Deep Learning for Information Retrieval
Posted 笨兔勿应
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep Learning for Information Retrieval相关的知识,希望对你有一定的参考价值。
最近关注了一些Deep Learning在Information Retrieval领域的应用,得益于Deep Model在对文本的表达上展现的优势(比如RNN和CNN),我相信在IR的领域引入Deep Model也会取得很好的效果。
IR的范围可能会很广,比如传统的Search Engine(query retrieves documents),Recommendation System(user retrieves items)或者Retrieval based Question Answering(Question retrieves answers)可能都可以属于IR的范畴。仔细考虑这些应用,不难看出他们都存在一个模式,也就是几个基本需要解决的任务:
- Query(Intent)的表达和Document(Content)的表达?
- Matching Model:maps query-document pairs to a feature vector representation where each component reflects a certain type of similarity, e.g., lexical, syntactic, and semantic。或者这里根据matching vector与参数w直接得到matching score,相当于做了内积。
- Ranking Model:接受q-d的matching结果(matching vector或matching score),在当前end-to-end的训练框架下,其实使用matching score更方便一点(为什么更方便一点本文后面会说明),然后使用learning to rank的方法(pointwise,pairwise或listwise)来进行训练,重点是如何设计loss function。
下面我主要参考Li Hang在sigir 2016上的tutorial(http://t.cn/Rt7OK2w)来组织我的笔记,同时会重点阅读几篇有代表性的论文来更好的理解细节。一句话,希望学习可以既见森林,又可见树木。
我主要从以下四个部分来讲解:
- IR的基础
- 相关的Deep Learning模型(Word Embedding,RNN和CNN)
- Deep Learning for IR的基础性问题
- Deep Learning for IR的具体应用
IR的基础
下图展现了Information Retrieval的一个整体构架,

传统的IR使用向量空间模型(VSM)来计算query和document的相似度,具体方法如下:
- Representing query and document as tf-idf (or BM25) vectors
- Calculating cosine similarity between them
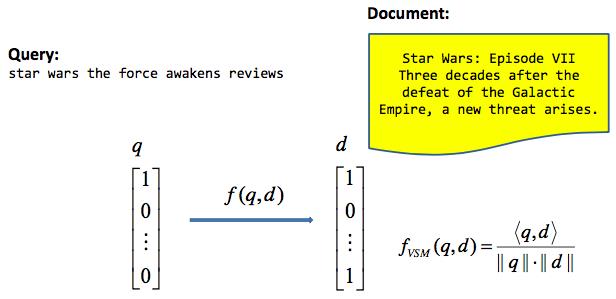
现代的IR使用了一个更加general的框架来处理similarity的问题:
- Conducting query and document understanding
- Representing query and document as feature vectors
- Calculating multiple matching scores between query and document (Matching Model)
- Training ranker with matching scores as features using learning to rank (Ranking Model)
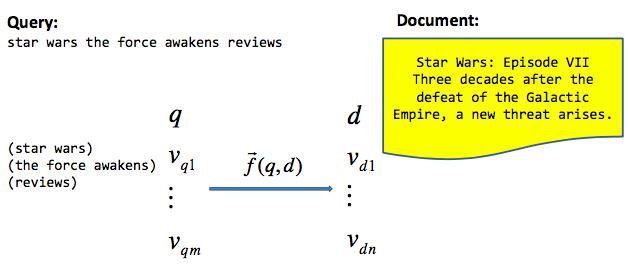
一般这四个步骤都是在一个end-to-end的神经网络结构下进行训练的。这里注意,Matching Model只有唯一一个,就是说所有的query-document对都使用一个Matching Model,Ranking Model只使用这唯一一个Matching Model产生的Matching Score或Matching Vector。
Deep Learning的方法可以渗透在IR中的不同步骤中,如下图所示,一般包括了Intent和Content的表示和Matching Model的学习。
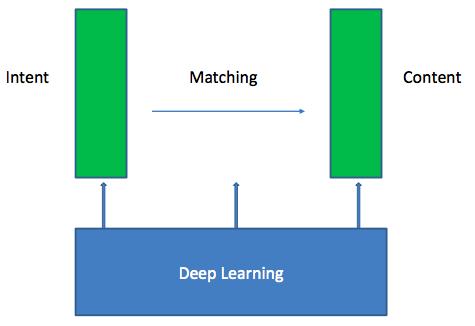
注意,这里并没有说明Ranking Model,其实Ranking Model可以看做整个神经网络结构的loss function层,不同的learning to rank方法有不同的loss形式,本文只讨论pointwise和pairwise方法,因为这两种方法效率足够高,在实践中应用的最多。
同时,本文重点考察两种工业中应用最多的训练数据形式。
- 第一种形式,数据提供了某个query对应的完全的document的排序(或relevance值);
- 第二种形式,数据只提供了某个query对应的一个或几个相关document,其他document并不知道相关性,具体类似推荐系统的数据。
其实,在工业环境中第二种数据形式是最普遍的,由于本身只有正样本,所以需要进行随机负采样,来构造一种排序关系。同时loss function也可以使用pointwise或pairwise的方法,pointwise方法直接把问题当做二分类问题来做;pairwise使用了正样本和每个负样本的偏序关系,可以使用RankSVM的形式(hinge loss)或RankNet的形式(cross entropy loss)。
相关Deep Learning模型的基础
Word Embedding
Word Embedding的教程可以参考《word2vec中的数学原理详解》,我觉得这篇文章讲的很详细也很生动。
RNN
RNN的教程可以参考我之前写的tutorial https://github.com/pangolulu/rnn-from-scratch,其中也包含了很多拓展的资料。
CNN
CNN for text可以参考这篇论文https://arxiv.org/pdf/1408.5882v2.pdf,他将CNN模型应用到了sentence classification的问题上,并取得了state-of-art的效果。
Deep Learning for IR的基础性问题
Representation Learning
Word Embedding的出现使得我们可以使用低维的向量空间来表示Word的语义,避免了使用one-hot表示产生了一些问题,比如维度高、one-hot词向量间无法表达相关性等等。这种embedding的方法称为hierarchy representation。
那么,如何将一段文本表示成embedding的形式呢?也就是sentence representation或document representation,目的是represent syntax, semantics, and even pragmatics of sentences。目前有很多研究工作可以应用,对于sentence的表示可以使用rnn或cnn,对于document的表示会复杂一点,可以参考Hierarchical Attention Networks for Document Classification和Convolutional Neural Network Architectures for Matching Natural Language Sentences这两篇工作。它们主要的思想其实就是使用cnn或rnn来表示document中的sentences,然后使用表示好的sentence vectors作为另外的rnn的输入来最终表示整个document。
一般CNN或RNN会随着整个网络进行end-to-end的训练,也就是Task-dependent的,也是有监督的。
Representation Learning是整个IR或NLP task的基础,无论是Classification的问题,Matching的问题,还是Translation的问题,都需要先学习一个document或sentence的中间表示。可以看下面的示意图,表示IR或NLP不同任务之间的关系,和representation learning所处的位置。
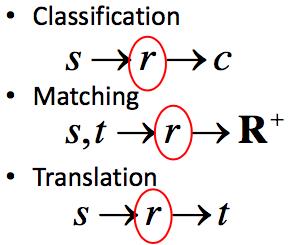
Matching Model
Matching是IR任务中重要的一步,意义是maps query-document pairs to a feature vector representation where each component reflects a certain type of similarity, e.g., lexical, syntactic, and semantic。这里产生的是一个matching vector,接下来可以根据matching vector与参数w直接得到matching score(比如做内积)。
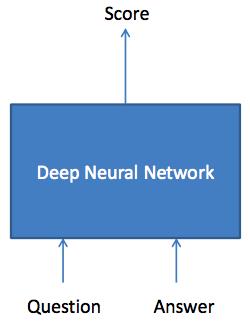
Maching Model产生的结果(matching vector或matching score)接下来会作为ranking model的输入,ranking model其实相当于整个网络的loss function,在当前end-to-end的训练框架下,其实使用matching score更方便一点。之后可以看到,使用matching vector + LTR的方法和使用maching score + ranking loss的方法一定程度上是等价的(这里只考虑pointwise和pairwise方法),而且后面一种形式更加general,它包含了传统的LTR的表达,也可以做一些变化,比如做一些negative sampling等等。之后在Ranking Model的讲解会重点介绍几篇论文中常见的ranking loss的形式,并且说明一下LTR方法使用matching vector和使用matching score的等价性。
好,现在我们重点讲解使用深度学习来做Matching的方法。一般Matching的方法有三种形式:
- Projection to Latent Space
- One Dimensional Matching
- Two Dimensional Matching
- Tree Matching
本文暂时只讨论前三种。
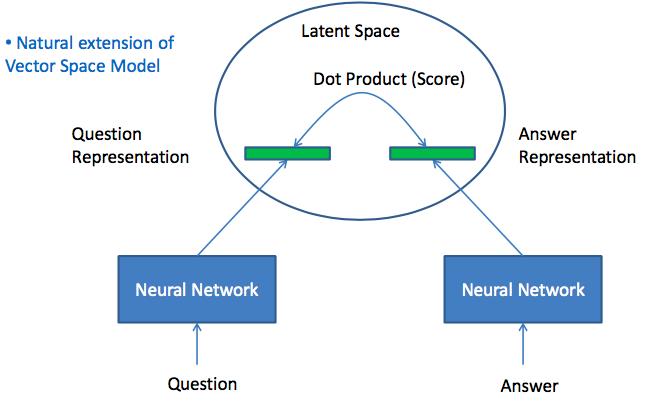
Matching: Projection to Latent Space
类似于VSM的方法
Matching: One Dimensional Matching
应用的比较多,可以在这个基础上融合不同的matching方法得到的结果,比如融入了第一种matching方法(query和document的vector做内积)。

Matching: Two Dimensional Matching
直接生成二维的matching score,然后用cnn模型进行学习。
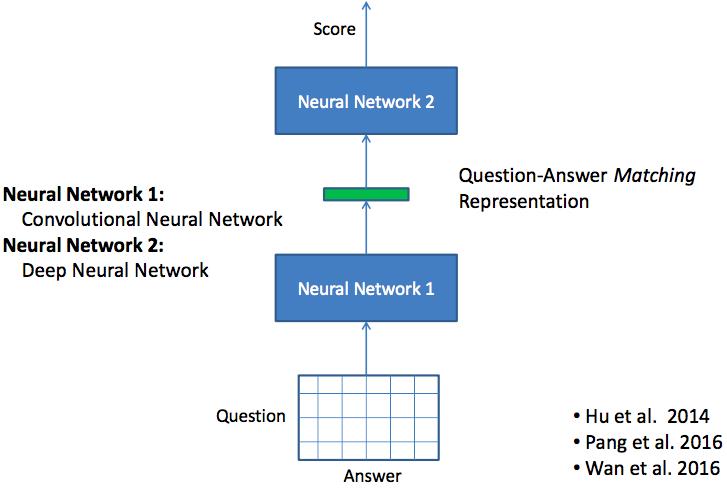
有一些研究的结论,如下:
- 对于sentence的表示学习,cnn方法要比rnn方法好,这个有待于验证。
- 2-dimensional CNN比1-dimensional CNN方法好
- Matching scores can be used as features of learning to rank models,这个方法相当于可以融合不同方法得到的matching score,然后组成一个matching vector。
Ranking Model
也就是大家熟知的Learning to Rank,不过我这里想解释的更加general一点,可能在构造训练集上和LTR有一些不同。
先说一下问题的定义,假设我有query q和候选的document集合D={d1, d2, ..., dn}。对于训练集,首先必须再次强调一下训练数据的形式:
- 第一种形式,数据提供了某个query对应的完全的document的排序(或relevance值);
- 第二种形式,数据只提供了某个query对应的一个或几个相关document,其他document并不知道相关性,具体类似推荐系统的数据。
然后说一下LTR的输入,LTR接受Matching Model得到的结果,即可以使Matching Vector或者是Matching Score。
对于第一种形式的数据,可以采用传统的LTR方法:
- pointwise方法直接当做回归问题,可以看到Matching Score就可以看做是回归的值了,如果使用Matching Vector作为输入,相当于继续使用一些参数W做了一次回归问题。但其实这是可以通过神经网络end-to-end学习出来的,相当于整个网络(包括Representation Learning和Matching Model)的目标函数就是回归问题(损失函数为最小二乘)。
- pairwise方法考虑了document集合中两两document的偏序关系,由此构造训练集。考虑所有两两的document,比如
d1和d2,如果训练集中d1 > d2,那么我们希望通过Matching Model得到的d1和d2对应的Matching Scorem1要大于m2。在上面的intuition的指导下,我们可以定义不同的loss function了,最常见就是hinge loss function,也就是我们希望m1比m2要至少大于一个值,对应了SVM中的1,具体可以写成max(0, theta - m1 + m2)。这个Hinge Loss的定义方法其实就是RankSVM的方法,不过传统的RankSVM的定义使用了Matching Vector作为输入,比如v1和v2,并且重新构造了训练集,v1 - v2对应的label为+1(正类),v2 - v1对应的label为-1(负类)。大家可以看一下RankSVM的公式形式,不难会发现RankSVM和我这里表达的定义其实是等价的,感兴趣的同学可以参考http://www.cnblogs.com/kemaswill/p/3241963.html。其实,对于RankNet也是相同的道理,感兴趣的可以参考http://www.cnblogs.com/kemaswill/p/kemaswill.html。
对于第二种形式的数据,训练数据中只提供了某个query对应的一个或几个相关document,其他document并不知道相关性。由于只提供了正反馈的数据,目前主流的做法就是进行contrastive sampling,也就是随机负采样。当有了负样本之后,相当于可以得到document之间的偏序关系了,就可以使用LTR的方法,这里面我倾向于称为ranking loss,也包括了pointwise和pairwise这两种方法:
- pointwise方法直接把问题当做二分类来做,正相关的document为正例,采样的负相关的数据为负例。如果接收Matching Score,可以在外面套一层sigmoid函数转化成概率,使用交叉熵损失函数进行训练;如果接收Matching Vector,相当可以再做一次logistics regression,但其实和前面方法是等价的。
- pairwise方法是目前主流的做法,对一个query来说正相关的document偏序关系要大于这个query下随机采样的负相关的document,采样的个数可以作为一个超参数。这样可以使用和第一种数据形式的pairwise方法设计ranking loss了,这里不再赘述。一般文献里面都会使用hinge loss,表达示为
e(x, y_pos, y_neg) = max(0, theta - s_match(x, y_pos) + s_match(x, y_neg)),其中x为query,y_pos为正相关document,y_neg为负相关document,s_match为Matching Model得到的Matching Score。
Deep Learning for IR的具体应用
Document Retrieval
这里考虑Learning to Rank for Document Retrieval,下图是整体的构架图,可以看到系统直接返回Ranking Model,相当于Matching Model和Ranking Model以一起学出来的。
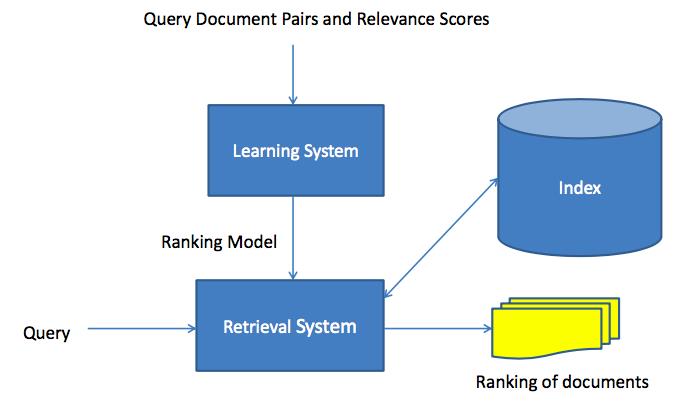
具体有一下几点考虑:
- simultaneously learn matching model and ranking model
- Matching model: Projection into Latent Space, Using CNN
- Ranking model: taking matching model output as features, as well as other features, Using DNN
比较重要的就是Matching Model和Ranking Model的关系,下图直观的表示出来:
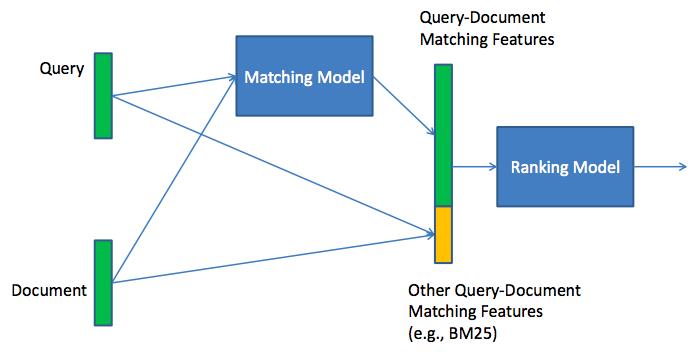
其实,在我看来图中最后都会输出一个score,这个score就是matching score,而这个是最重要的。
下面给出一篇论文的网络结构图,这篇论文发表在sigir 2015,叫做Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks,有兴趣的同学可以回去精读。
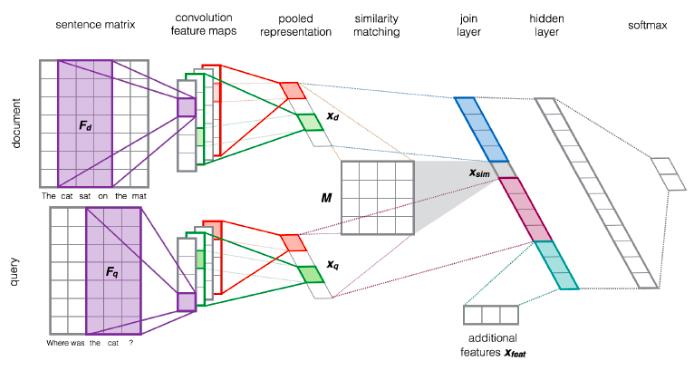
首先,这篇论文使用了pointwise的方法,所以是一个二分类问题;使用CNN来对query和document学习representation;使用一个双线性函数来match query-vector和document-vector(q_vec M d_vec的内积);之后与query-vector和document-vector或者加上其他feature一同连接成一个feature vector,这个就是Matching Vector;网络后几层经过若干fully connected层,最后会得到一个实数,就是Matching Score;由于是一个二分类问题,Matching Score外面套一层sigmoid函数转换成概率,使用交叉熵损失函数进行训练。
Retrieval based Question Answering
Retrieval based QA其实和Document Retrieval没有什么区别,下图给出了一个整体的框架图:
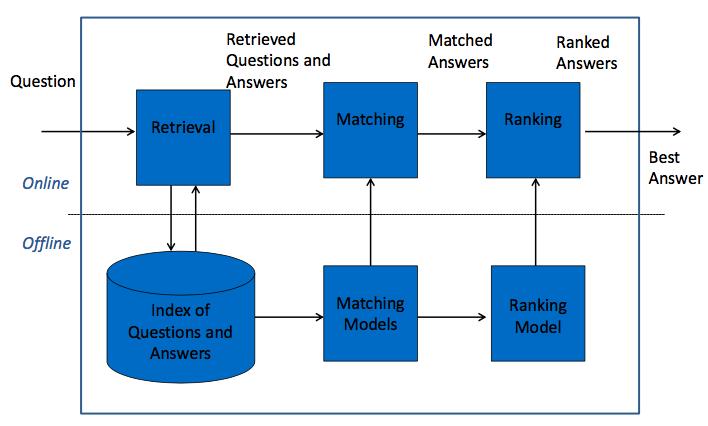
具体的一篇论文可以参考李航发表在nips 2015的文章,题目叫Convolutional Neural Network Architectures for Matching Natural Language Sentences。文中也是用了CNN来学习sentence的表示,但文中提出了两种Matching Model结构,一种是One Dimensional Matching,另一种是Two Dimensional Matching。分别表示如下图所示:
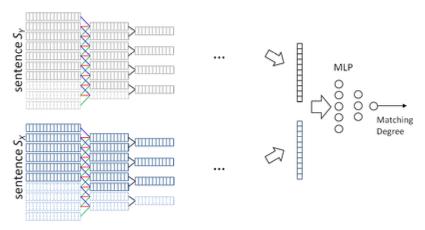
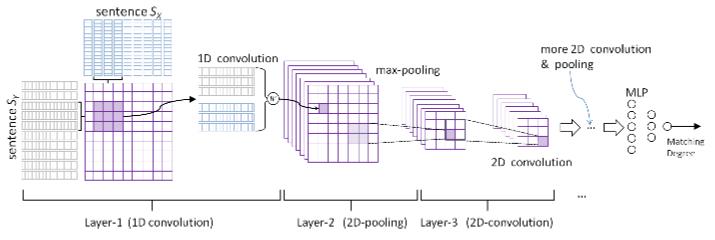
最后Matching Model会生成一个Matching Score,正如我在这篇博文阐述的一样。
对于Ranking Model,也就是ranking loss,这篇文章使用了pairwise的方式,使用了hinge loss function,具体为:e(x, y+, y−) = max(0, 1 + s(x, y−) − s(x, y+))。其中,y+比y- match x的分数要高,也就是y+排在y-之前;s(x, y)是x和y的matching score。
Image Retrieval
这个任务的意义是用文字来搜索图,反过来或者用图来搜索文字。一个整体的示意图如下:
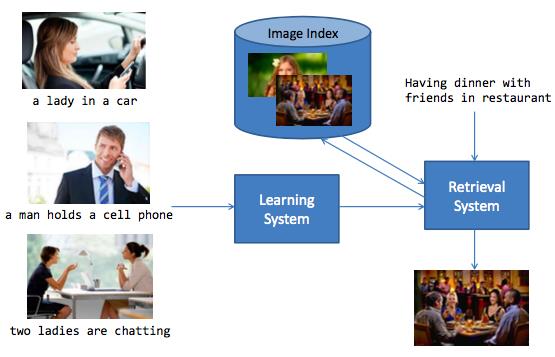
具体的一篇论文也是来自李航老师的,发表在ICCV 2016,题目叫作Multimodal Convolutional Neural Networks for Matching Image and Sentence。这篇论文使用了Multimodal CNN的方法,具体为:
- Represent text and image as vectors and then match the two vectors
- 三种matching方法:Word-level matching, phrase-level matching, sentence-level matching
- CNN model works better than RNN models (state of the art) for text
其中sentence-level matching和Word-level matching的示意图如下:
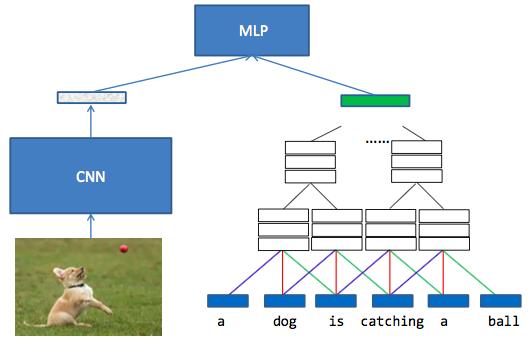
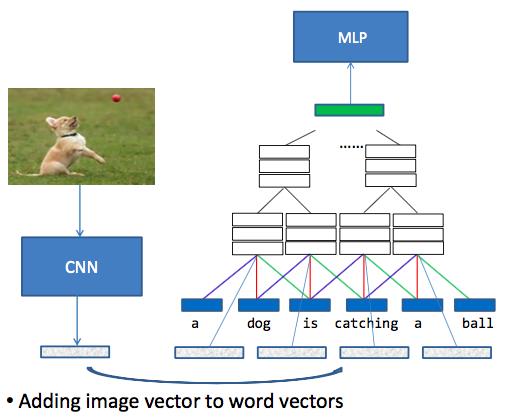
最后网络会输出一个Matching Score,这篇文章也使用了pairwise方法,但是训练数据没有负相关样本,所以使用了随机负采样的方法;loss function选择了hinge loss,具体形式为e_θ(xn, yn, ym) = max(0, theta − s_match(xn, yn) + s_match(xn, ym),其中ym是随机采样的负样本。
总结一下,可以看到,无论是Document Retrieval,Retrieval based Question Answering还是Image Retrieval,它们的模式都已一样的,都包括了三个基本要素:Representation Learning,Matching Model和Ranking Model。
总结
本文在于帮助梳理一下这种retrieve,match,similarity或者说recommend等一类问题的一些模式和关键要素,使点连成线,在大脑中构建真正的理解,能做到举一反三,遇到相似的任务能很自然的联想过去。大家如果有什么意见或想法,欢迎在下面留言。
Reference
- Convolutional Neural Network Architectures for Matching Natural Language Sentences, nips 2015
- Learning to Rank Short Text Pairs with Convolutional Deep Neural Networks, sigir 2015
- Multimodal Convolutional Neural Networks for Matching Image and Sentence, iccv 2016
- TOWARDS UNIVERSAL PARAPHRASTIC SENTENCE, ICLR 2016
- deep_learning_for_information_retrieval, sigir 2016 tutorial
以上是关于Deep Learning for Information Retrieval的主要内容,如果未能解决你的问题,请参考以下文章