并发下诡异的HashMap
Posted 一缕清风007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发下诡异的HashMap相关的知识,希望对你有一定的参考价值。
最近研读《Java高并发程序设计》葛一鸣、郭超编著,读到2.8.3时,题目便是并发下诡异的HashMap,摘抄如下:
-----------摘抄开始--------------
HashMap同样不是线程安全的。当你使用多线程访问HashMap时,也可能会遇到意想不到的错误。不过和ArrayList不同,HashMap的问题似乎更加诡异。
package cn.baokx;
import java.util.HashMap;
import java.util.Map;
public class HashMapMultiThread {
static Map<String,String> map = new HashMap<String,String>();
public static class AddThread implements Runnable{
int start = 0 ;
public AddThread(int start){
this.start = start;
}
@Override
public void run() {
for (int i = 0; i < 100000; i+=2) {
map.put(Integer.toString(i), Integer.toBinaryString(i));
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new HashMapMultiThread.AddThread(0));
Thread t2 = new Thread(new HashMapMultiThread.AddThread(1));
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(map.size());
}
}
上述代码使用t1和t2两个线程同时对HashMap进行put()操作,如果一切正常,我们期望得到的map.size()就是100000.但实际上,你可能会得到以下三种情况(注意,这里使用JDK7进行试验):
第一:程序正常结束,并且结果也是符合预期的。HashMap的大小为100000.
第二:程序正常结束,但结果不符合预期,而是一个小于100000的数字,比如98868.
第三:程序永远无法结束。
对于前两种可能,和ArrayList的情况非常类似,因此,不必过多解释。而对于第三种情况,如果是第一次看到,我想大家一定会觉得特别惊讶,因为看似非常正常的程序,怎么可能就结束不了呢?
注意:请读者谨慎尝试以上代码,由于这段代码很可能占用两个CPU核,并使它们的CPU占有率达到100%。如果CPU性能较弱,可能导致死机。请先保存资料再进行尝试。
打开任务管理器,你会发现,这段代码占用了极高的CPU,最有可能的表示是占用了两个CPU核,并使得这两个核的CPU使用率达到100%。这非常类似死循环的情况。
使用jstack工具显示程序的线程信息,如下所示。其中jps可以显示当前系统中所有的java进程。二jstack可以打印给定的java进程的内部线程及其堆栈。

我们会很容易找到我们的t1、t2和main线程:
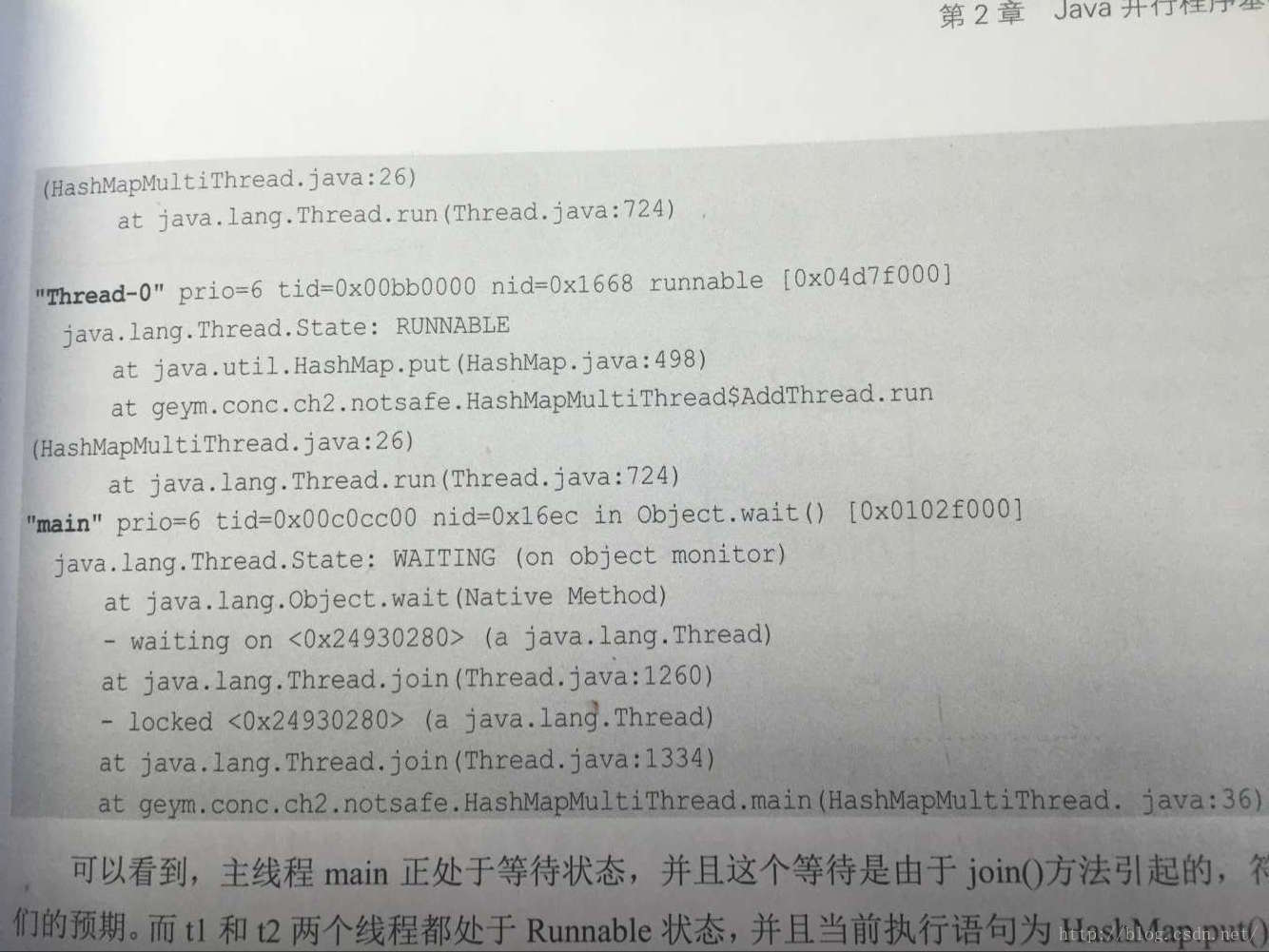
可以看到,主线程main处于等待状态,并且这个等待是由于join方法引起的,符合我们的预期,二t1和t2两个线程都处于Runnable状态,并且当前执行语句为HashMap.put()方法。查看put()方法的第498行代码,如下所示:
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
这个死循环的问题,如果一旦发生,着实可以让你郁闷一把。本章的参考资料中也给出了一个真实的按理。但这个死循环的问题在JDK8中已经不存在了。由于JDK8对HashMap的内部做了大规模的调整,一次规避了这个问题。但即使这样,贸然在多线程环境下使用HashMap一人会导致内部数据不一致。最简单的解决方案就是使用ConcurrentHashMap代替HashMap。
-----------摘抄结束--------------
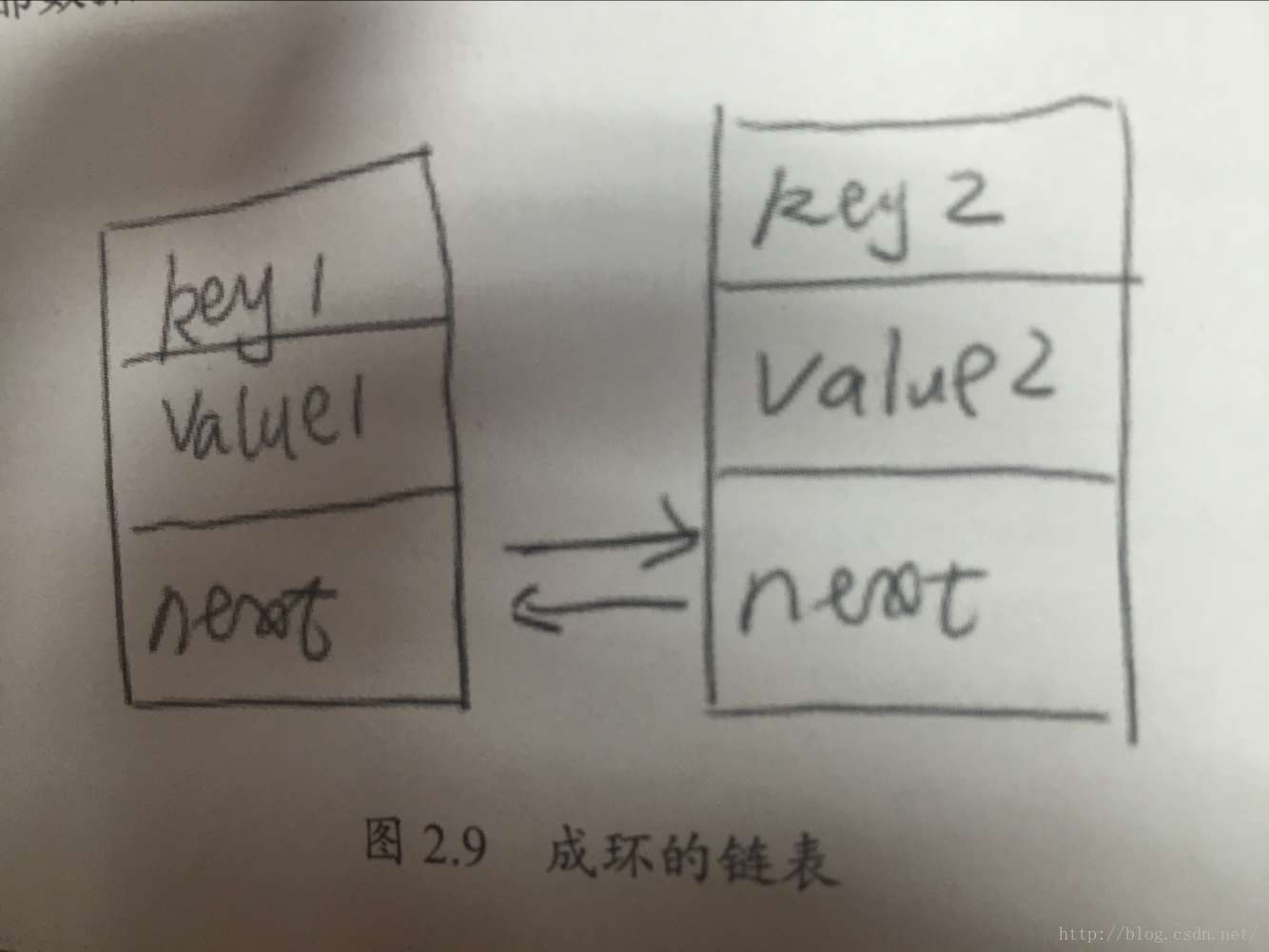
以上内容为书上内容的摘抄,看完以后对红色标注的部分"但在此时此刻,由于多线程的冲突,这个链表的结构已经遭到破坏,链表成环了!"无法理解,到底是什么情况下导致链表成环了呢?书中并没有展开,通过自己最近几天的查询和学习,确认了链表成环的原因,在此分享出来。
HashMap内部通过一个Entry<K,V>[] table来存储数据,当调用put方法时,根据key的hashcode进行Hash计算,得出一个数组下标,然后将Entry对象放至相应位置,在这种情况下可能发生不同的hashcode进行Hash计算得到的下标相同的情况,这种情况下,会将Entry进行链式存储(Entry内部本身定义了Entry类型的next属性,据此实现链式存储),和ArrayList一样,table的长度会有一个初始值(HashMap默认为16)和load_factor(默认0.75f),当数组的“使用率(即不为空的元素数量/长度)”达到load_factor时,就需要对数组进行扩容,扩容的时候需要定义一个新的数组,并把旧的数组中的Entry分配到新的数组中。
对于HashMap内部的存储方式,可参考博客,http://blog.csdn.net/baokx/article/details/51426899,里面讲的比较详细。
源代码分析如下所示:
//注意put方法是有返回值的
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//HashMap允许有一个key为null的键值对
if (key == null)
return putForNullKey(value);
int hash = hash(key);
//计算下标
int i = indexFor(hash, table.length);
//循环下标处的Entry链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//hash值相等且key==或equals匹配,则替换value值并把旧值返回
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//若循环Entry链表未匹配到,则加一个Entry
addEntry(hash, key, value, i);
return null;
}
//新增一个Entry
void addEntry(int hash, K key, V value, int bucketIndex) {
//若满足条件则需要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//扩容
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//创建一个容量更大的新的数组
Entry[] newTable = new Entry[newCapacity];
//将旧数组中的Entry数据转移至新的数组
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
//转移数据
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
//注意
e.next = newTable[i];
//注意
newTable[i] = e;
e = next;
}
}
}注意:上面的transfer方法,在多线程的情况下,会出现 newTable [ i ].next=newTable[i]的情况,这也是文中提到的链表成环的原因。
为了验证我们的判断,在创建数组的时候未数组提供初始化容量和影响因子,目的是不让扩容的情况发生,代码如下:
public class HashMapMultiThread {
static Map<String,String> map = new HashMap<String,String>(120000,1.0f);
public static class AddThread implements Runnable{
int start = 0 ;
public AddThread(int start){
this.start = start;
}
@Override
public void run() {
for (int i = 0; i < 100000; i+=2) {
map.put(Integer.toString(i), Integer.toBinaryString(i));
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new HashMapMultiThread.AddThread(0));
Thread t2 = new Thread(new HashMapMultiThread.AddThread(1));
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(map.size());
}
}通过验证,不再出现死循环的问题(若觉得这样修改仍不能确定是由于代码修改导致不再死循环,可以增加线程数,再对比修改前后的运行结果)。
以上就是对此疑问的分析。
以上是关于并发下诡异的HashMap的主要内容,如果未能解决你的问题,请参考以下文章