Spark篇---Spark中Shuffle文件的寻址
Posted L先生AI课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark篇---Spark中Shuffle文件的寻址相关的知识,希望对你有一定的参考价值。
一、前述
Spark中Shuffle文件的寻址是一个文件底层的管理机制,所以还是有必要了解一下的。
二、架构图
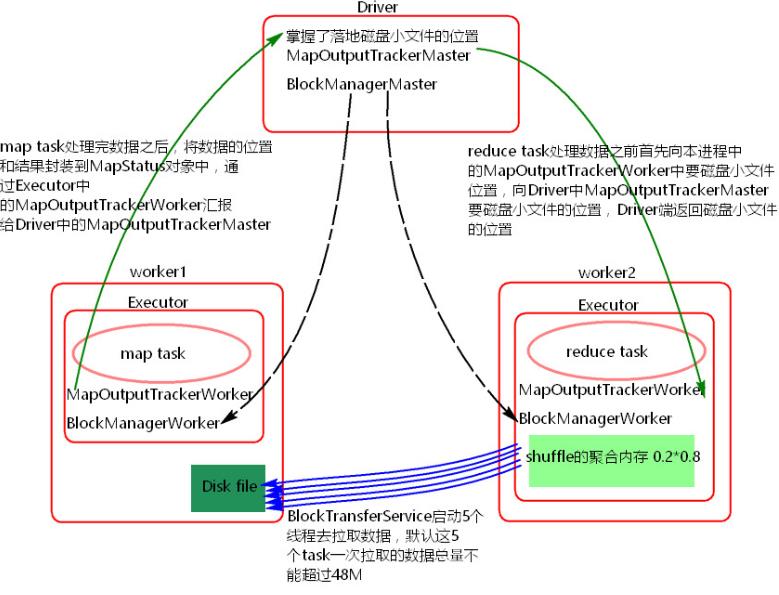
三、基本概念:
1) MapOutputTracker
MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。
- MapOutputTrackerMaster是主对象,存在于Driver中。
- MapOutputTrackerWorker是从对象,存在于Excutor中。
2) BlockManager
BlockManager块管理者,是Spark架构中的一个模块,也是一个主从架构。
- BlockManagerMaster,主对象,存在于Driver中。
BlockManagerMaster会在集群中有用到广播变量和缓存数据或者删除缓存数据的时候,通知BlockManagerSlave传输或者删除数据。
- BlockManagerWorker,从对象,存在于Excutor中。
BlockManagerWorker会与BlockManagerWorker之间通信。
无论在Driver端的BlockManager还是在Excutor端的BlockManager都含有四个对象:
① DiskStore:负责磁盘的管理。
② MemoryStore:负责内存的管理。
③ ConnectionManager:负责连接其他的 BlockManagerWorker。
④ BlockTransferService:负责数据的传输。
四、Shuffle文件寻址流程
a) 当map task执行完成后,会将task的执行情况和磁盘小文件的地址封装到MpStatus对象中,通过MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报。
b) 在所有的map task执行完毕后,Driver中就掌握了所有的磁盘小文件的地址。
c) 在reduce task执行之前,会通过Excutor中MapOutPutTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
d) 获取到磁盘小文件的地址后,会通过BlockManager中的ConnectionManager连接数据所在节点上的ConnectionManager,然后通过BlockTransferService进行数据的传输。
e) BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M。拉取过来的数据放在Executor端的shuffle聚合内存中(spark.shuffle.memeoryFraction 0.2), 如果5个task一次拉取的数据放不到shuffle内存中会有OOM,如果放下一次,不会有OOM,以后放不下的会放磁盘。
五、扩展补充如何避免OOM
1、拉去数据 少一些。
2、提高ExecutorShuffle聚合内存。
3、提高executor内存。
以上是关于Spark篇---Spark中Shuffle文件的寻址的主要内容,如果未能解决你的问题,请参考以下文章
Spark记录-Spark性能优化(开发资源数据shuffle)
Spark ShuffleExecutor是如何fetch shuffle的数据文件