
add/add_float.c
/* add_float.c */
float add_float(float a, float b){
return a+b;
}
sub目录略。
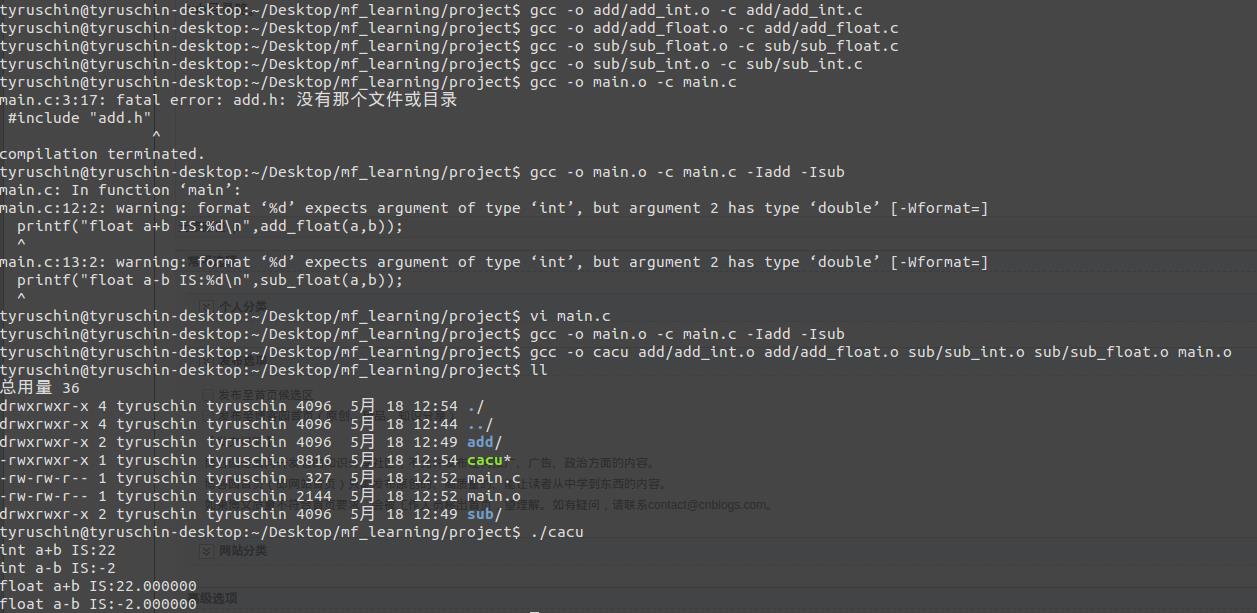
根据书上的代码,将c文件转成目标文件,然后链接上。其中,如果在编译main.c的时候,由于头文件找不到,所以必须添加上 -Iadd 和 -Isub 才可以找到,书上的例子有误。
可以看到,编译一个小的项目就需要如此多的步骤:
gcc -o add/add_int.o -c add/add_int.c gcc -o add/add_float.o -c add/add_float.c gcc -o sub/sub_float.o -c sub/sub_float.c gcc -o sub/sub_int.o -c sub/sub_int.c gcc -o main.o -c main.c -Iadd -Isub gcc -o cacu add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o ./cacu
虽然,可以通过gcc的默认规则,使用如下命令也可以生成可执行文件:
gcc -o cacu1 add/add_int.c add/add_float.c sub/sub_int.c sub/sub_float.c main.c -Iadd -Isub
但是当频繁修改源文件或者当项目中的文件比较多,关系比较复杂的时候,用gcc直接编译就会变得非常困难。
于是我们应该采用Makefile文件的编写,通过make命令将多个文件编译为可执行文件。
make通过解析Makefile文件中的规则,可以自动执行相应的脚本,以下就是一个简单的Makefile文件:
# 第一行item的":"左边为make命令在正确操作之后默认生成的文件,故生成cacu2,依赖于":"右边的文件。 # 每一个item都是一个规则 # 在从左往右扫描的过程中,如果不存在某个文件,则跳到生成它的规则 # 注意底下的一行,它是以tab键开头的,不能是空格,表示满足所有依赖的情况下,执行那几行指令 cacu2:add_int.o add_float.o sub_int.o sub_float.o main.o gcc -o cacu2 add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o add_int.o:add/add_int.c add/add.h gcc -o add/add_int.o -c add/add_int.c add_float.o:add/add_float.c add/add.h gcc -o add/add_float.o -c add/add_float.c sub_int.o:sub/sub_int.c sub/sub.h gcc -o sub/sub_int.o -c sub/sub_int.c sub_float.o:sub/sub_float.c sub/sub.h gcc -o sub/sub_float.o -c sub/sub_float.c main.o:main.c add/add.h sub/sub.h gcc -o main.o -c main.c -Iadd -Isub # 清理的规则,可以使用make clean来主动执行 clean: rm -f cacu2 add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o
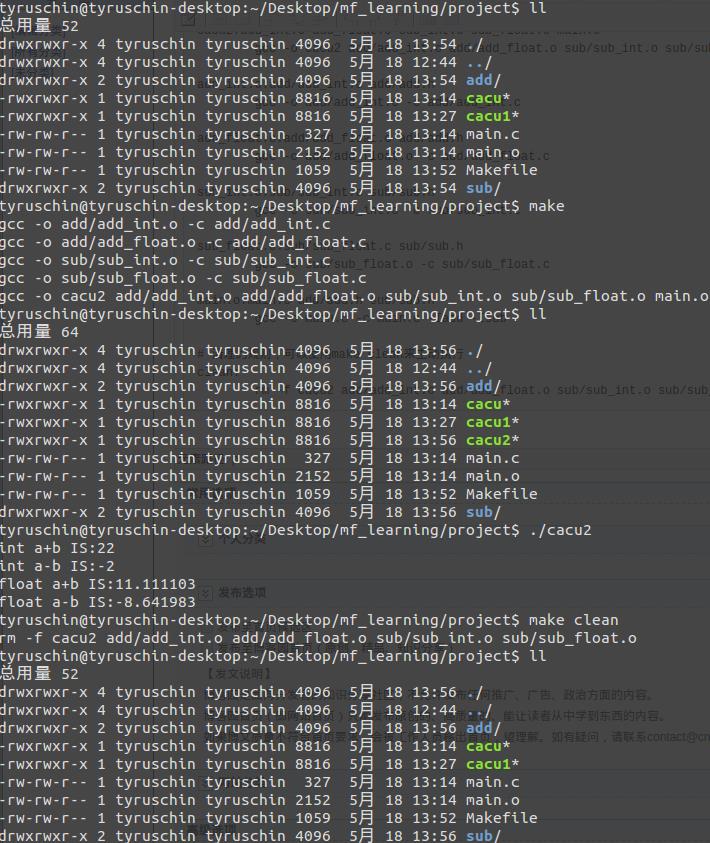
如图所示,在安装了make的情况下,通过编写Makefile后执行make命令,系统会自动执行gcc的一些命令,生成了cacu2这个可执行文件;然后make clean之后,便删除了本次make生成的内容。
回到Makefile文件中,事实上默认情况下,make会直接执行第一个规则,即cacu2的规则。系统先检查依赖,并在成功之后执行下述命令:
$(CC) -o $(TARGET) $(OBJS) $(CFLAGS)
如何理解?上面的命令其实等价于下面这一条,只是用了变量扩展
gcc -o cacu2 add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o -Iadd -Isub -O2
CC = gcc , TARGET = cacu2 , OBJS = add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o , CFLAGS = -Iadd -Isub -O2
同理,make clean命令是这样的:
-$(RM) $(TARGET) $(OBJS)
等价于rm -f cacu2 add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o,注意到RM变量前面有个 “-” 号,它表示当操作失败时不报错,命令继续执行。
总结一下要注意的点:
- Makefile由若干条规则组成,默认执行第一条,规则的基本格式是:
TARGET...:DEPENDEDS(依赖)... COMMAND ... ... # 一行一条,如果一条命令一行不够写,则需要用反斜杠分节 - 命令行必须以Tab键(不能是空格)开始,make程序把出现在一条规则之后的所有连续的以Tab键开始的行作为命令行处理
- 依赖项之间的顺序按照自左向右的顺序检查或者执行,如果检查无此文件时,则需要跳到相应(同名)的规则去产生这个文件,但如果没有这样一个规则,则报错。

- make命令执行的时候会根据文件的时间戳判定是否执行相关的命令,并且执行依赖于此项的规则。例如在某次make之后只修改main.c文件,再次用make命令编译的时候,就会只编译main.c并且执行规则,重新连接程序。
- 执行非默认的规则:make XXX(规则名),如make cacu
- 模式匹配 (使用自动变量来简化规则书写),具体在后面有说到,以下是一个例子:
main.o:main.c gcc -o main.o -c main.c -Iadd -Isub # 可以替换成以下写法 main.o:%o:%c gcc -o $@ -c $< -Iadd -Isub # %o:%c 表示将TARGET域的扩展名替换成.c,$@表示TARGET域的内容,$<表示依赖项的结果
Makefile中使用变量:
为啥引入变量? 在某个规则中添加一项依赖,既要在依赖项中填写,又要在命令行中填写,很不方便。
变量有3种:
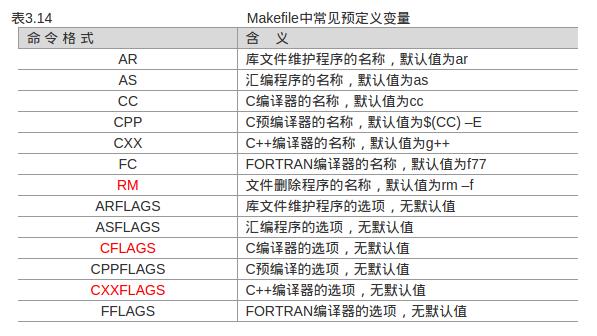
1、预定义变量:Makefile中已经定义的变量,用户可以直接使用这些变量,不用进行定义。(图来自此链接) 使用方法与自定义变量一样,见3
2、自动变量:在编译语句中,会经常出现目标文件和依赖文件,自动变量代表这些目标文件和依赖文件。

3、用户自定义变量:
定义方法: 变量名 = 值。 eg, OBJS = add_int.o add_float.o ... # 一行代表一个变量
使用方法: $(变量名)。 eg, $(OBJS)
/* 此处重写一份Makefile */
# 定义一些变量 CC = gcc CFLAGS = -Iadd -Isub -O2 TARGET = cacu3 OBJS = add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o # $(CC) -o $(TARGET) $(OBJS) $(CFLAGS) $(TARGET):$(OBJS) $(CC) -o $(TARGET) $(OBJS) $(CFLAGS) $(OBJS):%o:%c $(CC) -o $@ -c $< $(CFLAGS) clean: -$(RM) $(TARGET) $(OBJS)
在此处运用了定义变量的方式,简化了文本的维护。
$(CC) -o $@ -c $< $(CFLAGS) 采用了所谓的“静态模式”的规则,相当于是多条规则,规则如上面所示。
搜索路径:
在大的系统中,存在很多目录,手动用-I的方法添加目录不方便,所以用到了VPATH变量,它可以自动找到指定文件的目录并添加到文件上。
使用方法:VPATH = path1:path2:...:.
用冒号(:)隔开,记得在最后加上当前目录 .
这样会出现一个问题:目标文件会放到当前的目录下,污染环境!所以,自定义一个变量,创建以该变量为名字的目录,将*.o文件放进去。
/* 此处再重写一份Makefile */
# 发现一个严重的错误,因为Makefile文件行末没有终结符,所以最好不要盲目在后面放注释,而应该换行。。 # 定义一些变量,并引入VPATH CC = gcc CFLAGS = -Iadd -Isub -O2 # 将所有的目标文件放置在这个文件夹中 OBJSDIR = objs VPATH = add:sub:. TARGET = cacu4 # OBJS = add/add_int.o add/add_float.o sub/sub_int.o sub/sub_float.o main.o OBJS = add_int.o add_float.o sub_int.o sub_float.o main.o # 定义了VPATH之后,OBJS中的文件夹名就不用写了 # 先检查目录是否存在 $(TARGET):$(OBJSDIR) $(OBJS) $(CC) -o $(TARGET) $(OBJSDIR)/*.o $(CFLAGS) $(OBJS):%o:%c $(CC) -o $(OBJSDIR)/$@ -c $< $(CFLAGS) # mkdir -p 创建所有遗失的父目录 $(OBJSDIR): mkdir -p ./$@ clean: -$(RM) $(TARGET) $(OBJSDIR)/*.o
自动推导规则:使用命令make编译扩展名为c的C语言文件的时候,源文件的编译规则不用明确给出。按照默认的规则,通过依赖中的.o文件,找到对应的.c文件将其编译成目标文件用于满足依赖。
# 使用命令make编译扩展名为c的C语言文件的时候,源文件的编译规则不用明确给出。(会使用一个默认的编译规则) -- make的隐含规则 CC = gcc CFLAGS = -Iadd -Isub -O2 VPATH = add:sub:. TARGET = cacu5 OBJS = add_int.o add_float.o sub_int.o sub_float.o main.o $(TARGET):$(OBJS) $(CC) -o $(TARGET) $(OBJS) $(CFLAGS) clean: -$(RM) $(TARGET) $(OBJS)
递归make:
当有多人在多个目录进行程序开发,并且每个人负责一个模块,而文件在相对独立的目录中,这时由同一个Makefile维护代码的编译会十分蹩脚。
1、递归调用的方式:make命令有递归调用的作用,它可以递归调用每个子目录的Makefile。
假设目录add和sub中都有Makefile,则可以用以下两种方法(第二种比较好):
add:
cd add && $(MAKE)
add:
$(MAKE) -C add
都表示进入add目录,然后执行make命令
2、总控Makefile:调用$(MAKE) -C即可。如果总控Makefile中的一些变量需要传递给下层的Makefile,可以使用export命令。
以下是总控的Makefile代码实现:
export CC = gcc
CFLAGS = -Iadd -Isub -O2
TARGET = cacu6
export OBJSDIR = ${shell pwd}/objs
$(TARGET):$(OBJSDIR) main.o
$(MAKE) -C add
$(MAKE) -C sub
$(CC) -o $(TARGET) $(OBJSDIR)/*.o
main.o:main.c
$(CC) -o $(OBJSDIR)/$@ -c $^ $(CFLAGS)
$(OBJSDIR):
mkdir -p $(OBJSDIR)
clean:
-$(RM) $(TARGET) $(OBJSDIR)/*.o
以上代码与书上有一些不同,注意CC需要export到子Makefile中,否则会默认使用cc而不是gcc
${shell pwd}表示执行shell中的pwd命令,即获取当前路径
生成的目标文件(*.o)全都放进项目目录的objs目录下
以下是子目录Makefile:
add/Makefile:
OBJS = add_int.o add_float.o all:$(OBJS) $(OBJS):%o:%c $(CC) -o $(OBJSDIR)/$@ -c $< -O2 clean: -$(RM) $(OBJS)
sub/Makefile:
OBJS = sub_int.o sub_float.o all:$(OBJS) $(OBJS):%o:%c $(CC) -o $(OBJSDIR)/$@ -c $< -O2 clean: -$(RM) $(OBJS)
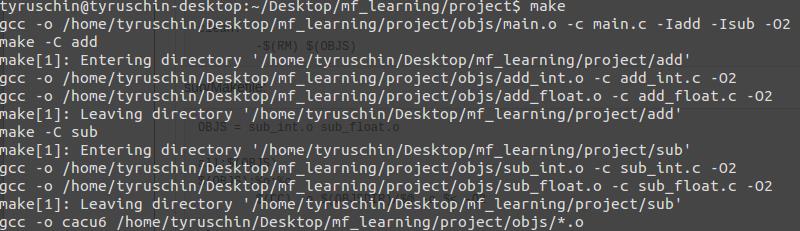
结果如下图:
3、Makefile中的函数
- 获取匹配模式的文件名 wildcard:查找当前目录下所有符合模式PATTERN的文件名,返回值是以空格分割的(符合模式的)文件名列表。 原型:$(wildcard PATTERN) , 如:$(wildcard *.c)
- 模式替换函数 patsubst:相当于replace函数,查找字符串text中按照空格分开的词,将符合模式的字符串替换成别的字符串。 原型:$(patsubst pattern, replacement, text), 如:$(patsubst %.c, %.o, $(wildcard *.c) )
- 循环函数 foreach:在LIST中取出每个用空格分割的VAR单词,然后执行TEXT表达式,处理结束后输出。 原型:$(foreach VAR, LIST, TEXT), 如:$(foreach dir, $(DIRS), $(wildcard $(dir)/*.c) )
以下是根据书上的Makefile文件改写的一个用函数的Makefile文件:
CC = gcc CFLAGS = -Iadd -Isub -O2 TARGET = cacu7 DIR = add sub . FILES = $(foreach dir, $(DIR), $(wildcard $(dir)/*.c) ) OBJS = $(patsubst %c, %o, $(FILES)) $(TARGET):$(OBJS) main.o $(CC) -o $@ $^ -O2 $(OBJS):%o:%c $(CC) -o $@ -c $< $(CFLAGS) clean: -$(RM) $(TARGET) $(OBJS)

----- 分割线 -----
以上的Makefile例子和整个项目代码可以参见:TyrusChin - Github
以上是关于LINUX网络编程Makefile文件的主要内容,如果未能解决你的问题,请参考以下文章