源码地址:https://github.com/vergilyn/design-patterns
另外一个大神很全的Github:https://github.com/iluwatar/java-design-patterns
1. 概述
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。当这个主题对象在状态发生变化时,可以通知所有观察者对象,使它们(观察者对象)能够自动更新自己。
比如,微信用户就是观察者,微信公众号就是被观察者(主题对象),当公众号更新时会通知所有的观察者。
以上示例更形象的表述可能是:发布/订阅(publish/subscribe)。
(个人觉得)观察者模式的核心:其实就是触发及响应。所以感觉跟"责任链模式"有一定程度的类似,可能"责任链模式"的适用场景更加具体,而"观察者模式"相对就抽象很多。
2. 适用场景
-
关联行为场景,需要注意的是,关联行为是可拆分的,而不是“组合”关系。
即一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。 -
事件多级触发场景。
即一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。 -
跨系统的消息交换场景,如消息队列、事件总线的处理机制。
(事件总线)一个对象必须通知其他对象,而并不知道这些对象是谁;
需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
这些是我在网上乱七八糟看到的适用场景,能理解的很好理解,不能理解的很头疼。比如在看某些源码时,感觉像是observer-pattern,但又感觉不是...
3. 类图
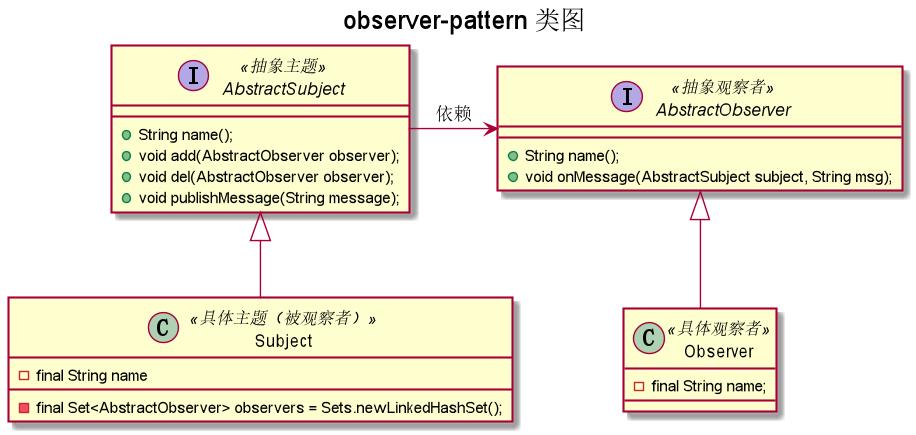
涉及到角色:
- AbstractSubject:抽象主题;
- Subject:具体主题(被观察者);重点,会用一个集合List|Map|Set来保存所有的观察者。
- AbstractObserver:抽象观察者;
- Observer:具体观察者;
注意:观察者observer与被观察者subject是相对的,某些情况下可能两者都是。
之所以要定义AbstractSubject、 AbstractObserver,主要在于对开发原则(SOLID)的考虑,解除耦合及方便扩展。
(看到有blog总结说Observer满足"开闭原则",我对SOLID理解不是那么深,只是有体会应该要依赖抽象/接口,所以才会定义AbstractSubject、 AbstractObserver)。
特别:因为我定义的是interface AbstractSubject,所以我把observers定义到了Subject。视实际情况可能会定义为abstract class AbstractSubject,然后把observers定义在其中,所有AbstractSubject的子类共享observers.
4. 最基本的示例代码
场景: subject[微信公众号],observer[微信用户]。当公众号更新时,将更新信息[message]通知所有的观察者。
特别:observer-pattern可以分为"推模型"、"拉模型",示例代码是"推模型"。
/** 抽象主题 */
public interface AbstractSubject {
String name();
void add(AbstractObserver observer);
void del(AbstractObserver observer);
void publishMessage(String message);
}
/** 抽象观察者 */
public interface AbstractObserver {
String name();
void onMessage(AbstractSubject subject, String msg);
}
/** 具体主题(被观察者)*/
public class Subject implements AbstractSubject {
private final Set<AbstractObserver> observers = Sets.newLinkedHashSet();
private final String name;
public Subject(String name) {
this.name = name;
}
@Override
public String name() {
return name;
}
@Override
public void add(AbstractObserver observer) {
observers.add(observer);
}
@Override
public void del(AbstractObserver observer) {
observers.remove(observer);
}
@Override
public void publishMessage(String message) {
for (AbstractObserver observer : observers){
observer.onMessage(this, message);
}
}
}
/** 具体观察者 */
public class Observer implements AbstractObserver {
private final String name;
public Observer(String name) {
this.name = name;
}
@Override
public String name() {
return name;
}
public void onMessage(AbstractSubject subject, String msg) {
System.out.println(String.format("observer[%s]: subject[%s], message[%s]", name, subject.name(), msg));
}
}
public class TestObserver {
public static void main(String[] args) {
AbstractSubject subject = new Subject("公众号-01");
AbstractObserver observer1 = new Observer("user-01");
AbstractObserver observer2 = new Observer("user-02");
AbstractObserver observer3 = new Observer("user-03");
subject.add(observer1);
subject.add(observer2);
subject.add(observer3);
subject.publishMessage("some message");
}
}
输出结果:
observer[user-01]: subject[公众号-01], message[some message]
observer[user-02]: subject[公众号-01], message[some message]
observer[user-03]: subject[公众号-01], message[some message]
5. 注意事项
-
(开发效率)虽然observer-pattern代码看起来很简单,但如果用于实际
业务逻辑代码,非框架级代码,用observer-pattern会让开发、调试、阅读等内容变得比较复杂。 -
(运行效率)如果一个subject有很多直接和间接的observer的话,将所有的observers都通知到会花费很多时间。
解决:
视具体情况,更多可能采用异步的方式通知各个observer。避免observer之间相互的影响。
且要注意若通知某个observer发生exception时,subject要怎么处理?是由subject处理还是由observer处理? -
(循环依赖)如果在observer和subject之间有循环依赖的话,注意避免循环调用,否则会导致系统崩溃。
-
(缺点)observer-pattern没有相应的机制让observer知道subject是怎么发生变化的,而仅仅只是知道subject发生了变化。
个人并不理解,感觉有办法能让object知道subject是怎么发生变化的啊。 -
抉择:是用"推模式",还是"拉模式"。
6. "推模型"、"拉模型"
个人认同的"推模型"、"拉模型"说法:
-
"推模型":subject维护一份observers的列表,每当有更新发生,subject会把需要的参数主动推送到各个observer。
-
"拉模型": observer维护自己所关心的subjects列表,自行决定在合适的时间(延时性)去subjects获取相应的更新数据。
我最初也没扯清楚"推模型"、"拉模型"的区别。然后去看了几篇blog,发现有两种说法,有种说法跟我最初理解的一样,但当我看见另外一种说法时,我发现更能接受"另外"的这种说法。
"推模型"、"拉模型"的区别是:如果subject是主动的一方,则是"推模型";反之,若observer是主动方,则是"拉模型"。
"推模型",如上面代码示例,是由subject维护了一份observers,由subject主动把消息推送给observer。
而如果是"拉模型",则是反过来,由observer维护一份subjects,并且是有observer定时去获取subject的信息。
(两种说法的参考blog)
-
个人认为:错误的理解
参考:http://blog.csdn.net/happyever2012/article/details/44678595
这边文章中所的"推"、"拉"跟我最初理解的一样, 但我一直感觉他们实质都是一样的。
当subject通知observer时,不管传需求的部分参数,还是把subject本身传递给observer,感觉都像"推"。所以,我就继续在网上找别的blog,找到了我认同的说法。 -
个人认为:正确的理解
参考:http://raychase.iteye.com/blog/1337015
6.1. "推模型"、"拉模型"的各自特点
"推模型"的特点:
1) 精准。如果没有更新发生,不会有任何更新消息推送的动作,即每次消息推送都发生在确确实实的更新事件之后。
2) 实时。事件发生后的第一时间即可触发通知操作。
3) 可以表达出不同事件发生的先后顺序。保证了是按事件改变顺序通知observer。
4) 因为发起方是subject,所以要在subject方指定通知的时间,避开subject自身或observer方的繁忙时段。
"拉模型"的特点:
1) 延时性。因为是定时去请求subject的信息,所以有延时性。
2) (不知道怎么描述)同样因为定时,如果长时间subject没变化,observer还是会按时去更新subject,做是否更新判断,无意义的请求获取subject。
3) 因为发起方是observer,所以要在observer方指定更新的时间,避开observer自身或subject方的繁忙时段。
这里先要明白一个概念,subject一般被认为是服务端,observer则是客户端。所以有些可能subject与observer根本不是同一个服务(不在同一套代码内)。
所以,如果需由observer自己控制自己的更新时间,那可以考虑选择"拉模型"。反之,若subject觉得这时间段subject服务器压力太大,又不是一定要马上通知各个observer,则"推模式"更容易在subject控制更新。
6.2. "推模型"、"拉模型"注意事项
1) 均无法保证事件都会响应
"推模型"中,若当subject通知observer时,某个observer客户端已经崩溃,那么要考虑subject服务端是不是要记录这次失败,重新通知这个observer直到成功。
"拉模型"中,因为延时性,subject快速的状态改变1 -> 2 -> 3,observer定时获取的值是3,那么要考虑observer是不是要获取完整的状态变化过程执行相应的逻辑代码。
2) "权限控制"交给谁?
(这可能无关"推模型"、"拉模型") 比如,"推模式"subject会把所有的触发事件都通知给全部observers,至于这个事件各个observer是不是需要处理,各个observer自己去考虑。(当然,代码完全可以写成是在服务端subject控制某个事件不通知某些observer)。
可能类似的场景如,subject服务端提供了很多免费的服务,observer客户端要用哪些自己考虑。subject服务端提供了一些收费服务,此时不管是"推模型"还是"拉模型"肯定都只能在subject服务端控制这个权限。
3) 压力交给谁去承受?
比如,若observers数据量相当庞大,subject维护这份数据压力很大(或全部通知到压力很大),则可以把关系解脱到observer去完成,即选择"拉模型"。
又或者,subject服务端觉得被一堆observer定时请求压力较大,则选择"推模型"。
以上很多都可能是我多此一举的瞎考虑, 其实这点性能差别根本不用考虑。
暂时感觉比较明显的一点,是不是要保证实时性。
实际中我看的较多都是"推模型","拉模型"少很多。比较明显的"拉模型"就是互联网页面的访问,
7. 扩展: 观察者模式 vs 责任链模式
暂时还没有仔细看"责任链模式",而且只是个人感觉"责任链模式"和"观察者模式"很相似,都是基于"因为某个东西被触发,所以需要执行操作"。只是"责任链模式"更具体,"观察者模式"的使用场景更抽象。
参考:
1. https://www.cnblogs.com/cbf4life/archive/2009/12/29/1634773.html
以上blog并没有让我明白他们之间的区别。
2. http://bbs.csdn.net/topics/330020444
可以参考,最后提到的"推模型"与"拉模型"比较有意义。但其余的回答我还是没理解。
8. 实际场景: Redisson源码中的observer-pattern(publish/subscribe)
场景简述:redisson是用redis实现分布式并发锁,当多个线程竞争同一把锁时,只会有一个线程会获得锁,此时其余线程都在等待获取锁。当持有锁线程执行完并释放锁时,需要通知其余线程去竞争获取锁。此时就是可以用publish/subscribe。
线程A先去尝试获取锁,发现已被其它线程X持有,此时线程A就subscribe竞争该锁的subject。当线程X释放锁时,及时publish通知所有的observer去竞争锁。(实际redisson中并没有通知全部的observer,而是只通知队列中的第一个竞争线程,让其获得锁。)
本来打算把redisson的相关源码贴出来,但略多,而且要解释的太多了。等写redisson源码阅读再说吧。