转载自:http://www.cnblogs.com/malecrab/p/5300503.html
==================
1. Unicode与ISO 10646
全世界很多个国家都在为自己的文字编码,并且互不想通,不同的语言字符编码值相同却代表不同的符号(例如:韩文编码EUC-KR中“한국어”的编码值正好是汉字编码GBK中的“茄惫绢”)。因此,同一份文档,拷贝至不同语言的机器,就可能成了乱码,于是人们就想:我们能不能定义一个超大的字符集,它可以容纳全世界所有的文字字符,再对它们统一进行编码,让每一个字符都对应一个不同的编码值,从而就不会再有乱码了。
如果说“各个国家都在为自己文字独立编码”是百家争鸣,那么“建立世界统一的字符编码”则是一统江湖,谁都想来做这个武林盟主。早前就有两个机构试图来做这个事:
(1) 国际标准化组织(ISO),他们于1984年创建ISO/IEC JTC1/SC2/WG2工作组,试图制定一份“通用字符集”(Universal Character Set,简称UCS),并最终制定了ISO 10646标准。
(2) 统一码联盟,他们由Xerox、Apple等软件制造商于1988年组成,并且开发了Unicode标准(The Unicode Standard,这个前缀Uni很牛逼哦---Unique, Universal, and Uniform)。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。不过由于Unicode这一名字比较好记,因而它使用更为广泛。
Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point)。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0016到1016,共计17个平面。
2. UTF-32与UCS-4
在Unicode与ISO 10646合并之前,ISO 10646标准为“通用字符集”(UCS)定义了一种31位的编码形式(即UCS-4),其编码固定占用4个字节,编码空间为0x00000000~0x7FFFFFFF(可以编码20多亿个字符)。
UCS-4有20多亿个编码空间,但实际使用范围并不超过0x10FFFF,并且为了兼容Unicode标准,ISO也承诺将不会为超出0x10FFFF的UCS-4编码赋值。由此UTF-32编码被提出来了,它的编码值与UCS-4相同,只不过其编码空间被限定在了0~0x10FFFF之间。因此也可以说:UTF-32是UCS-4的一个子集。
3. UTF-16与UCS-2
除了UCS-4,ISO 10646标准为“通用字符集”(UCS)定义了一种16位的编码形式(即UCS-2),其编码固定占用2个字节,它包含65536个编码空间(可以为全世界最常用的63K字符编码,为了兼容Unicode,0xD800-0xDFFF之间的码位未使用)。例:“汉”的UCS-2编码为6C49。
但俩个字节并不足以正真地“一统江湖”(a fixed-width 2-byte encoding could not encode enough characters to be truly universal),于是UTF-16诞生了,与UCS-2一样,它使用两个字节为全世界最常用的63K字符编码,不同的是,它使用4个字节对不常用的字符进行编码。UTF-16属于变长编码。
前面提到过:Unicode编码点分为17个平面(plane),每个平面包含216(即65536)个码位(code point),而第一个平面称为“基本多语言平面”(Basic Multilingual Plane,简称BMP),其余平面称为“辅助平面”(Supplementary Planes)。其中“基本多语言平面”(0~0xFFFF)中0xD800~0xDFFF之间的码位作为保留,未使用。UCS-2只能编码“基本多语言平面”中的字符,此时UTF-16与UCS-2的编码一样(都直接使用Unicode的码位作为编码值),例:“汉”在Unicode中的码位为6C49,而在UTF-16编码也为6C49。另外,UTF-16还可以利用保留下来的0xD800-0xDFFF区段的码位来对“辅助平面”的字符的码位进行编码,因此UTF-16可以为Unicode中所有的字符编码。
UTF-16中如何对“辅助平面”进行编码呢?
Unicode的码位区间为0~0x10FFFF,除“基本多语言平面”外,还剩0xFFFFF个码位(并且其值都大于或等于0x10000)。对于“辅助平面”内的字符来说,如果用它们在Unicode中码位值减去0x10000,则可以得到一个0~0xFFFFF的区间(该区间中的任意值都可以用一个20-bits的数字表示)。该数字的前10位(bits)加上0xD800,就得到UTF-16四字节编码中的前两个字节;该数字的后10位(bits)加上0xDC00,就得到UTF-16四字节编码中的后两个字节。例如:
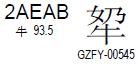 (这个字念啥?^_^)
(这个字念啥?^_^)
上面这个汉字的Unicode码位值为2AEAB,减去0x10000得到1AEAB(二进制值为0001 1010 1110 1010 1011),前10位加上D800得到D86B,后10位加上DC00得到DEAB。于是该字的UTF-16编码值为D86BDEAB(该值为大端表示,小端为6BD8ABDE)。
4. UTF-8
从前述内容可以看出:无论是UTF-16/32还是UCS-2/4,一个字符都需要多个字节来编码,这对那些英语国家来说多浪费带宽啊!(尤其在网速本来就不快的那个年代。。。)由此,UTF-8产生了。在UTF-8编码中,ASCII码中的字符还是ASCII码的值,只需要一个字节表示,其余的字符需要2字节、3字节或4字节来表示。
UTF-8的编码规则:
(1) 对于ASCII码中的符号,使用单字节编码,其编码值与ASCII值相同(详见:U0000.pdf)。其中ASCII值的范围为0~0x7F,所有编码的二进制值中第一位为0(这个正好可以用来区分单字节编码和多字节编码)。
(2) 其它字符用多个字节来编码(假设用N个字节),多字节编码需满足:第一个字节的前N位都为1,第N+1位为0,后面N-1 个字节的前两位都为10,这N个字节中其余位全部用来存储Unicode中的码位值。
| 字节数 | Unicode | UTF-8编码 |
|---|---|---|
| 1 | 000000-00007F | 0xxxxxxx |
| 2 | 000080-0007FF | 110xxxxx 10xxxxxx |
| 3 | 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
5. 总结
(1) 简单地说:Unicode属于字符集,不属于编码,UTF-8、UTF-16等是针对Unicode字符集的编码。
(2) UTF-8、UTF-16、UTF-32、UCS-2、UCS-4对比:
| 对比 | UTF-8 | UTF-16 | UTF-32 | UCS-2 | UCS-4 |
|---|---|---|---|---|---|
| 编码空间 | 0-10FFFF | 0-10FFFF | 0-10FFFF | 0-FFFF | 0-7FFFFFFF |
| 最少编码字节数 | 1 | 2 | 4 | 2 | 4 |
| 最多编码字节数 | 4 | 4 | 4 | 2 | 4 |
| 是否依赖字节序 | 否 | 是 | 是 | 是 | 是 |
参考: