6C_宏定义与预处理函数与函数库
Posted 常瑟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了6C_宏定义与预处理函数与函数库相关的知识,希望对你有一定的参考价值。
C语言预处理理论
由源码到可执行程序的过程
- 源码.c->(编译)->elf可执行程序
- 源码.c->(编译)->目标文件.o->(链接)->elf可执行程序
- 源码.c->(编译)->汇编文件.S->(汇编)->目标文件.o->(链接)->elf可执行程序
- 源码.c->(预处理)->预处理过的.i源文件->(编译)->汇编文件.S->(汇编)->目标文件.o->(链接)->elf可执行程序
- 预处理用预处理器,编译用编译器,汇编用汇编器,链接用链接器,这几个工具再加上其他一些额外的会用到的可用工具,合起来叫编译工具链。gcc就是一个编译工具链。
预处理的意义
- 编译器本身的主要目的是编译源代码,将C的源代码转化成.S的汇编代码。编译器聚焦核心功能后,就剥离出了一些非核心的功能到预处理器去了。
- 预处理器帮编译器做一些编译前的杂事。
编程中常见的预处理
- #include(#include <>和#include ""的区别):#include< > 引用的是编译器的类库路径里面的头文件; #include" " 引用的是你程序目录的相对路径中的头文件。
- 注释;
- #if #elif #endif #ifdef
- 宏定义;
gcc中只预处理不编译的方法
- gcc编译时可以给一些参数来做一些设置,譬如gcc xx.c -o xx可以指定可执行程序的名称;譬如gcc xx.c -c -o xx.o可以指定只编译不链接,也可以生成.o的目标文件。
- gcc -E xx.c -o xx.i可以实现只预处理不编译。一般情况下没必要只预处理不编译,但有时候这种技巧可以用来帮助我们研究预处理过程,帮助debug程序。
- 总结:宏定义被预处理时的现象有:第一,宏定义语句本身不见了(可见编译器根本就不认识#define,编译器根本不知道还有个宏定义);第二,typedef重命名语言还在,说明它和宏定义是有本质区别的(说明typedef是由编译器来处理而不是预处理器处理的);


C语言预处理代码实战
头文件包含
- #include <> 和 #include""的区别:<>专门用来包含系统提供的头文件(就是系统自带的,不是程序员自己写的),""用来包含自己写的头文件;更深层次来说:<>的话C语言编译器只会到系统指定目录(编译器中配置的或者操作系统配置的寻找目录,譬如在ubuntu中是/usr/include目录,编译器还允许用-I来附加指定其他的包含路径)去寻找这个头文件(隐含意思就是不会找当前目录下),如果找不到就会提示这个头文件不存在。
- ""包含的头文件,编译器默认会先在当前目录下寻找相应的头文件,如果没找到然后再到系统指定目录去寻找,如果还没找到则提示文件不存在。
- 总结+注意:规则虽然允许用双引号来包含系统指定目录,但是一般的使用原则是:如果是系统指定的自带的用<>,如果是自己写的在当前目录下放着用"",如果是自己写的但是集中放在了一起专门存放头文件的目录下将来在编译器中用-I参数来寻找,这种情况下用<>。
- 头文件包含的真实含义就是:在#include<xx.h>的那一行,将xx.h这个头文件的内容原地展开替换这一行#include语句。过程在预处理中进行。
注释
- 注释是给人看的,不是给编译器看的。
- 编译器既然不看注释,那么编译时最好没有注释的。实际上在预处理阶段,预处理器会拿掉程序中所有的注释语句,到了编译器编译阶段程序中其实已经没有注释了。
条件编译
- 有时候我们希望程序有多种配置,我们在源代码编写时写好了各种配置的代码,然后给个配置开关,在源代码级别去修改配置开关来让程序编译出不同的效果。
- 条件编译中用的两种条件判定方法分别是#ifdef 和 #if
- 区别:#ifdef XXX判定条件成立与否时主要是看XXX这个符号在本语句之前有没有被定义,只要定义了这个符号就是成立的(我们可以直接#define XXX或者#define XXX 12或者#define XXX YYY)。
- 它的格式是:#if (条件表达式),它的判定标准是()中的表达式是否为true还是flase,跟C中的if语句有点像。


宏定义
宏定义的规则和使用解析
- 宏定义的解析规则就是:在预处理阶段由预处理器进行替换,这个替换是原封不动的替换。
- 宏定义替换会递归进行,直到替换出来的值本身不再是一个宏为止。
- 一个正确的宏定义式子本身分为3部分:第一部分是#dedine ,第二部分是宏名 ,剩下的所有为第三部分。
- 宏可以带参数,称为带参宏。带参宏的使用和带参函数非常像,但是使用上有一些差异。在定义带参宏时,每一个参数在宏体中引用时都必须加括号,最后整体再加括号,括号缺一不可。
宏定义示例1:MAX宏,求2个数中较大的一个
- #defineMax(a,b) (((a)>(b)) ? (a) : (b))
- 关键:
- 第一点:要想到使用三目运算符来完成。
- 第二点:注意括号的使用
宏定义示例2:SEC_PER_YEAR,用宏定义表示一年中有多少秒
- #defineyear (365UL*24*60*60)
- 关键:
- 第一点:当一个数字直接出现在程序中时,它的是类型默认是int
- 第二点:一年有多少秒,这个数字不知道是否超过了int类型存储的范围
#include <stdio.h>
#define M 10
#define N M
#define X(a,b) ((a)*(b))
#define Max(a,b) (((a)>(b)) ? (a) : (b))
//#define year (365*24*60*60)UL //在Linux中GCC测试出错
#define year (365UL *24*60*60) //在Linux中GCC测试正确
int main(void)
{
int i = N;
int k, x, y, m, n;
printf("%d\\n",i); //输出:10
k = X(3+i, i - 8); //解析为:k = ((3+i)*(i - 8));
printf("k = %d\\n",k); //输出:26
m = Max(3,5); //解析为:m = (((3)>(5)) ? (3) : (5));
printf("Max is %d\\n",m);//输出:5
n = year; //解析为:n = (365UL*24*60*60);
printf("%d\\n", n); //输出:31536000
return 0 ;
}
带参宏和带参函数的区别(宏定义的缺陷)
- 宏定义是在预处理期间处理的,而函数是在编译期间处理的。这个区别带来的实质差异是:宏定义最终是在调用宏的地方把宏体原地展开,而函数是在调用函数处跳转到函数中去执行,执行完后再跳转回来。
- 注:宏定义和函数的最大差别就是:宏定义是原地展开,因此没有调用开销;而函数是跳转执行再返回,因此函数有比较大的调用开销。所以宏定义和函数相比,优势就是没有调用开销,没有传参开销,所以当函数体很短(尤其是只有一句话时)可以用宏定义来替代,这样效率高。
- 带参宏和带参函数的一个重要差别就是:宏定义不会检查参数的类型,返回值也不会附带类型;而函数有明确的参数类型和返回值类型。当我们调用函数时编译器会帮我们做参数的静态类型检查,如果编译器发现我们实际传参和参数声明不同时会报警告或错误。
- 注:用函数的时候程序员不太用操心类型不匹配因为编译器会检查,如果不匹配编译器会报警;用宏的时候程序员必须很注意实际传参和宏所希望的参数类型一致,否则可能编译不报错但是运行有误。
- 总结:宏和函数各有千秋,各有优劣。总的来说,如果代码比较多用函数适合而且不影响效率;但是对于那些只有一两句话的函数开销就太大了,适合用带参宏。但是用带参宏又有缺点:不检查参数类型。
内联函数和inline关键字
- 内联函数通过在函数定义前加inline关键字实现,他既有函数的优点,又有带参宏的优点。
- 内联函数本质上是函数,所以有函数的优点(内联函数是编译器负责处理的,编译器可以帮我们做参数的静态类型检查);但是他同时也有带参宏的优点(不用调用开销,而是原地展开)。所以几乎可以这样认为:内联函数就是带了参数静态类型检查的宏。
- 当我们的函数内函数体很短(譬如只有一两句话)的时候,我们又希望利用编译器的参数类型检查来排错,我还希望没有调用开销时,最适合使用内联函数。

宏定义来实现条件编译(#define #undef #ifdef)
- 程序有DEBUG版本和RELEASE版本,区别就是编译时有无定义DEBUG宏。
#include <stdio.h>
#define DEBUG //声明一个宏
#undef DEBUG //注销一个宏(如果前面有)
#ifdef DEBUG
#define debug(x) printf(x)
#else
#define debug(x)
#endif
int main(void)
{
debug("this is debug info\\n");
printf("hello world\\n");
return 0
}
函数的本质
C语言为什么会有函数
- 整个程序分成多个源文件,一个文件分成多个函数,一个函数分成多个语句,这就是整个程序的组织形式。这样组织的好处在于:分化问题、便于编写程序、便于分工。
- 函数的出现是人(程序员和架构师)的需要,而不是机器(编译器、CPU)的需要。
- 函数的目的就是实现模块化编程。说白了就是为了提供程序的可移植性。
函数书写的一般原则:
- 遵循一定的格式。函数的返回类型、函数名、参数列表等。
- 一个函数只做一件事。函数不能太长也不宜太短,原则上一个函数只做一件事情。
- 传参不宜过多。在ARM体系下,传参不宜超过4个,如果传参需要多个返回值,则考虑结构体打包。
- 尽量少碰全局变量。函数最好用传参返回值和外部交换数据,不要用全局变量(不利于函数移植);
函数是动词、变量是名词(面相对象中分别叫方法和成员变量)
- 函数将来被编译成可执行代码段,变量(主要指全局变量)经过编译后变成数据或者在运行时变成数据。一个程序的运行需要代码和数据两方向的结合才能完成。
- 代码和数据需要彼此配合,代码是为了加工数据,数据必须借助代码来起作用。拿现实中的工厂来比喻:数据是原材料,代码是加工流水线。名词性的数据必须经过动词性的加工才能变成最终我们需要的产出的数据。这个加工的过程就是程序的执行过程。
函数的实质是:数据处理器
- 程序的主体是数据,也就是说程序运行的主要目标是生成目标数据,我们写代码也是为了目标数据。我们如何得到目标数据?必须2个因素:原材料+加工算法。原材料就是程序的输入数据,加工算法就是程序。
- 程序的编写和运行就是为了把原数据加工成目标数据,所以程序的实质就是一个数据处理器。
- 函数就是程序的一个缩影,函数的参数列表其实就是为了给函数输入原材料数据,函数的返回值和输出型参数就是为了向外部输出目标数据,函数的函数体里的那些代码就是加工算法。
- 函数在静止没有执行(乖乖的躺在硬盘里)的时候就好象一台没有开动的机器,此时只占一些存储空间但是并不占用资源(CPU+内存);函数的每一次运行就好象机器的每一次开机运行,运行时需要耗费资源(CPU+内存),运行时可以对数据加工生成目标数据;函数运行完毕会释放占用的资源。
- 整个程序的运行其实就是很多个函数相继运行的连续过程。
函数的基本使用
函数三要素:定义、声明、调用
- 函数的定义就是函数体、函数声明是函数原型、函数调用就是使用函数
- 函数定义是函数的根本,函数定义中的函数名表示了这个函数在内存中的首地址,所以可以用函数名来调用执行这个函数(实质是指针解引用访问);函数定义中的函数体是函数的执行关键,函数将来执行时主要就是执行函数体。所以一个函数没有定义就是无基之塔。
- 函数声明的主要作用是告诉编译器函数的原型
- 函数调用就是调用执行一个函数。
函数原型和作用
- 函数原型就是函数的声明,说白了就是函数的函数名、返回值类型、参数列表。
- 函数原型的主要作用就是给编译器提供原型,让编译器在编译程序时帮我们进行参数的静态类型检查
- 必须明白:编译器在编译程序时是以单个源文件为单位的(所以一定要在哪里调用在哪里声明),而且编译器工作时已经经过预处理处理了,最最重要的是编译器编译文件时是按照文件中语句的先后顺序执行的。
- 编译器从源文件的第一行开始编译,遇到函数声明时就会收到编译器的函数声明表中,然后继续向后。当遇到一个函数调用时,就在我的本文件的函数声明表中去查这个函数,看有没有原型相对应的一个函数(这个相对应的函数有且只能有一个)。如果没有或者只有部分匹配则会报错或报警告;如果发现多个则会报错或报警告(函数重复了,C语言中不允许2个函数原型完全一样,这个过程其实是在编译器遇到函数定义时完成的。所以函数可以重复声明但是不能重复定义)
递归函数
什么是递归函数
- 递归函数就是函数中调用了自己本身这个函数的函数。
- 递归函数和循环的区别。递归不等于循环
- 递归函数解决问题的典型就是:求阶乘、求斐波那契数列
#include <stdio.h>
#include <assert.h>
int jiecheng(int n);
int Fib1(int n);
int main(void)
{
int a,fib;
a = jiecheng(6);
printf("%d\\n",a);
fib = Fib1(6);
printf("%d\\n",fib);
return 0;
}
int jiecheng(int n)
{
// 传参错误校验
//assert的作用是现计算表达式 expression ,如果其值为假(即为0),
//那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。
assert( n>= 1);
if (n == 1)
{
return 1;
}
else
{
return (n * jiecheng(n-1));
}
}
int Fib1(int n)
{
assert( n>= 0);
if((n == 0) || (n == 1))
{
return n;
}
else
{
return (Fib1(n-1) + Fib1(n-2));
}
}
递归调用原理
- 实际上递归函数是在栈内存上递归执行的,每次递归执行一次就需要耗费一些栈内存。
- 栈内存的大小是限制递归深度的重要因素。
使用递归函数的原则:收敛性、栈溢出
- 收敛性就是说:递归函数必须有一个终止递归的条件。当每次这个函数被执行时,我们判断一个条件决定是否继续递归,这个条件最终必须能够被满足。如果没有递归终止条件或者这个条件永远不能被满足,则这个递归没有收敛性,这个递归最终要失败。
- 因为递归是占用栈内存的,每次递归调用都会消耗一些栈内存。因此必须在栈内存耗尽之前递归收敛(终止),否则就会栈溢出。
- 递归函数的使用是有一定风险的,必须把握好。
函数库
什么是函数库?
- 函数库就是一些事先写好的函数的集合,给别人复用。
- 函数是模块化的,因此可以被复用。我们写好了一个函数,可以被反复使用。也可以A写好了一个函数然后共享出来,当B有相同的需求时就不需自己写直接用A写好的这个函数即可。
函数库的由来
- 最开始是没有函数库,每个人写程序都要从零开始自己写。时间长了慢慢的早期的程序员就积累下来了一些有用的函数。
- 早期的程序员经常参加行业聚会,在聚会上大家互相交换各自的函数库。
- 后来程序员中的一些大神就提出把大家各自的函数库收拢在一起,然后经过校准和整理,最后形成了一份标准化的函数库,就是现在的标准的函数库,譬如说glibc。
函数库的提供形式:动态链接库与静态链接库
- 早期的函数共享都是以源代码的形式进行的。这种方式共享是最彻底的(后来这种源码共享的方向就形成了我们现在的开源社区)。但是这种方式有它的缺点,缺点就是无法以商业化形式来发布函数库。
- 商业公司需要将自己的有用的函数库共享给被人(当然是付费的),但是又不能给客户源代码。这时候的解决方案就是以库(主要有2种:静态库和动态库)的形式来提供。
- 比较早出现的是静态链接库。静态库其实就是商业公司将自己的函数库源代码经过只编译不连接形成.o的目标文件,然后用ar工具将.o文件归档成.a的归档文件(.a的归档文件又叫静态链接库文件)。商业公司通过发布.a库文件和.h头文件来提供静态库给客户使用;客户拿到.a和.h文件后,通过.h头文件得知库中的库函数的原型,然后在自己的.c文件中直接调用这些库文件,在连接的时候链接器会去.a文件中拿出被调用的那个函数的编译后的.o二进制代码段链接进去形成最终的可执行程序。
- 动态链接库比静态链接库出现的晚一些,效率更高一些,是改进型的。现在我们一般都是使用动态库(GCC默认使用的是动态库)。静态库在用户链接自己的可执行程序时就已经把调用的库中的函数的代码段链接进最终可执行程序中了,这样好处是可以执行,坏处是太占地方了。尤其是有多个应用程序都使用了这个库函数时,实际上在多个应用程序最后生成的可执行程序中都各自有一份这个库函数的代码段。当这些应用程序同时在内存中运行时,实际上在内存中有多个这个库函数的代码段,这完全重复了。而动态链接库本身不将库函数的代码段链接入可执行程序,只是做个标记。然后当应用程序在内存中执行时,运行时环境发现它调用了一个动态库中的库函数时,会去加载这个动态库到内存中,然后以后不管有多少个应用程序去调用这个库中的函数都会跳转到第一次加载的地方去执行(不会重复加载)。
函数库中库函数的使用
- gcc中编译链接程序默认是使用动态库的,要想静态链接需要显式用 -static 来强制静态链接。
- 库函数的使用需要注意3点:
- 第一,包含相应的头文件;
- 第二,调用库函数时注意函数原型;
- 第三,有些库函数链接时需要额外用 -lxxx 来指定链接;
- 第四,如果是动态库,要注意 -L 指定动态库的地址。
字符串函数
什么是字符串
- 字符串就是由多个字符在内存中连续分布组成的字符结构。字符串的特点是指定了开头(字符串的指针)和结尾(结尾固定为字符\'\\0\'),而没有指定长度(长度由开头地址和结尾地址相减得到)
为什么要讲字符串处理函数
- 函数库为什么要包含字符串处理函数?因为字符串处理的需求是客观的,所以从很早开始人们就在写很多关于字符串处理的函数,然后逐渐形成了现在的字符串处理函数库。
- 面试笔试时,常用字符串处理函数也是经常考到的点。
常用字符串处理函数
- C库中字符串处理函数包含在string.h中,这个文件在ubuntu系统中在/usr/include中
- 常见字符串处理函数及作用:
memcpy
- 原型:void *memcpy(void *dest, const void *src, size_t n);
- 功能:由src指向地址为起始地址的连续n个字节的数据复制到以destin指向地址为起始地址的空间内。
- 说明:http://blog.csdn.net/goodwillyang/article/details/45559925
- 例子:char a[100], b[50]; memcpy(b, a,sizeof(b));
memmove
- 原型:void *memmove(void *dest, const void *src, size_t n);
- 功能:由src指向地址为起始地址的连续n个字节的数据复制到以destin指向地址为起始地址的空间内。memcpy在内存没有重复的情况下能够正确复制,若有重叠情况则复制结果错误,但是它的效率比memmove高。所以,在确定没有重复的情况下用memcpy,在不确定是否有内存重复的情况用memmove。
- 说明:memcpy和memmove的区别:http://blog.csdn.net/z702143700/article/details/47107701
- http://blog.chinaunix.net/uid-26495963-id-3080058.html
- 例子:char* p1 = s; char* p2 = s+2; memcpy(p2, p1, 5)
memset
- 原型:void *memset(void *s, int c, size_t n);
- 功能:将一段内存空间全部初始化为某个字符,一般用在对定义的字符串进行初始化为‘ ’或‘/0’
- 说明:http://blog.sina.com.cn/s/blog_715d0ae30100yj2d.html
- 例子:char a[100]; memset(a, \'/0\', sizeof(a));
- struct sample_strcut stTest; memset(&stTest,0,sizeof(struct sample_struct));
memcmp
- 原型:int memcmp(const void *s1, const void *s2, size_t n);
- 功能:比较buf1和buf2的前n个字节;s1 > s2 返回 >0 的值; s1 = s2 返回 =0 的值; s1 < s2 返回 <0 的值
- 说明:http://blog.csdn.net/riyadh_linux/article/details/50211403
- 例子:char a[] = "nihao jingliming"; char b[] = "nihao xiaoming";
- int r=memcmp(a,b,strlen(a)); if(r>0){}
memchr
- 原型:void *memchr(const void *s, int c, size_t n);
- 功能:从s所指内存区的前n个字节查找字符c,当第一次遇到字符c时停止查找。如果成功,返回指向字符c的指针;否则返回null
- 说明:http://www.cnblogs.com/jingliming/p/4737409.html
- 例子:char a[] = "nihao jingliming"; void *p;
- p = memchr(a,\'j\',sizeof(a));if (p){}
strcpy
- 原型:char *strcpy(char *dest, const char *src);
- 功能:strcpy把从src地址开始且含有\'\\0\'结束符的字符串复制到以dest开始的地址空间,返回值的类型为char*。
- 说明:http://blog.csdn.net/callinglove/article/details/8597189
- 例子:chara[20],*p1="linux";my_strcpy(a,p1);puts(a);
- 实现:
strncpy
- 原型:char *strncpy(char *dest, const char *src, size_t n);
- 功能:把src所指向的字符串中以src地址开始的前n个字节复制到dest所指的数组中,并返回dest。
- 说明:http://blog.csdn.net/lanzhihui_10086/article/details/39827729
- http://blog.csdn.net/goodwillyang/article/details/45559925
- 例子:char name[]={"Chinanet"}; dest[20]={}; strncpy(dest,name,3);
- 实现:
strcat
- 原型:char *strcat(char *dest, const char *src);
- 功能:把src所指由NULL结束的字符串复制到dest所指的数组中。
- 说明:http://blog.csdn.net/lonfee88/article/details/6402274
- 例子:chara[20]="mark";charb[]="yyyyy";char*cat=my_strcat(a,b); printf("%s%d\\n",cat,strlen(cat));
- 实现:
strncat
- 原型:char *strncat(char *dest, const char *src, size_t n);
- 功能:把src所指字符串的前n个字符添加到dest结尾处,覆盖dest结尾处的\'/0\',实现字符串连接。
- 说明:http://blog.csdn.net/sky2098/article/details/1530662
- 例子:int n=15; char *strtemp;
- strtemp=strncat(str1,str2,n); //将字符串str2中的前n个字符连接到str1的后面
strcmp
- 原型:int strcmp(const char *s1, const char *s2);
- 功能:strcmp函数实际上是对字符的ASCII码进行比较,实现原理如下:首先比较两个串的第一个字符,若不相等,则停止比较并得出两个ASCII码大小比较的结果;逐字符比较字符串s1(source)和字符串s2(dest);s1 > s2 返回 >0 的值; s1 = s2 返回 =0 的值; s1 < s2 返回 <0 的值
- 说明:http://www.cnblogs.com/happyhorseji/p/4244068.html
- 例子:char a = "linux"; char b = "Nlinux"; int r; r = srtcmp(a, b); if(r >0){}
strncmp
- 原型:int strncmp(const char *s1, const char *s2, size_t n);
- 功能:字符串比较函数,逐字符比较字符串s1(source)和字符串s2(dest)的前n个字符,n为0时,返回0;
- 说明:http://blog.csdn.net/riyadh_linux/article/details/50021381
- 例子:char *a = "linux"; char *b = "Nlinux"; int r;
- r = srtcmp(a, b, 3); if(r == 0){}
strdup
- 原型:char *strdup(const char *s);
- 功能:strdup()函数计算出字符串的长度,然后调用malloc()函数在堆上分配相应的空间,然后strdup()函数把所有字符复制到堆上的新空间(使用之后需要使用free释放内存,避免内存泄漏)。stdrup可以直接把要复制的内容复制给没有初始化的指针,因为它会自动分配空间给目的指针。
- 说明:http://blog.csdn.net/leichelle/article/details/7465769
- 例子:char *dup_str, *string = "abcde"; dup_str =strdup(string);
strndup
- 原型:char *strndup(const char *s, size_t n);
- 功能:计算字符串S的长度,如果S大于n,则只复制前n个字符;原理同strdup相同;
- 说明:http://blog.csdn.net/yaoliang11/article/details/4163982
- 例子:char *dup_str, *string = "abcde"; dup_str =strndup(string,3);
strchr
- 原型:char *strchr(const char *s, int c);
- 功能:查找字符串s中首次出现字符c的位置,成功则返回要查找字符第一次出现的位置,失败返回NULL。
- 说明:http://blog.csdn.net/lanzhihui_10086/article/details/39831935
- 例子:char string[] = "This is a string"; char *ptr; char c=\'h\'; ptr=strchr(string,c); puts(ptr);
strstr
- 原型:char *strstr(const char *haystack, const char *needle);
- 功能:搜索一个字符串 *needle 在 *haystack 字符串中的第一次出现。找到所搜索的字符串,则该函数返回第一次匹配的字符串的地址;如果未找到所搜索的字符串,则返回NULL。
- 说明:http://www.cnblogs.com/balingybj/p/4783684.html
- 例子:char *str1 = "Borland International", *str2 = "a", *ptr; ptr = strstr(str1, str2); puts(ptr);
strtok
- 原型:char *strtok(char *str, const char *delim);
- 功能:该函数用来将字符串分割成一个个片段。
- 说明:http://blog.csdn.net/mormont/article/details/53677363
- 例子:char str[]="ab,cd,ef"; char *ptr2; ptr2 = strtok(str, ","); while(ptr2 != NULL)
- {printf("str=%s\\n",str); printf("ptr=%s\\n",ptr2); ptr2 = strtok(NULL, ",");}
- 实现:
数学库函数
math.h
- 真正的数学运算的函数定义在:/usr/include/i386-linux-gnu/bits/mathcalls.h
- 使用数学库函数的时候,只需要包含math.h即可。
计算开平方
- 库函数: double sqrt(double x);
- 注意区分编译时警告/错误,和链接时的错误:
编译时警告/错误:
- math.c:9:13: warning: incompatible implicit declaration of builtin function ‘sqrt’ [enabled by default]
- double b = sqrt(a);
链接时错误:
- math.c:(.text+0x1b): undefined reference to `sqrt\'
- collect2: error: ld returned 1 exit status
分析;
- 这个链接错误的意思是:sqrt函数有声明(声明就在math.h中)有引用(在math.c)但是没有定义,链接器找不到函数体。sqrt本来是库函数,在编译器库中是有.a和.so链接库的(函数体在链接库中的)。
- C链接器的工作特点:因为库函数有很多,链接器去库函数目录搜索的时间比较久。为了提升速度想了一个折中的方案:链接器只是默认的寻找几个最常用的库,如果是一些不常用的库中的函数被调用,需要程序员在链接时明确给出要扩展查找的库的名字。链接时可以用 -lxxx 来指示链接器去到 libxxx.so 中去查找这个函数。
链接时加-lm
- -lm就是告诉链接器到libm中去查找用到的函数。
- 实战中发现在高版本的gcc中,经常会出现没加-lm也可以编译链接的。
- 使用ldd命令可以知道该程序链接了哪些库:
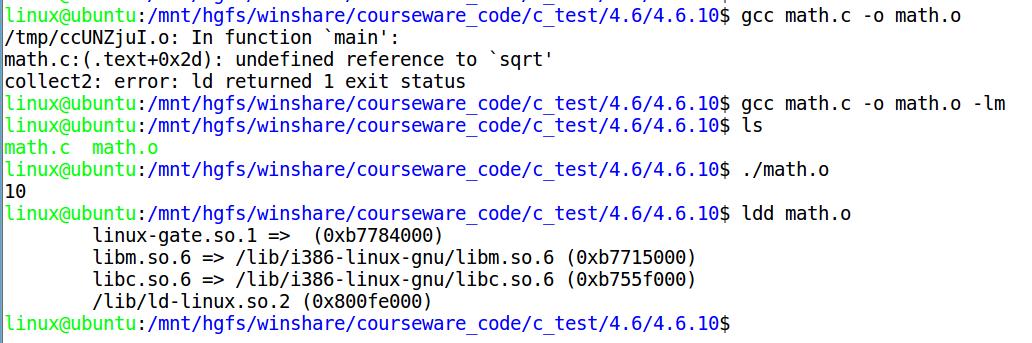
自己制作静态链接库并使用
第一步:自己制作静态链接库
- 首先使用gcc -c只编译不连接,生成.o文件;然后使用ar工具进行打包成.a归档文件
- 库名不能随便乱起,一般是lib+库名称,后缀名是.a表示是一个归档文件
- 注意:制作出来了静态库之后,发布时需要发布.a文件和.h文件。

第二步:使用静态链接库
- 把.a和.h都放在引用的文件夹下,然后在.c文件中包含库的.h,然后直接使用库函数。
- 第一次,编译方法:gcc test.c -o test
- 报错信息:test.c:(.text+0xa): undefined reference to `func1\'
- test.c:(.text+0x1e): undefined reference to `func2\'
- 第二次,编译方法:gcc test.c -o test -laston
- 报错信息:/usr/bin/ld: cannot find -laston
- collect2: error: ld returned 1 exit status
- 第三次,编译方法:gcc test.c -o test -laston -L.(L表示路径,. 表示当前路径)
- 无报错,生成test,执行正确。
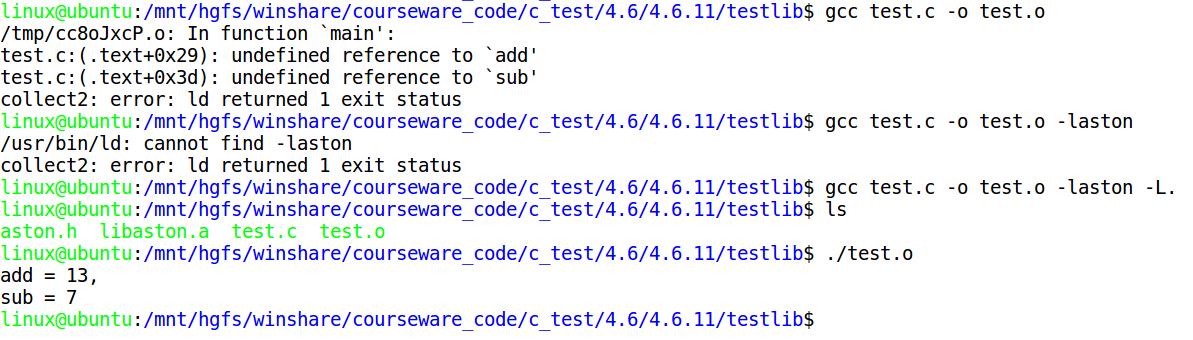
- 除了ar名另外,还有个 nm 命令也很有用,nm 可以用来查看一个.a文件中都有哪些符号(函数符号)

自己制作动态链接库并使用
- 动态链接库的后缀名是.so(对应windows系统中的dll),静态库的扩展名是.a
创建一个动态链接库。
- gcc aston.c -o aston.o -c -fPIC
- gcc -o libaston.so aston.o -shared
- -fPIC是位置无关码,-shared是按照共享库的方式来链接。
- 注意:做库的人给用库的人发布库时,发布libxxx.so和xxx.h即可。

使用自己创建的共享库。
- 第一步,编译方法:gcc test.c -o test
- 报错信息:test.c:(.text+0xa): undefined reference to `func1\'
- test.c:(.text+0x1e): undefined reference to `func2\'
- collect2: error: ld returned 1 exit status
- 第二步,编译方法:gcc test.c -o test -laston
- 报错信息:/usr/bin/ld: cannot find -laston
- collect2: error: ld returned 1 exit status
- 第三步,编译方法:gcc test.c -o test -laston -L.
- 编译成功
- 但是运行出错,报错信息:
- error while loading shared libraries: libaston.so: cannot open shared object file: No such file or directory
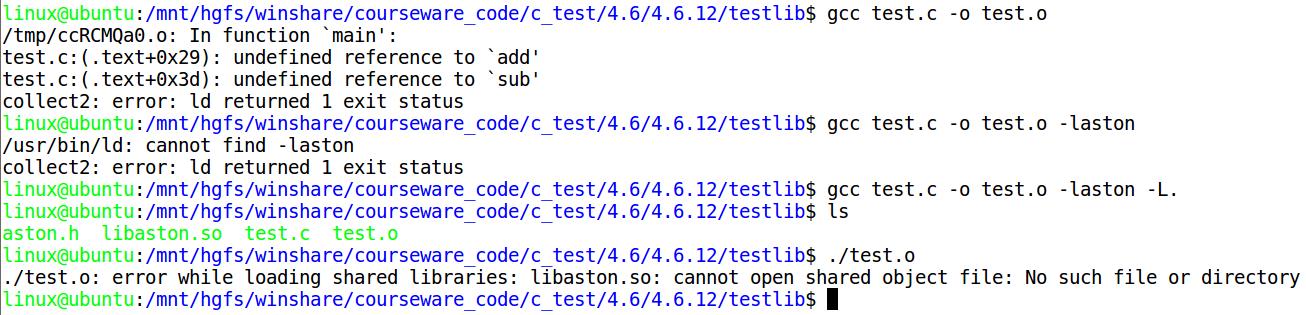
- 错误原因:动态链接库运行时需要被加载(运行时环境在执行test程序的时候发现他动态链接了libaston.so,于是乎会去固定目录尝试加载libaston.so,如果加载失败则会打印以上错误信息。)
解决方法一:
- 将libaston.so放到固定目录下就可以了,这个固定目录一般是/usr/lib目录。
- cp libaston.so /usr/lib即可
解决方法二:
- 使用环境变量LD_LIBRARY_PATH。操作系统在加载固定目录/usr/lib之前,会先去LD_LIBRARY_PATH这个
以上是关于6C_宏定义与预处理函数与函数库的主要内容,如果未能解决你的问题,请参考以下文章