re模块 正则表达式
Posted wzqwer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了re模块 正则表达式相关的知识,希望对你有一定的参考价值。
在线测试工具 http://tool.chinaz.com/regex/
首先你要知道的是,谈到正则,就只和字符串相关了。在我给你提供的工具中,你输入的每一个字都是一个字符串。
其次,如果在一个位置的一个值,不会出现什么变化,那么是不需要规则的。
比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上。这连python的字符串操作都可以轻松做到。
那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
1.字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
2.字符

3.量词
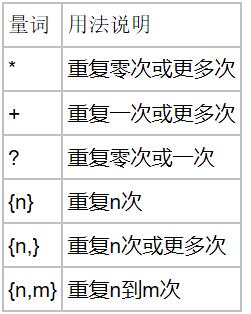
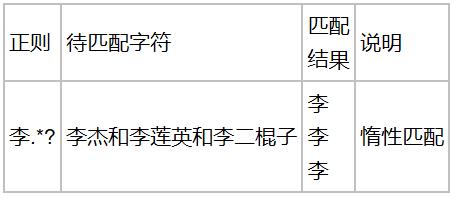
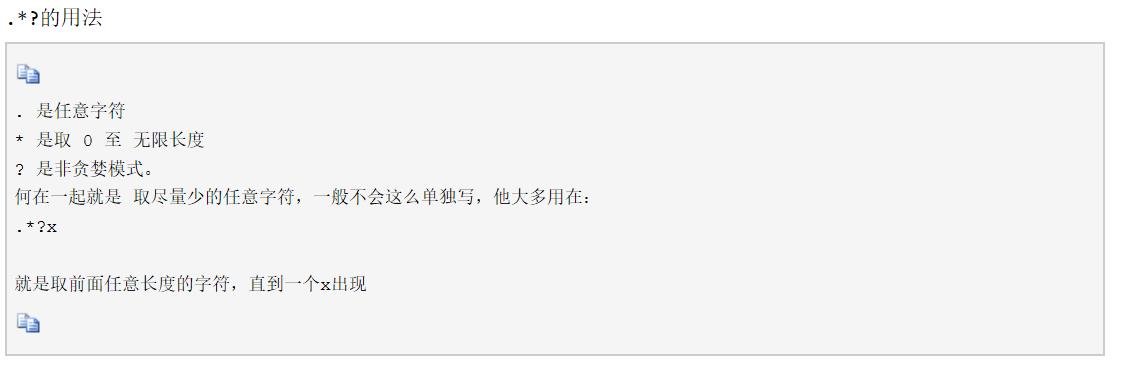
4.贪婪匹配 和 惰性匹配

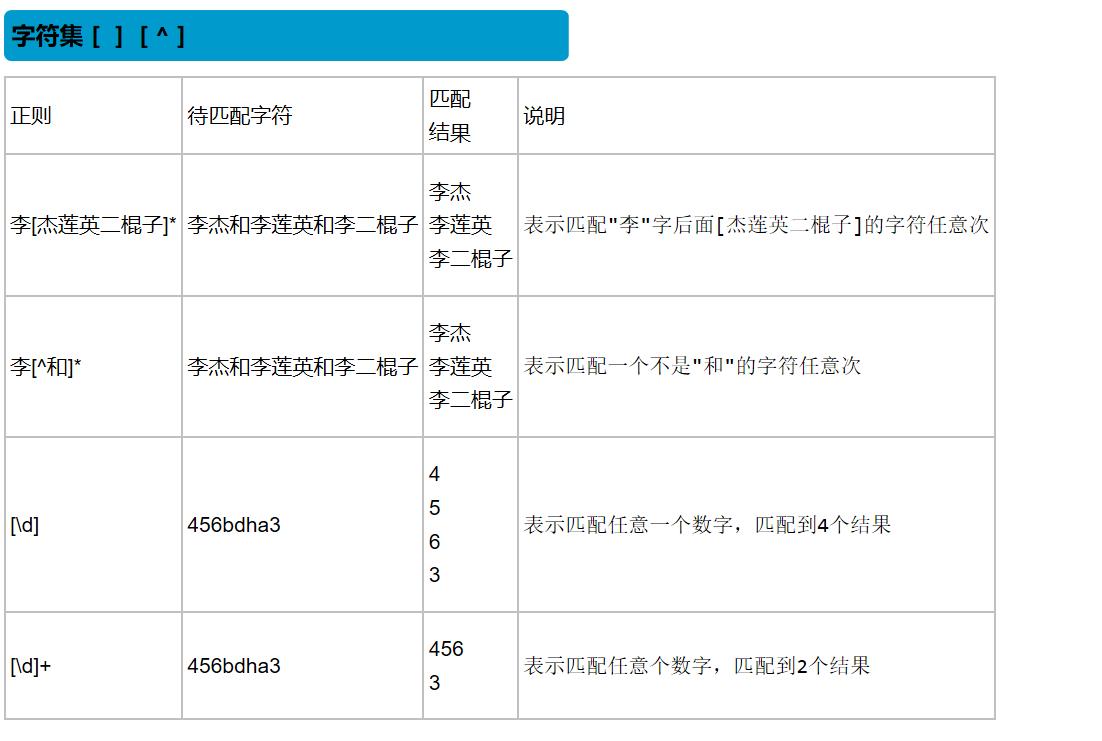
字符集
转义字符

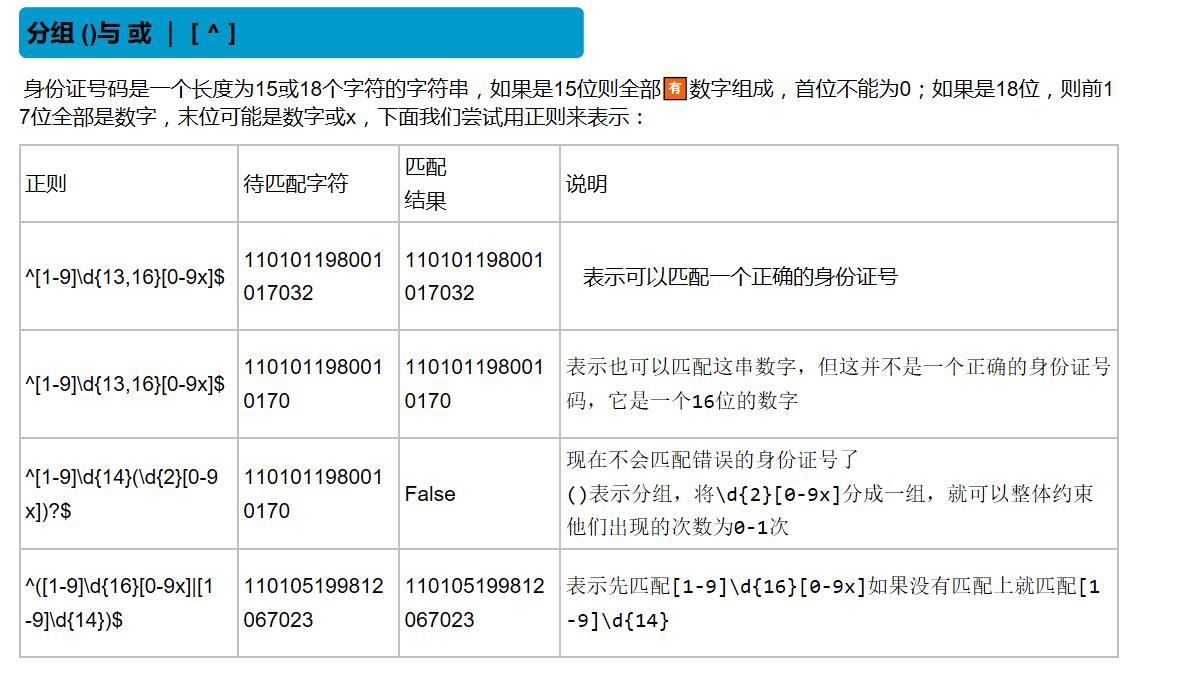
分组与或

re模块下的常用方法
import re ret = re.findall(\'a\', \'eva egon yuan\') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : [\'a\', \'a\'] ret = re.search(\'a\', \'eva egon yuan\').group() print(ret) #结果 : \'a\' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match(\'a\', \'abc\').group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : \'a\'
import re ret = re.split(\'[ab]\', \'abcd\') # 先按\'a\'分割得到\'\'和\'bcd\',在对\'\'和\'bcd\'分别按\'b\'分割 print(ret) # [\'\', \'\', \'cd\'] ret = re.sub(\'\\d\', \'H\', \'eva3egon4yuan4\', 1)#将数字替换成\'H\',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn(\'\\d\', \'H\', \'eva3egon4yuan4\')#将数字替换成\'H\',返回元组(替换的结果,替换了多少次) print(ret)
import re obj = re.compile(\'\\d{3}\') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search(\'abc123eeee\') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 ret = re.finditer(\'\\d\', \'ds3sy4784a\') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
注意: 1 findall的优先级查询:
import re ret = re.findall(\'www.(baidu|oldboy).com\', \'www.oldboy.com\') print(ret) # [\'oldboy\'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall(\'www.(?:baidu|oldboy).com\', \'www.oldboy.com\') print(ret) # [\'www.oldboy.com\']
2 split的优先级查询
ret=re.split("\\d+","eva3egon4yuan") print(ret) #结果 : [\'eva\', \'egon\', \'yuan\'] ret=re.split("(\\d+)","eva3egon4yuan") print(ret) #结果 : [\'eva\', \'3\', \'egon\', \'4\', \'yuan\'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
匹配标签
import re
ret = re.search("<(?P<tag_name>\\w+)>\\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group(\'名字\')拿到对应的值 print(ret.group(\'tag_name\')) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> ret = re.search(r"<(\\w+)>\\w+</\\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group()) #结果 :<h1>hello</h1>
匹配整数
import re ret=re.findall(r"\\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #[\'1\', \'2\', \'60\', \'40\', \'35\', \'5\', \'4\', \'3\'] ret=re.findall(r"-?\\d+\\.\\d*|(-?\\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #[\'1\', \'-2\', \'60\', \'\', \'5\', \'-4\', \'3\'] ret.remove("") print(ret) #[\'1\', \'-2\', \'60\', \'5\', \'-4\', \'3\']
爬虫练习
import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode(\'utf-8\') def parsePage(s): com = re.compile( \'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\\d+).*?<span class="title">(?P<title>.*?)</span>\' \'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>\', re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = \'https://movie.douban.com/top250?start=%s&filter=\' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\\n") count = 0 for i in range(10): main(count) count += 25


flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \\w, \\W, \\b, \\B, \\s, \\S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\\w \\W \\s \\S \\d \\D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
以上是关于re模块 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章