RabbitMQ
什么叫消息队列
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
为何用消息队列
从上面的描述中可以看出消息队列是一种应用间的异步协作机制,那什么时候需要使用 MQ 呢?
以常见的订单系统为例,用户点击【下单】按钮之后的业务逻辑可能包括:扣减库存、生成相应单据、发红包、发短信通知。在业务发展初期这些逻辑可能放在一起同步执行,随着业务的发展订单量增长,需要提升系统服务的性能,这时可以将一些不需要立即生效的操作拆分出来异步执行,比如发放红包、发短信通知等。这种场景下就可以用 MQ ,在下单的主流程(比如扣减库存、生成相应单据)完成之后发送一条消息到 MQ 让主流程快速完结,而由另外的单独线程拉取MQ的消息(或者由 MQ 推送消息),当发现 MQ 中有发红包或发短信之类的消息时,执行相应的业务逻辑。
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。

rabbitMQ安装

for Linux: 安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server 注意:service rabbitmq-server start/stop
for Mac: bogon:~ yuan$ brew install rabbitmq bogon:~ yuan$ export PATH=$PATH:/usr/local/sbin bogon:~ yuan$ rabbitmq-server
debian安装
echo \'deb http://www.rabbitmq.com/debian/ testing main\' | sudo tee /etc/apt/sources.list.d/rabbitmq.list 1)wget -O - "https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc" | sudo apt-key add - 2)sudo apt-get update 3)sudo apt-get install rabbitmq-server sudo apt-get install erlang 4)启动/结束rabbitmq: /etc/init.d/rabbitmq-server start/stop 5)如果要使用pika,那么pip install pika
linux查看rabbitmq中间存的数据
sudo rabbitmqctl list_queues
远程访问rabbitmq:自己增加一个用户,步骤如下: l1. 创建一个admin用户:sudo rabbitmqctl add_user admin 123123 l2. 设置该用户为administrator角色:sudo rabbitmqctl set_user_tags admin administrator l3. 设置权限:sudo rabbitmqctl set_permissions -p \'/\' admin \'.\' \'.\' \'.\' l4. 重启rabbitmq服务:sudo service rabbitmq-server restart 之后就能用admin用户远程连接rabbitmq server了。
rabbitMQ工作模型
简单模式
示例
# ######################### 生产者 ######################### #!/usr/bin/env python import pika
credentials = pika.PlainCredentials(\'admin\',\'123456\')
connection = pika.BlockingConnection(pika.ConnectionParameters(
\'192.168.56.19\',5672,\'/\',credentials
)) channel = connection.channel() channel.queue_declare(queue=\'hello\') channel.basic_publish(exchange=\'\', routing_key=\'hello\', body=\'Hello World!\') print(" [x] Sent \'Hello World!\'") connection.close()
# ########################## 消费者 ########################## connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\')) channel = connection.channel() channel.queue_declare(queue=\'hello\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) channel.basic_consume( callback, queue=\'hello\', no_ack=True) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
相关参数
(1)no-ack = False,如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
- 回调函数中的
ch.basic_ack(delivery_tag=method.delivery_tag) - basic_comsume中的
no_ack=False
消息接收端应该这么写:
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'10.211.55.4\')) channel = connection.channel() channel.queue_declare(queue=\'hello\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print \'ok\' ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=\'hello\', no_ack=False) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
(2) durable :消息不丢失
# 生产者 #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'10.211.55.4\')) channel = connection.channel() # make message persistent channel.queue_declare(queue=\'hello\', durable=True) channel.basic_publish(exchange=\'\', routing_key=\'hello\', body=\'Hello World!\', properties=pika.BasicProperties( delivery_mode=2, # make message persistent )) print(" [x] Sent \'Hello World!\'") connection.close() # 消费者 #!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'10.211.55.4\')) channel = connection.channel() # make message persistent channel.queue_declare(queue=\'hello\', durable=True) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print \'ok\' ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=\'hello\', no_ack=False) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
(3) 消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
#!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'10.211.55.4\')) channel = connection.channel() # make message persistent channel.queue_declare(queue=\'hello\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print \'ok\' ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue=\'hello\', no_ack=False) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
exchange模型
3.1 发布订阅
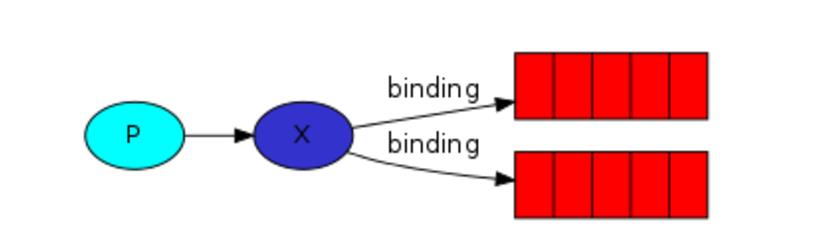
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout


# 生产者 #!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'logs\', type=\'fanout\') message = \' \'.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange=\'logs\', routing_key=\'\', body=message) print(" [x] Sent %r" % message) connection.close() # 消费者 #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'logs\', type=\'fanout\') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange=\'logs\', queue=queue_name) print(\' [*] Waiting for logs. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
3.2 关键字发送
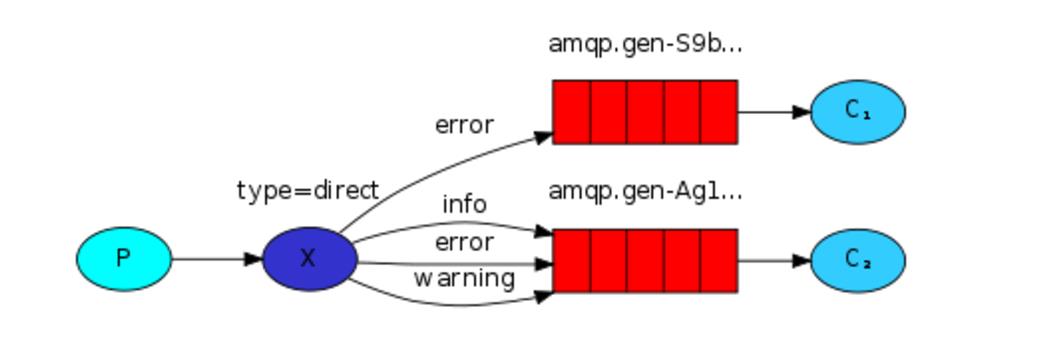
exchange type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'direct_logs\', type=\'direct\') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\\n" % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange=\'direct_logs\', queue=queue_name, routing_key=severity) print(\' [*] Waiting for logs. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
3.3 模糊匹配
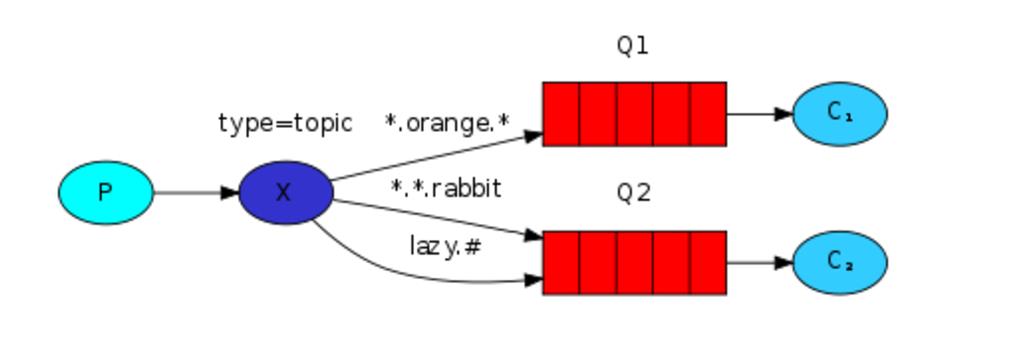
exchange type = topic
发送者路由值 队列中 old.boy.python old.* -- 不匹配 old.boy.python old.# -- 匹配
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
示例:
#!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'topic_logs\', type=\'topic\') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange=\'topic_logs\', queue=queue_name, routing_key=binding_key) print(\' [*] Waiting for logs. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
基于RabbitMQ的RPC
Callback queue 回调队列
一个客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识
一个客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
客户端发送请求:某个应用将请求信息交给客户端,然后客户端发送RPC请求,在发送RPC请求到RPC请求队列时,客户端至少发送带有reply_to以及correlation_id两个属性的信息
服务器端工作流: 等待接受客户端发来RPC请求,当请求出现的时候,服务器从RPC请求队列中取出请求,然后处理后,将响应发送到reply_to指定的回调队列中
客户端接受处理结果: 客户端等待回调队列中出现响应,当响应出现时,它会根据响应中correlation_id字段的值,将其返回给对应的应用
服务器端
#!/usr/bin/env python import pika # 建立连接,服务器地址为localhost,可指定ip地址 connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) # 建立会话 channel = connection.channel() # 声明RPC请求队列 channel.queue_declare(queue=\'rpc_queue\') # 数据处理方法 def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2) # 对RPC请求队列中的请求进行处理 def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) # 调用数据处理方法 response = fib(n) # 将处理结果(响应)发送到回调队列 ch.basic_publish(exchange=\'\', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id = \\ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag = method.delivery_tag) # 负载均衡,同一时刻发送给该服务器的请求不超过一个 channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request, queue=\'rpc_queue\') print(" [x] Awaiting RPC requests") channel.start_consuming()
客户端
#!/usr/bin/env python import pika import uuid class FibonacciRpcClient(object): def __init__(self): ”“” 客户端启动时,创建回调队列,会开启会话用于发送RPC请求以及接受响应 “”“ # 建立连接,指定服务器的ip地址 self.connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) # 建立一个会话,每个channel代表一个会话任务 self.channel = self.connection.channel() # 声明回调队列,再次声明的原因是,服务器和客户端可能先后开启,该声明是幂等的,多次声明,但只生效一次 result = self.channel.queue_declare(exclusive=True) # 将次队列指定为当前客户端的回调队列 self.callback_queue = result.method.queue # 客户端订阅回调队列,当回调队列中有响应时,调用`on_response`方法对响应进行处理; self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue) # 对回调队列中的响应进行处理的函数 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body # 发出RPC请求 def call(self, n): # 初始化 response self.response = None #生成correlation_id self.corr_id = str(uuid.uuid4()) # 发送RPC请求内容到RPC请求队列`rpc_queue`,同时发送的还有`reply_to`和`correlation_id` self.channel.basic_publish(exchange=\'\', routing_key=\'rpc_queue\', properties=pika.BasicProperties( reply_to = self.callback_queue, correlation_id = self.corr_id, ), body=str(n)) while self.response is None: self.connection.process_data_events() return int(self.response) # 建立客户端 fibonacci_rpc = FibonacciRpcClient() # 发送RPC请求 print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(30) print(" [.] Got %r" % response)