Kaggle新手入门之路
Posted Limitlessun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kaggle新手入门之路相关的知识,希望对你有一定的参考价值。
学完了Coursera上Andrew Ng的Machine Learning后,迫不及待地想去参加一场Kaggle的比赛,却发现从理论到实践的转变实在是太困难了,在此记录学习过程.
一:安装Anaconda
教程大多推荐使用Jupyter Notebook来进行数据科学的相关编程,我们通过Anaconda来安装Jupyter Notebook和需要用到的一些python库,按照以下方法重新安装了Anaconda,平台Win10
二:Jupyter Notebook
参照以下两篇文章配置好了Jupyter Notebook,学习了相关的基本操作
- 启动:在cmd或Anaconda Prompt下输入jupyter notebook
- 新建:Files页面右侧\'New\'
- 运行当前cell:Ctrl+Enter
- 代码补全:Tab
- 查看方法文档:Shift+Tab
- 复选cell:Shift+上下键
- 删除cell:双击D
- 撤销删除:Z
- 保存当前Notebook:S
- 关闭文档:Home页面选中文档后\'Shutdown\'
- 关闭服务器:终端中按两次Ctrl+C
- 显示matplotlib图表:%matplotlib inline
- 中断运行:I
三:Numpy
- Numpy是一个用于进行数组运算的库
- Numpy中最重要的对象是称为ndarray的N维数组类型
- 一般使用如下语句导入:import numpy as np
- 创建数组:numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
- 可以用np.dtype()定义结构体
- 数组维度:ndarray.shape
- 数组维数:ndarray.ndim
- 调整数组维度:ndarray.reshape(shape)
- 创建未初始化数组:numpy.empty(shape, dtype = float, order = \'C\')
- 创建零数组:numpy.zeros(shape, dtype = float, order = \'C\')
- 创建一数组:numpy.ones(shape, dtype = float, order = \'C\')
- 用现有数据创建数组:numpy.asarray(a, dtype = None, order = None)
- 按数值范围创建数组:numpy.arange(start = 0, stop, step = 1, dtype),类似的有linspace()和logspace()
- 切片:b=a[start:stop:step],可以用...代表剩余维度
- 整数索引:每个整数数组表示该维度的下标值,b=a[[r1, r2], [c1, c2]]
- 布尔索引:返回是布尔运算的结果的对象,可以用&或|连接()分隔的条件
- 在 NumPy 中可以对形状不相似的数组进行操作,因为它拥有广播功能,我的理解是,广播是一种维度的单方向拉伸
- 数组迭代:numpy.nditer(ndarray)或ndarray.flat
- 数组长度:len(arr)
- 访问第i个元素:一维数组用a[i],多维数组用a.flat[i]
- 数组转置:ndarray.T
- 数组分割:numpy.split(ary, indices_or_sections, axis),第二项的值为整数则表明要创建的等大小的子数组的数量,是一维数组则表明要创建新子数组的点。
- 追加值:numpy.append(arr, values, axis)
- 插入值:numpy.insert(arr, idx, values, axis)
- 删除值:numpy.delete(arr, values, axis)
- 去重数组:numpy.unique(arr, return_index, return_inverse, return_counts)
- 字符串函数:numpy.char类
- 三角函数:numpy.sin(arr),numpy.cos(arr),numpy.tan(arr)
- 四舍五入:numpy.around(arr,decimals)
- 向下取整:numpy.floor(arr)
- 向上取整:numpy.ceil(arr)
- 取倒数:numpy.reciprocal(arr),注意对于大于1的整数返回值为0
- 幂运算:numpy.power(arr,pow),pow可以是一个数,也可以是和arr对应的数组
- 取余:numpy.mod(a,b),b可以是一个数,也可以是和a对应是数组
- 最小值:numpy.amin(arr,axis)
- 最大值:numpy.amax(arr,axis)
- 数值跨度:numpy.ptp(arr,axis)
- 算术平均值:numpy.mean(arr,axis)
- 标准差:numpy.std(arr)
- 方差:numpy.var(arr)
- 副本的改变会影响原数组(赋值),视图的改变不会影响原数组(ndarray.view(),切片,ndarray.copy())
- 线性代数:numpy.linalg模块
四:Matplotlib
Jupyter Notebook Viewer的matplotlib lecture
建议先看官方教程,通过折线图熟悉基本操作,然后看入门教程第三章到第六章掌握各种图的画法
- 一般使用如下语句导入:import matplotlib.pyplot as plt
- 绘图:plt.plot(x,y),可选color,marker,label等参数,默认的x坐标为从0开始且与y长度相同的数组,x坐标与y坐标一般使用numpy数组,也可以用列表
- 设置线条:plt.setp()
- 轴名称:plt.xlable(\'str\'),plt.ylable(\'str)
- 添加文本:plt.txt(xpos,ypos,\'str\')
- 添加格子:plt.grid(True)
- 展示图片:plt.show()
- 图题:plt.title(\'str\')
- 图示:plt.legend(),结合plot()中的label参数使用
- 获取子图:plt.sublot(nrows,ncols,index)或plt.subplot2grid((nrows,ncols),(rows,cols)),可选colspan和rowspan属性
- 创建画布:plt.figure()
- 数学表达式:TeX表达式
- 非线性轴:plt.xscale(\'scale\'),plt.yscale(\'scale\'),可选参数log,symlog,logit等
- 填充颜色:plt.fill(x,y)和plt.fill_between(x,y,where=...)
- 条形图:plt.bar(x,y),注意多个条形图的默认颜色相同,应选择不同的颜色方便区分
- 直方图:plt.hist(x,bins),直方图是一种显示区段内数据数量的图像,x为数据,bins为数据区段,可选histtype,rwidth等属性
- 散点图:plt.scatter(x,y),散点图通常用于寻找相关性或分组,可选color,marker,label等属性
- 堆叠图:plt.stackplot(x,y1,y2,y3...),堆叠图用于显示部分对整体随时间的关系,通过利用plt.plot([],[],color,label)添加与堆叠图中颜色相同的空行,可以使堆叠图的意义更加清晰,可选colors等属性
- 饼图:plt.pie(slice),饼图用于显示部分对整体的关系,可选labels,colors,explode,autupct等属性
五:Pandas
上面两个教程用于速成,下面这本书是pandas的作者写的,用于仔细了解
- 一般使用如下语句导入:import pandas as pd
- Pandas是基于NumPy 的一种工具,提供了一套名为DataFrame的数据结构,比较契合统计分析中的表结构,可用Numpy或其它方式进行计算
- 创建Series:pd.Series=(data,index),Series是一维数组
- 创建DataFrame:pd.DataFrame(data,index,colums),也可以传递一个字典结构来填充data和colums,DataFrame类似于二维表格,简称df
- 查看df头尾行:df.head(i),df.tail(i),如不填参数则分别返回除了前五行/倒数前五行的内容
- 查看索引/列/数据:df.index,df.colums,df.values
- 快速统计汇总:df.descrbe()
- 数据转置:df.T
- 按轴排序:df.sort_index(axis=0,ascending=True)
- 按值排序:df.sort_values(colums,axis=0,ascending=Ture)
- 获取:df[\'columnname\']或df.columnname,会返回某列
- 通过条件选取某列:df = df[df(\'columns\') == \'a\']
- 对行切片:df[start:stop:step],利用df[n:n+1]即可获取某行
- 通过标签选择某行:df.loc[index,columname]
- 通过位置选择某行:df.iloc[indexpos,columnpos],df.iloc[i,:]可获取一行,df.iloc[:,i]可获取一列
- 布尔索引:df[bool],可以对单独的列进行判定,也可以对整个DataFrame进行判定
- 在pandas中使用np.nan代替缺失值,这些值不会被包含在计算中
- 对index和columns进行增删改:df.reindex(index,columns)
- 去掉含有缺失值的行:df.dropna(how=\'any\'),可以选择how=\'all\'只去掉所有值均缺失的行
- 补充缺失值:df.fillna(value)
- 数据应用:df.apply(func),可以是现有函数也可以是lambda函数
- 连接:pd.contact(obj),obj可以是Series,DataFrame,Panel
- 合并:pd.merge(left,right)
- 追加:df.append(data)
- 分组:df.groupby(columnname).func(),通常为分组/执行函数/组合结果
- 时间:pandas有着重采样等丰富的时间操作
- 写入CSV文件:df.to_csv(filename)
- 读取CSV文件:df.read_csv(filename),结果为DataFrame
六:Scikit-learn
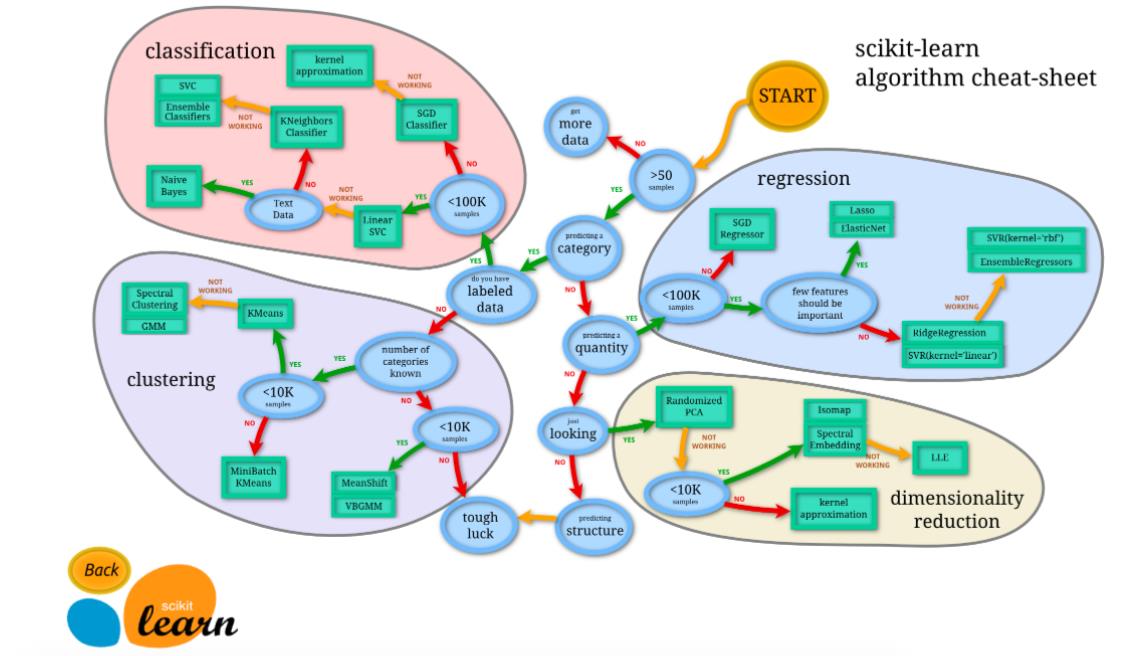
- sklearn 把所有机器学习的模式整合统一起来了,学会了一个模式就可以通吃其他不同类型的学习模式
- 步骤一般分为导入模块-创建数据-建立模型-训练-预测
特征工程:
在机器学习中,很重要的一步是对特征的处理,我们参考下文,先给出一些常用的特征处理方法在sklearn中的用法
- 标准化(需要使用距离来度量相似性或用PCA降维时):
from sklearn.preprocessing import StandardScaler data_train = StandardScaler().fit_transform(data_train) data_test = StandardScaler().fit_transform(data_test)
- 区间缩放:
from sklearn.preprocessing import MinMaxScaler data = MinMaxScaler().fit_transform(data)
- 归一化(利于计算梯度下降,消除量纲):
from sklearn.preprocessing import Normalizer data = Normalizer().fit_transform(data)
- 定量特征二值化(大于epsilon为1,小于等于epsilon为0):
from sklearn.preprocessing import Binarizer data = Binarizer(threshold = epsilon).fit_transform(data)
- 类别型特征转换为数值型特征:
实际上就是保留数值型特征,并将不同的类别转换为哑变量(独热编码),可参考:python中DictVectorizer的使用
from sklearn.feature_extraction import DictVectorizer vec = DictVectorizer(sparse = False) X_train = vec.fit_transform(X_train.to_dict(orient = \'recoed\'))
- 卡方检验:
from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 #选择K个最好的特征,返回选择特征后的数据 skb = SelectKBest(chi2, k = 10).fit(X_train, y_train) X_train = skb.transform(X_train) X_test = skb.transform(X_test)
- 互信息法:
from sklearn.feature_selection import SelectKBest from minepy import MINE #由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5 def mic(x, y): m = MINE() m.compute_score(x, y) return (m.mic(), 0.5) #选择K个最好的特征,返回特征选择后的数据 SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
- 主成分分析(PCA):
from sklearn.decomposition import PCA estimator = PCA(n_components=2)#几个主成分 X_pca = estimator.fit_transform(X_data)
学习算法:
划分训练集和测试集:
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 33)
训练:
from sklearn import LearnAlgorithm#导入对应的学习算法包 la = LearnAlgorithm() la.fit(X_train, y_train) y_predict = la.predict(x_test)
随机梯度下降法(SGD):
from sklearn.linear_model import SGDClassifier sgd = SGDClassifier() from sklearn.linear_model import SGDRegressor sgd = SGDRegressor(loss=\'squared_loss\', penalty=None, random_state=42)
支持向量机(SVM):
支持向量分类(SVC):
from sklearn.svm import SVC svc_linear = SVC(kernel=\'linear\')#线性核,可以选用不同的核
支持向量回归(SVR):
from sklearn.svm import SVR svr_linear = SVR(kernel=\'linear\')#线性核,可以选用不同的核如poly,rbf
朴素贝叶斯(NaiveBayes):
from sklearn.naive_bayes import MultinomialNB mnb = MultinomialNB()
决策树(DecisionTreeClassifier):
from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier(criterion=\'entropy\', max_depth=3, min_samples_leaf=5)#最大深度和最小样本数,用于防止过拟合
随机森林(RandomForestClassifier):
from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier(max_depth=3, min_samples_leaf=5)
梯度提升树(GBDT):
from sklearn.ensemble import GradientBoostingClassifier gbc = GradientBoostingClassifier(max_depth=3, min_samples_leaf=5)
极限回归森林(ExtraTreesRegressor):
from sklearn.ensemble import ExtraTreesRegressor() etr = ExtraTreesRegressor()
评估:
from sklearn import metrics accuracy_rate = metrics.accuracy_score(y_test, y_predict) metrics.classification_report(y_test, y_predict, target_names = data.target_names)#可以获取准确率,召回率等数据
K折交叉检验:
from sklearn.cross_validation import cross_val_score,KFold cv = KFold(len(y), K, shuffle=True, random_state = 0) scores = cross_val_score(clf, X, y, cv = cv)
或
from sklearn.cross_validation import cross_val_score scores = cross_val_score(dt, X_train, y_train, cv = K)
注意这里的X,y需要为ndarray类型,如果是DataFrame则需要用df.values和df.values.flatten()转化
Pipeline机制:
pipeline机制实现了对全部步骤的流式化封装和管理,应用于参数集在数据集上的重复使用.Pipeline对象接受二元tuple构成的list,第一个元素为自定义名称,第二个元素为sklearn中的transformer或estimator,即处理特征和用于学习的方法.以朴素贝叶斯为例,根据处理特征的不同方法有以下代码:
clf_1 = Pipeline([(\'count_vec\', CountVectorizer()), (\'mnb\', MultinomialNB())]) clf_2 = Pipeline([(\'hash_vec\', HashingVectorizer(non_negative=True)), (\'mnb\', MultinomialNB())]) clf_3 = Pipeline([(\'tfidf_vec\', TfidfVectorizer()), (\'mnb\', MultinomialNB())])
特征选择:
from sklearn import feature_selection fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=per) X_train_fs = fs.fit_transform(X_train, y_train)
我们以特征选择和5折交叉检验为例,实现一个完整的参数选择过程:
from sklearn import feature_selection from sklearn.cross_validation import cross_val_score percentiles = range(1,100) results= [] for i in percentiles: fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=i) X_train_fs = fs.fit_transform(X_train, y_train) scores = cross_val_score(dt, X_train_fs, y_train, cv = 5) results = np.append(results, scores.mean()) opt = np.where(results == results.max())[0] fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=opt) X_train_fs = fs.fit_transform(X_train, y_train) dt.fit(X_train_fs, y_train) y_predict = dt.predict(x_test)
超参数:
超参数指机器学习模型里的框架参数,在竞赛和工程中都非常重要
集成学习(Ensemble Learning):
通过对多个模型融合以提升整体性能,如随机森林,XGBoost,参考下文:
Ensemble Learning-模型融合-Python实现
多线程网格搜索:
用于寻找最优参数,可参考下文:
from sklearn.cross_validation import train_test_split from sklearn.grid_search import GridSearchCV X_train, X_test, y_train, y_test = train_test_split(news.data[:3000], news.target[:3000], test_size=0.25, random_state=33) from sklearn.svm import SVC from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.pipeline import Pipeline clf = Pipeline([(\'vect\', TfidfVectorizer(stop_words=\'english\', analyzer=\'word\')), (\'svc\', SVC())]) parameters = {\'svc__gamma\': np.logspace(-2, 1, 4), \'svc__C\': np.logspace(-1, 1, 3)} gs = GridSearchCV(clf, parameters, verbose=2, refit=True, cv=3, n_jobs=-1) %time _=gs.fit(X_train, y_train) gs.best_params_, gs.best_score_ print gs.score(X_test, y_test)
七:Kaggle
学习完以上内容后,可以参考下文,已经可以完成一些较为简单的kaggle contest了
以上是关于Kaggle新手入门之路的主要内容,如果未能解决你的问题,请参考以下文章