R实战 第三篇:数据处理(基础)
Posted 悦光阴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R实战 第三篇:数据处理(基础)相关的知识,希望对你有一定的参考价值。
数据结构用于存储数据,不同的数据结构对应不同的操作方法,对应不同的分析目的,应选择合适的数据结构。在处理数据时,为了便于检查数据对象,可以通过函数attributes(x)来查看数据对象的属性,str(x)函数用于查看R对象的内部结构,通过print(x)函数,显示数据对象存储的内容,该函数把数据打印到控制台上,另外,RStudio提供了一个可视化查看数据的函数View(x)。
一,处理标量数据
标量通常是常量,每一个标量都有特定的数据类型,常用的数据类型是数值类型,字符类型,逻辑类型和日期类型。
对于逻辑类型,可能的值是TRUE和FALSE,用于逻辑操作的运算符:与(&)、或(|)、非(!)
R语言中经常会遇到一些特殊值:
- 缺失值 NA(Not Avaiable),是不可用的缩写,通过函数is.na(x)来测试变量的值是否为NA;
- NaN为“不是一个数”,意味着计算没有数学意义;
- NULL值,空值,表示一个空的变量,不会占用任何空间,通过函数is.null(x)来测试变量的值是否为NULL;
- 特殊的数字:Inf、-Inf 表示正无穷,负无穷;
1,日期类型
日期类型比较特殊,日期值通常以字符串的形式输入到R中,然后使用as.Date()函数转换为以数值形式存储的日期变量,as.Date()函数的语法是:
as.Date(x, input_format)
参数input_format是日期值的输入格式,默认的输入格式是"yyyy-mm-dd":
mydate <- as.Date("2017-01-13")
输入参数可以自定义日期的输入格式:
- %d:数字表示的天(0-31)
- %a:缩写的星期名(Mon、Tue、Wed、Thur、Fri、Sat、Sun)
- %m:月份(00、01、02等)
- %b:缩写的月份(Jan、Feb、Mar等)
- %B:英语月份(January、February 、March等)
- %y:两位数的年份
- %Y:四位数的年份
举个例子,把默认的日期格式转换为特定类型的日期格式:
as.Date("2018-03-05","%Y-%m-%d")
把日期类型转换为字符串类型,可以使用format()函数,指定日期的输出格式:
format(mydate,format="output_format")
例如,把当前日期按照特定的格式输出:
today<-Sys.Date()
format(today,format("%B %d %Y"))
也可以直接把日期类型转换为字符串类型:
strdate <- as.character(mydate)
2,字符类型
常用的字符类型的操作:
- 查看字符数量: nchar(x)
- 提取或替换字符的子串: substr(x, start,stop)
- 匹配模式,返回下标:grep(pattern, x, ignore.case=FALSE, fixed=FALSE),从x中搜索匹配模式的字符的下标
- 匹配模式,并替换:sub(pattern, replacement, x, ignore.case=FALSE, fixed=FALSE),从x中搜索匹配模式的字符,并以文本replacement替换
- 分割字符: strsplit(x,split,fixed=FALSE)
- 连接字符: paste(...,sep=" "),把多个字符连接成一个长的字符串,分隔符由参数sep指定
- 字符的大小写转换: toupper(x),tolower(x)
3,数值类型
对于数值类型,算术运算符是:
- 加(+),减(-),乘(*),除(/)
- 幂运算:^ 或 **
- 模运算:%%
- 整除:%/%
处理数值类型常用的数学函数是:
- 不小于x的最小整数:ceiling(x)
- 不大于x的最大整数:floor(x)
- 四舍五入,函数原型是round(x,digits=n),digits设定小数点位置,默认为0,即小数点后零位(取整)
- 保留小数的有效位数:signif(x,digits=n)
- 截取整数部分,舍弃小数部分:trunc(x)
常用的统计函数:
- 平均值:mean(x)
- 中位数:median(x)
- 绝对中位数:mad(x)
- 分位数:quantile(x,probs)
- 标准差:sd(x)
- 方差:var(x)
- 值域:range(x)
- 求和:sum(x)
- 最值:min(x),max(x)
- 标准化:scale(x, center=TRUE, scale=TRUE)
- 计数:count(df, vars)和length(x),计数的使用方法比较特殊,请阅读《R实战 第六篇:数据变换(aggregate+dplyr包)》
分割区间的函数:
- 把连续型变量分割位有着n个水平的因子:cut(x, n, ordered_result)
- 创建美观的分割点,通过选取n+1个等间距的取整值,把一个连续型变量分割位n个区间:pretty(x, n)
数学函数:
- abs(x):绝对值
- sqrt(x):平方根
- exp(x):以e为底,x为指数的指数函数
- 对数函数:log(x,base=n)对x取以n为底的对数,log(x) 自然对数以e为底,log10(x)以10为底;
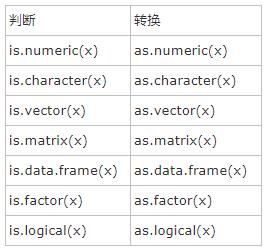
二,类型判断和转换
三,随机抽样
从海量的数据抽取一定数量的样本数据,以创建分析模型,抽样的函数是:
sample(x, size, replace = FALSE, prob = NULL)
参数注释:
- x:样本空间
- size:抽取的样本数量
- replace:如果为TRUE,表示放回抽样;如果为FALSE,表示无放回抽样;
举个例子,采用放回抽样,把样本重复12次,得到一个矩阵,并转换为数据框类型:
> d <-data.frame(matrix(sample(c(NA, 1:4), 12, replace = TRUE), 4)) > d X1 X2 X3 NA 4 1 1 2 NA 1 4 2 NA NA 4
四,伪随机数
函数runif()用于生成服从正态分布的伪随机数,n是生成随机数的个数,min和max是随机数的最值。
runif(n, min = 0, max = 1)
在每次生成随机数时,函数都会使用一个不同的种子,因此会产生不同的结果,通过函数set.seed(n)显式指定种子,让结果可以重现。
举个例子,设置随机数种子,使用runif()函数生成0-1区间上服从均匀分布的伪随机数:
set.seed(n) runif(5)
设置R会话的小数点数量,生成整数伪随机数:
> options(digits=0) > set.seed(1) > runif(10,min=1,max=100) [1] 27 38 58 91 21 90 95 66 63 7
以上是关于R实战 第三篇:数据处理(基础)的主要内容,如果未能解决你的问题,请参考以下文章