课堂笔记--Strom并发模型
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了课堂笔记--Strom并发模型相关的知识,希望对你有一定的参考价值。
Strom并发模型:
topology是如何运行的?(可与mapreduce对比)
第一层:cluster
第二层:supervisor(host、node、机器)
第三层:worker(进程)
第四层:executor(线程)
第五层:task(线程的一个个对象、如Spout和Blot)
//topology:N workers==每个==>1 excutor=>1 task
//此时,它和mapreduce那个是一样的
topology代码 | |
conf.setNumWorkers(2)//进程 topologyBuilder.setSpout("blue-spout",new Blue(),2)//线程 topologyBuilder.setBolt("green-spot",new Green(),2) .setNumTasks(4) .shuffleGrouping("blue-sqout")//线程、对象 topologyBuilder.serBolt("yellow-sqout",new Yellow(),6) .shuffleGrouping("green-bolt") | 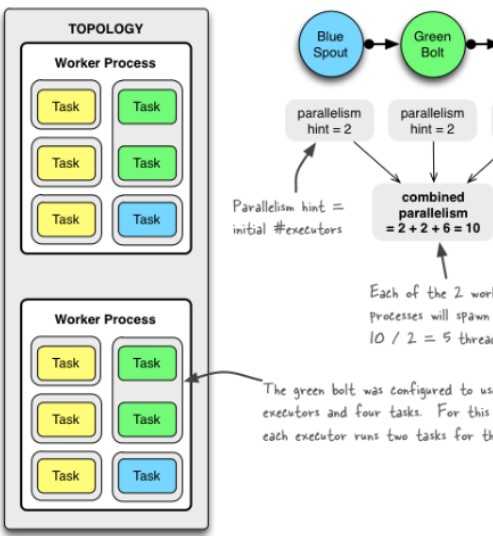 |
总结:
worker一开始设置多少个就是topology里面有多少个,executor并行度那里设置多少个就是多少个,task如果没有设置那就是一个executor对应一个task,如果有写那就是task数就是task设定的数除以executor数来决定。
【注】hadoop的mapreduce并发模型,一个job有很多很多的Tasks,然后有1000个map,有100个reduce,一个集群呢有很多个节点,比如说有500个节点,那这个时候呢,就是我的每个节点上起一些map task,起一些reduce task,这个时候呢我的1000个map发到每个机器上去运行,每个maptask呢是一个进程,每个reduce task呢也是一个进程,hadoop它的并发模型很简单,就两级,它有很多机器,每个机器上面都有很多的task进程,task进程里面呢运行的就是我们mapreduce的函数
以上是关于课堂笔记--Strom并发模型的主要内容,如果未能解决你的问题,请参考以下文章