操作系统
1.管理软硬件资源
2.管理调度计算机内部任务
3.提供给用户和其他计算机服务接口
编码
ASSIC 每一个字符统一需要8bit来存储
MBCS
GB2312
|
分区范围
|
符号类型
|
|
第01区
|
中文标点、数学符号以及一些特殊字符
|
|
第02区
|
各种各样的数学序号
|
|
第03区
|
全角西文字符
|
|
第04区
|
日文平假名
|
|
第05区
|
日文片假名
|
|
第06区
|
希腊字母表
|
|
第07区
|
俄文字母表
|
|
第08区
|
中文拼音字母表
|
|
第09区
|
制表符号
|
|
第10-15区
|
无字符
|
|
第16-55区
|
一级汉字(以拼音字母排序)
|
|
第56-87区
|
二级汉字(以部首笔画排序)
|
|
第88-94区
|
无字符
|
|
区位码
|
区码转换
|
位码转换
|
存储码
|
|
1001H
|
10H+A0H=B0H
|
01H+A0H=A1H
|
B0A1H
|
GBK
基本简介
Big5
Unicode
方式,在ANSi编码下,同一个编码值,在不同的编码体系里代表着不同的字。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码,可能最终显示的是中文,也可能显示的是日文。在ANSI编码体系下,要想打开一个文本文件,不但要知道它的编码方式,还要安装有对应编码表,否则就可能无法读取或出现乱码。为什么电子邮件和网页都经常会出现乱码,就是因为信息的提供者可能是日文的ANSI编码体系和信息的读取者可能是中文的编码体系,他们对同一个二进制编码值进行显示,采用了不同的编码,导致乱码。这个问题促使了unicode码的诞生。
UTF-8
编程语言介绍
go ===Go语言是谷歌2009发布的第二款开源编程语言。Go语言专门针对多处理器系统应用程序的编程进行了优化,使用Go编译的程序可以媲美C或C++代码的速度,而且更加安全、支持并行进程。
推测这个未来会很火
lua = nginx 的脚本语言, ngnix 是时下最nb web服务器
lua = nginx 的脚本语言, ngnix 是时下最nb web服务器
php = 1994, 纯web开发语言, 1994 Netscape 浏览器诞生了
java = 1995 由sun 公司开发出来,java 虚拟机 支持跨平台
shell = 脚本语言, 简单易学,基于unix,linux, 做一些简单的系统管理任务, 运维人员必学
javascript = 是当下使用最为广泛的语言,主要写前端的语言,
nodejs =后端 全栈式的语言
编程语言分类
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
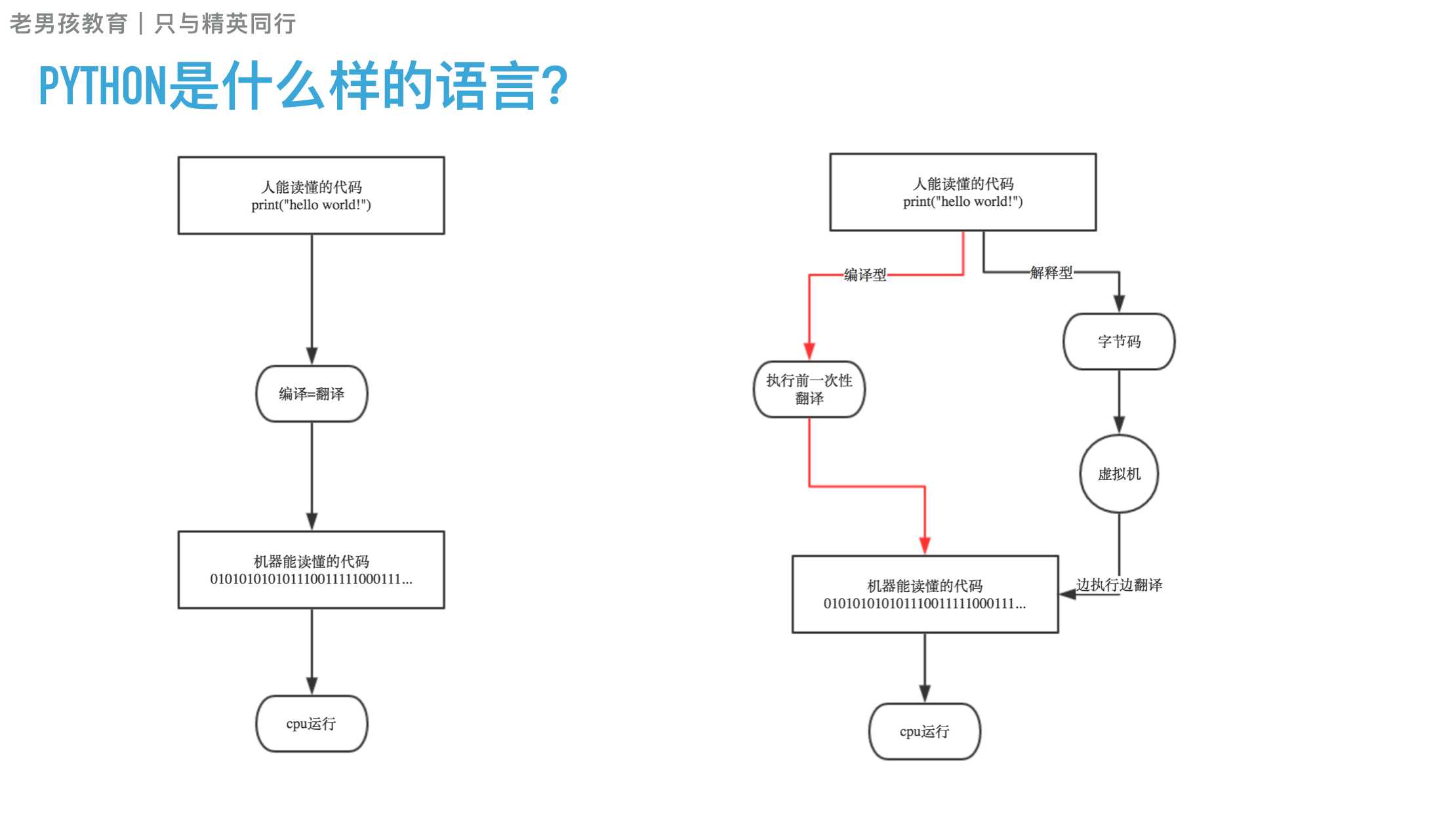
编译型vs解释型
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
编译型=全部翻译 ,再执行 ,翻译=编译 ,c ,c++
解释性=边执行边翻译 python , php ,java , c#,perl ruby javascript
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
cmd python的使用
开始-->cmd-->cd c:\\ -->dir
dir=查看当前目录文件列表 Tab键自动补全
.py是文件格式
将python安装目录 放在环境变量中
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python初探
print(" ")
变量直接写 z=x*y
变量的命名 suduentNumber 第一个不大写 或者student_number
python不区分常量或者变量 ,所以潜规则就是全部大写的变量的变量名来代表为常量
变量赋值 赋值的是变量在内存里面的值
del 变量 也就是删除变量
变量的重新指向 也是删除这块变量的内存 --------------------------------------->>>>>python里面有内存机制 但是还是自己来写一下
在python 2.0版本中 在程序中 前加上 #! -*- conding:utf-8 -*- 或者#conding :utf-8
msg=u"我爱北京天安门" #加u就会变成unicode编码
print msg
print type(msg) # 这个是打印类型
python 3.0默认支持中文不会出现乱码
str(a) 变量的强制转换