协同过滤用户相似度度量
Posted who_a
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了协同过滤用户相似度度量相关的知识,希望对你有一定的参考价值。
闵氏距离(Minkowski Distance)
![]()
当r=1时,曼哈顿距离(Manhatten)
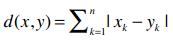
当r=2时,欧氏距离(Euclidean)

r=无穷大,上确界距离(Supermum Distance)
皮尔逊相关系数(Pearson CORRELATION Coeffcient),取值[-1,1],1表示完全相关,-1表示完全不相关
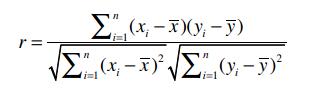
近似计算公式
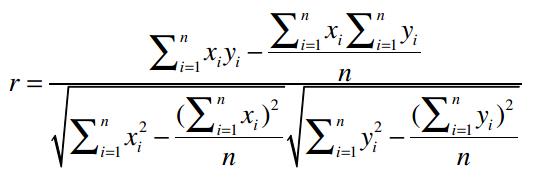
余弦相似度计算,取值[-1,1],1表示完全相似,-1表示完全不相似
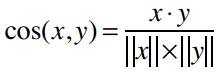
users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0, "Norah Jones": 4.5, "Phoenix": 5.0, "Slightly Stoopid": 1.5, "The Strokes": 2.5, "Vampire Weekend": 2.0},
"Bill":{"Blues Traveler": 2.0, "Broken Bells": 3.5, "Deadmau5": 4.0, "Phoenix": 2.0, "Slightly Stoopid": 3.5, "Vampire Weekend": 3.0},
"Chan": {"Blues Traveler": 5.0, "Broken Bells": 1.0, "Deadmau5": 1.0, "Norah Jones": 3.0, "Phoenix": 5, "Slightly Stoopid": 1.0},
"Dan": {"Blues Traveler": 3.0, "Broken Bells": 4.0, "Deadmau5": 4.5, "Phoenix": 3.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 2.0},
"Hailey": {"Broken Bells": 4.0, "Deadmau5": 1.0, "Norah Jones": 4.0, "The Strokes": 4.0, "Vampire Weekend": 1.0},
"Jordyn": {"Broken Bells": 4.5, "Deadmau5": 4.0, "Norah Jones": 5.0, "Phoenix": 5.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 4.0},
"Sam": {"Blues Traveler": 5.0, "Broken Bells": 2.0, "Norah Jones": 3.0, "Phoenix": 5.0, "Slightly Stoopid": 4.0, "The Strokes": 5.0},
"Veronica": {"Blues Traveler": 3.0, "Norah Jones": 5.0, "Phoenix": 4.0, "Slightly Stoopid": 2.5, "The Strokes": 3.0}
}#{用户:{作品:评分}}
def manhattan(rating1, rating2):#计算曼哈顿距离
"""Computes the Manhattan distance. Both rating1 and rating2 are dictionaries
of the form {\'The Strokes\': 3.0, \'Slightly Stoopid\': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += abs(rating1[key] - rating2[key])
commonRatings = True
if commonRatings:
return distance
else:
return -1
def pearson(rating1, rating2):#计算Pearson相关系数
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += pow(x, 2)
sum_y2 += pow(y, 2)
# now compute denominator
denominator = sqrt(sum_x2 - pow(sum_x, 2) / n) * sqrt(sum_y2 - pow(sum_y, 2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - (sum_x * sum_y) / n)/denominator
相似度的选择:
当不同用户对不同商品评价标准的范围不一样时,使用皮尔逊相关系数;
当数据稠密,且属性值大小十分重要,使用欧氏或者曼哈顿距离;
当数据稀疏,存在很多零值,考虑余弦相似度。
来自《A Programmer\'s Guide To Data Mining》
以上是关于协同过滤用户相似度度量的主要内容,如果未能解决你的问题,请参考以下文章