ArrayListVectorHashMapHashTableHashSet的默认初始容量加载因子扩容增量具体区别
Posted 有梦想的咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArrayListVectorHashMapHashTableHashSet的默认初始容量加载因子扩容增量具体区别相关的知识,希望对你有一定的参考价值。
要讨论这些常用的默认初始容量和扩容的原因是:
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上,这无疑使效率大大降低。
加载因子的系数小于等于1,意指 即当 元素个数 超过 容量长度*加载因子的系数 时,进行扩容。
另外,扩容也是有默认的倍数的,不同的容器扩容情况不同。
List 元素是有序的、可重复的:
ArrayList、Vector默认初始容量为10
Vector:线程安全,但速度慢
底层数据结构是数组结构
加载因子为1:即当 元素个数 超过 容量长度 时,进行扩容
扩容增量:原容量的 1倍
如 Vector的容量为10,一次扩容后是容量为20
ArrayList:线程不安全,查询速度快
底层数据结构是数组结构
扩容增量:原容量的 0.5倍+1
如 ArrayList的容量为10,一次扩容后是容量为16
Set(集) 元素无序的、不可重复。
HashSet:线程不安全,存取速度快
底层实现是一个HashMap(保存数据),实现Set接口
默认初始容量为16(为何是16,见下方对HashMap的描述)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
Map是一个双列集合
HashMap:默认初始容量为16,长度始终保持2的n次方
(为何是16:16是2^4,可以提高查询效率,另外,32=16<<1 -->至于详细的原因可另行分析,或分析源代码)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashMap的容量为16,一次扩容后是容量为32
HashTable:默认初始容量为11
线程安全,但是速度慢,不允许key/value为null
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:2*原数组长度+1
如 HashTable的容量为11,一次扩容后是容量为23
HashTable和HashMap的具体区别:
Hashtable 和 HashMap 做为 Map 的基本特性
两者都实现了Map接口,基本特性相同
- 对同一个Key,只会有一个对应的value值存在
- 如何算是同一个Key? 首先,两个key对象的hash值相同,其次,key对象的equals方法返回真
内部数据结构
Hashtable和HashMap的内部数据结构相似
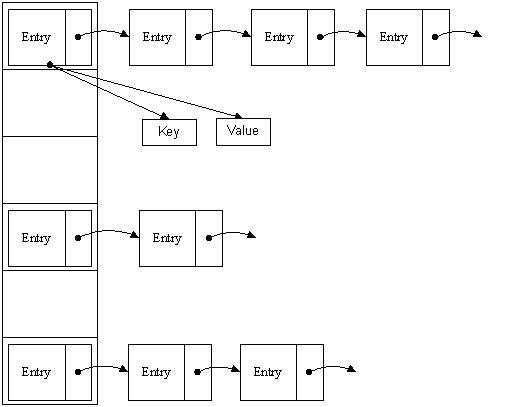
其基本内部数据结构是一个Entry数组 (transient Entry[] table)
- 数组元素为实现Map.Entry<K,V>接口的类,Hashtable和HashMap各自实现了自己的Entry类。
- Entry包含一个Key-value对,以及一个next指针指向另一个Entry。多个Entry可以组成一个单向链表。
常用操作
数据插入操作: put(key,value)
- 根据Key的hash值计算出该Entry所应存放的位置(数组下标)
- 若该数组元素为空,直接放置Entry到此处
- 若多个不同的Key所计算得到的数组下标相同,新加入的Key-value对(Entry)会被加入到Entry单向链表中。Hashtable和HashMap都是将其插入链表首部.
- 若已经有相同的Key存在于这个链表中,则,新的value值会取代老的value
- 当Map中存放的Entry数量超过其限制( 数组长度 * 负荷因子)时,Map将自动重新调整数组大小并重新对Entry进行散列
数据查找:get(key)
- 根据Key的hash值计算出该Entry对所应存放的位置(数组下标)
- 得到该位置的第一个Entry对象,比较key和Entry.key,若hash值相同,并且equals为真,则该Entry是我们要找的Key-value对,否则继续沿next指针构成的单向链表查找
数据移除:remove(key)
- 按照上述数据查找的方式找到key所在的Entry对象,将其移除,并保持Entry单向链表的连通性
Hashtable 和 HashMap 的比较
一般情况下,HashMap能够比Hashtable工作的更好、更快,主要得益于它的散列算法,以及没有同步。应用程序一般在更高的层面上实 现了保护机制,而不是依赖于这些底层数据结构的同步,因此,HashMap能够在大多应用中满足需要。推荐使用HashMap,如果需要同步,可以使用同 步工具类将其转换成支持同步的HashMap。
Map的效率
Map的效率与Entry数组大小及负荷因子的选取有密切关系。选取适当的数组大小有利于Key-value对的散列分布,并且,如果数组足够 大,将有效的减少重新调整数组的次数,提高效率。较小的负荷因子将占用更多的空间,但降低冲突的可能性,从而将加快访问和更新的速度。
另外,Key的hash值本身如果能保证较好的散列性,也有益于提高Map的读写效率。在effective java中,对hash()的重载有好的建议。
辨析
“Hashtable和HashMap的区别主要是前者是同步的,后者是快速失败机制保证不会出现多线程并发错误(Fast-Fail)。”,这是一个被很多文章转载过的概念,但其描述并不准确,容易引起误会。
实质上,Fast-fail与同步保护的是两种不同情况下的并发,两者不能拿来做比较。
Hashtable是同步的,在执行get,put,remove,size,clear等一次性读写操作时,使用了同步机制,避免了多个线程 同时读写Hashtable。但同步机制并不能避免在iterator或Enumeration遍历过程中其他线程对Hashtable的put、 remove、clear操作,这些写操作都会被毫无阻拦得成功执行。
快速失败机制主要目的在于使iterator遍历数组的线程能及时发现其他线程对Map的修改(如put、remove、clear等),因 此,fast-fail并不能保证所有情况下的多线程并发错误,只能保护iterator遍历过程中的iterator.next()与写并发.
其次,Hashtable的iterator遍历方式也是支持fast-fail的,不能说它没有快速失败机制。写一个简单的例程就可以证明这 一点,一个线程做iterator遍历,另一个线程向hashtable中put新的key和value,很容易就会观察到fast-fail 机制报告ConcurrentModificationException
以上是关于ArrayListVectorHashMapHashTableHashSet的默认初始容量加载因子扩容增量具体区别的主要内容,如果未能解决你的问题,请参考以下文章