内核源码IO多路复用EPOLL
Posted MeRcy_PM
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了内核源码IO多路复用EPOLL相关的知识,希望对你有一定的参考价值。
1. 简介:
本文将介绍内核epoll实现的原理。基于kernel 2.6.32版本。
本文只描述epoll对其他fd的监听,由于epoll本身也是一种文件系统,也可以被监听,这一部分不在这里介绍。
2. 基础数据结构:
epoll中主要数据结构有两个,一个是epoll_create创建的epoll_fd的结构体eventpoll,一个是事件源对应的epitem结构体。
epollevent的数据结构及相应解释如下:这里注意的是eventpoll中其实有两个ready list,一个是常规的rdllist,还有一个是ovflist,两个队列的区别是ovflist用于当前epoll已经在将ready list发送到用户空间时,这时候设备状态改变唤醒的时候不能直接添加在ready list中,而是需要添加在ovflist,当ready list处理完时候再从ovflist移到ready list,相当于一个备用的队列。
struct eventpoll {
/* Protect the this structure access */
spinlock_t lock;
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
struct mutex mtx;
/* Wait queue used by sys_epoll_wait() */
/* 用于epoll_wait时等待事件激活时让出本进程调度权限时候的等待队列。 */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
/* 用于epoll这个文件类型的对应的poll操作。 */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
/* 已激活的事件队列。 */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
/* 管理所有事件源,用于epoll_ctl中查找epitem。 */
struct rb_root rbr;
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transfering ready events to userspace w/out
* holding ->lock.
*/
/* 用于当epoll准备将数据返回给用户时候(ep_send_events_proc),
* 这时候设备状态改变回调(ep_poll_callback)的时候,
* 不直接添加在ready list中,而是先暂时放在ovflist,
* 当ep_send_events_proc结束的时候,重新把ovflist中的数据加到ready list中。 */
struct epitem *ovflist;
/* The user that created the eventpoll descriptor */
/* 主要用来统计当前监听多少个fd。 */
struct user_struct *user;
/* epfd对应的struct file。 */
struct file *file;
/* used to optimize loop detection check */
/* 用于把一个epfd添加到另一个epoll中监听时候检测用。 */
int visited;
struct list_head visited_list_link;
};struct epitem {
/* RB tree node used to link this structure to the eventpoll RB tree */
/* 记录在struct eventpoll中的rbr节点。 */
struct rb_node rbn;
/* List header used to link this structure to the eventpoll ready list */
/* 记录在struct eventpoll中的rdllist节点。 */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
/* 记录在struct eventpoll中的ovflist节点,ovflist用处见eventpoll。 */
struct epitem *next;
/* The file descriptor information this item refers to */
/* 文件描述符和对应的file结构体的封装
* struct epoll_filefd {
* struct file *file;
* int fd;
* };
*/
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
/* List containing poll wait queues */
/*
* struct eppoll_entry {
* /* List header used to link this structure to the "struct epitem" */
* struct list_head llink;
* /* The "base" pointer is set to the container "struct epitem" */
* struct epitem *base;
* /*
* * Wait queue item that will be linked to the target file wait
* * queue head.
* */
* wait_queue_t wait;
* /* The wait queue head that linked the "wait" wait queue item */
* wait_queue_head_t *whead;
* };
* struct eppoll_entry节点,该节点在每个事件源在相应的设备中注册(ep_ptable_queue_proc)时候创建,
* 结构体中主要封装了当前事件源对应epitem,事件源在相应设备系统中的钩子和队列
* 当设备状态改变回调时,将通过eppoll_entry中的wait找到eppoll_entry结构体再
* 找到epitem(ep_item_from_wait)
*/
struct list_head pwqlist;
/* The "container" of this item */
/* 记录epitem所在的eventpoll。 */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
/* struct file中的f_ep_links节点,好像是用作递归深度的检测,暂时没懂。 */
struct list_head fllink;
/* The structure that describe the interested events and the source fd */
/* 用户监听的事件类型。 */
struct epoll_event event;
};3. EPOLL简单的运作流程:
epoll简单流程和reactor模式有一些相似,通过epoll来对事件源(用户关注的某个设备的某个状态)进行管理,每添加一个事件源,都会在对应设备上进行注册。当事件源有用户所关注的事件触发,就在中断回调时加入到epoll的ready list中,当用户epoll_wait的时候,等待超时时间(无事件触发),交出调度权,进程唤醒后如果有事件就将事件通知给用户,简单示意图如下:当然内在还有其他更多的细节处理,下文会描述。
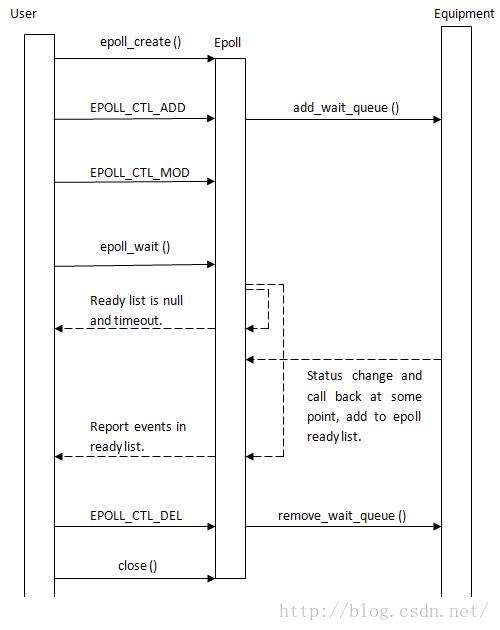
4. epoll源码:
4.1 epoll_create ():
epoll_create将创建一个属于epoll文件系统的file,同时创建一个eventpoll的结构体,作为file的private_data,这里只注意eventpoll结构体初始化的函数ep_alloc中的ovflist,当其初始化为EP_UNACTIVE_PTR时,表示不使用该队列,当该队列开放使用时,会重新初始化为0。
4.2 epoll_ctl ():
epoll_ctl执行时,对于非删除事件需要把用户空间的数据拷贝到内核空间,然后根据epfd获取对应的eventpoll结构体,根据fd获取事件源对应file结构体,对这些数据进行基本的校验。当添加事件源时,需要额外判断事件源是否是epoll,是的话需要额外检查,这个系统调用外层比较直观,这里主要讲述下三个子操作,ep_insert,ep_remove,ep_modify。
4.2.1 ep_insert:
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
struct epitem *epi;
struct ep_pqueue epq;
/* 是否达到监听数量上限。 */
if (unlikely(atomic_read(&ep->user->epoll_watches) >=
max_user_watches))
return -ENOSPC;
/* epitem初始化。 */
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
/* Item initialization follow here ... */
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
/* Initialize the poll table using the queue callback */
/* 使用栈上的ep_pqueue去向设备注册(ep_ptable_queue_proc),
* 因为f_op->poll ()的时候会马上执行,因此只需要使用栈即可。
* 这里也是唯一一处提交注册请求的地方,其他地方poll只获取状态。
*/
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
revents = tfile->f_op->poll(tfile, &epq.pt);
/*
* We have to check if something went wrong during the poll wait queue
* install process. Namely an allocation for a wait queue failed due
* high memory pressure.
*/
error = -ENOMEM;
/* 注册是否成功。 */
if (epi->nwait < 0)
goto error_unregister;
/* Add the current item to the list of active epoll hook for this file */
spin_lock(&tfile->f_lock);
list_add_tail(&epi->fllink, &tfile->f_ep_links);
spin_unlock(&tfile->f_lock);
/*
* Add the current item to the RB tree. All RB tree operations are
* protected by "mtx", and ep_insert() is called with "mtx" held.
*/
/* 加入到eventpoll结构体中进行管理。 */
ep_rbtree_insert(ep, epi);
/* now check if we've created too many backpaths */
/* 检查激活路径,貌似和添加epfd到另一个epfd有关。暂时不懂。 */
error = -EINVAL;
if (reverse_path_check())
goto error_remove_epi;
/* We have to drop the new item inside our item list to keep track of it */
spin_lock_irqsave(&ep->lock, flags);
/* If the file is already "ready" we drop it inside the ready list */
/* 如果当前事件已经激活,则添加到ready list,并唤醒epoll。 */
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
/* 监听数量统计。与函数入口的检查对应。 */
atomic_inc(&ep->user->epoll_watches);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 0;
…… exception handler ……
}/*
* This is the callback that is used to add our wait queue to the
* target file wakeup lists.
*/
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}在这里先分析下设备唤醒的回调函数ep_poll_callback,看看设备状态改变后epoll所执行的回调,分析如下:
主要注意的是当设备有用户所关注的事件被激活时,需要根据当前epoll所处的时机决定添加到ready list还是ovflist中。
/*
* This is the callback that is passed to the wait queue wakeup
* machanism. It is called by the stored file descriptors when they
* have events to report.
*/
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
/* POLLFREE调用点貌似和fork和thread有关,待研究。 */
if ((unsigned long)key & POLLFREE) {
ep_pwq_from_wait(wait)->whead = NULL;
/*
* whead = NULL above can race with ep_remove_wait_queue()
* which can do another remove_wait_queue() after us, so we
* can't use __remove_wait_queue(). whead->lock is held by
* the caller.
*/
list_del_init(&wait->task_list);
}
spin_lock_irqsave(&ep->lock, flags);
/*
* If the event mask does not contain any poll(2) event, we consider the
* descriptor to be disabled. This condition is likely the effect of the
* EPOLLONESHOT bit that disables the descriptor when an event is received,
* until the next EPOLL_CTL_MOD will be issued.
*/
/* #define EP_PRIVATE_BITS (EPOLLONESHOT | EPOLLET)
* 当只有事件触发方式而没有实际触发类型时不做任何处理。
*/
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
/*
* Check the events coming with the callback. At this stage, not
* every device reports the events in the "key" parameter of the
* callback. We need to be able to handle both cases here, hence the
* test for "key" != NULL before the event match test.
*/
/* 非用户关心的事件类型不做任何处理。 */
if (key && !((unsigned long) key & epi->event.events))
goto out_unlock;
/*
* If we are trasfering events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happens during that period of time are
* chained in ep->ovflist and requeued later on.
*/
/* 如ovflist描述,这时候epoll已经准备将数据返回给用户,
* 这时候正在更新ready list,此时不添加到ready list,
* 添加到备用的ovflist。
*/
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
}
goto out_unlock;
}
/* If this file is already in the ready list we exit soon */
/* 添加事件到ready list。 */
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
/*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
/* 激活epoll。 */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
out_unlock:
spin_unlock_irqrestore(&ep->lock, flags);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 1;
}
4.2.2 ep_modify:
ep_modify的逻辑比较简单,更新事件类型后获取一次设备状态,如果已经激活就添加到ready list,并激活epoll。
/*
* Modify the interest event mask by dropping an event if the new mask
* has a match in the current file status. Must be called with "mtx" held.
*/
static int ep_modify(struct eventpoll *ep, struct epitem *epi, struct epoll_event *event)
{
int pwake = 0;
unsigned int revents;
/*
* Set the new event interest mask before calling f_op->poll();
* otherwise we might miss an event that happens between the
* f_op->poll() call and the new event set registering.
*/
/* 更新事件。 */
epi->event.events = event->events; /* need barrier below */
epi->event.data = event->data; /* protected by mtx */
/*
* The following barrier has two effects:
*
* 1) Flush epi changes above to other CPUs. This ensures
* we do not miss events from ep_poll_callback if an
* event occurs immediately after we call f_op->poll().
* We need this because we did not take ep->lock while
* changing epi above (but ep_poll_callback does take
* ep->lock).
*
* 2) We also need to ensure we do not miss _past_ events
* when calling f_op->poll(). This barrier also
* pairs with the barrier in wq_has_sleeper (see
* comments for wq_has_sleeper).
*
* This barrier will now guarantee ep_poll_callback or f_op->poll
* (or both) will notice the readiness of an item.
*/
smp_mb();
/*
* Get current event bits. We can safely use the file* here because
* its usage count has been increased by the caller of this function.
*/
/* ep_insert已经注册过了,这里用NULL只获取当前状态。 */
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL);
/*
* If the item is "hot" and it is not registered inside the ready
* list, push it inside.
*/
/* 事件已经激活,则加入ready list,唤醒epoll。
* 这里epoll肯定不会执行epoll_wait的返回数据,因此不用ovflist。
*/
if (revents & event->events) {
spin_lock_irq(&ep->lock);
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
/* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irq(&ep->lock);
}
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return 0;
}4.2.3 ep_remove:
ep_remove就是删除该事件源对应的epitem和其对应的eppoll_entry(即对应设备的等待队列和回调。),代码比较明了,对应eppoll_entry的删除过程为ep_unregister_pollwait ----> ep_remove_wait_queue。
4.3 epoll_wait:
epoll_wait是用户调用的主要函数。系统调用入口处主要是对maxevents进行校验,并通过epfd获取file结构体进而获取eventpoll结构体。主逻辑在ep_poll函数中实现。
ep_poll代码比较简短,也很清晰,就是计算超时时间,当没有事件触发时,利用eventpoll的wait和超时时间让出当前调度权,等待超时结束或者事件到来,再根据结果进行处理。
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res, eavail;
unsigned long flags;
long jtimeout;
wait_queue_t wait;
/*
* Calculate the timeout by checking for the "infinite" value (-1)
* and the overflow condition. The passed timeout is in milliseconds,
* that why (t * HZ) / 1000.
*/
/* 计算超时时间。 */
jtimeout = (timeout < 0 || timeout >= EP_MAX_MSTIMEO) ?
MAX_SCHEDULE_TIMEOUT : (timeout * HZ + 999) / 1000;
retry:
spin_lock_irqsave(&ep->lock, flags);
res = 0;
/* ready list非空的时候会直接返回给用户。 */
if (list_empty(&ep->rdllist)) {
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
/* 使用eventpoll中的wait。 */
init_waitqueue_entry(&wait, current);
wait.flags |= WQ_FLAG_EXCLUSIVE;
__add_wait_queue(&ep->wq, &wait);
for (;;) {
/* 出让调度权,等待事件到来或者超时。 */
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
set_current_state(TASK_INTERRUPTIBLE);
if (!list_empty(&ep->rdllist) || !jtimeout)
break;
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
jtimeout = schedule_timeout(jtimeout);
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
set_current_state(TASK_RUNNING);
}
/* Is it worth to try to dig for events ? */
eavail = !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
/* 没有异常,有事件到来,非超时,尝试把事件拷贝回用户空间。 */
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && jtimeout)
goto retry;
return res;
}先看ep_scan_ready_list,这里会根据调用点传递进来的sproc去扫描ready list,在扫描前,会先把ready list移到另一个链表txlist中,再去扫描txlist,扫描前同时还开放ovflist的访问权限,扫描过程中触发的事件都会添加到ovflist中,在扫描完成时添加到ready list中,同时扫描完成后残余的激活事件也会重新接入回ready list中,如果有事件,还会重新唤醒epoll。
这里使用txlist的原因可能是对于非边缘触发的方式,需要重新添加回ready list,如果使用ready list遍历,则需要一个标志来判断是否是已询问过,并重新添加回ready list的事件,因此这里直接把list分离,遍历和ready list是两个不同的list,节约标志位的空间也节约了判断的时间。
/**
* ep_scan_ready_list - Scans the ready list in a way that makes possible for
* the scan code, to call f_op->poll(). Also allows for
* O(NumReady) performance.
*
* @ep: Pointer to the epoll private data structure.
* @sproc: Pointer to the scan callback.
* @priv: Private opaque data passed to the @sproc callback.
* @depth: The current depth of recursive f_op->poll calls.
*
* Returns: The same integer error code returned by the @sproc callback.
*/
static int ep_scan_ready_list(struct eventpoll *ep,
int (*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv,
int depth)
{
int error, pwake = 0;
unsigned long flags;
struct epitem *epi, *nepi;
LIST_HEAD(txlist);
/*
* We need to lock this because we could be hit by
* eventpoll_release_file() and epoll_ctl().
*/
mutex_lock_nested(&ep->mtx, depth);
/*
* Steal the ready list, and re-init the original one to the
* empty list. Also, set ep->ovflist to NULL so that events
* happening while looping w/out locks, are not lost. We cannot
* have the poll callback to queue directly on ep->rdllist,
* because we want the "sproc" callback to be able to do it
* in a lockless way.
*/
/* 当前即将对ready list进行处理,因此这里放开备用队列ovflist,
* 当epoll执行在这个函数期间(部分),ready list不开放,
* 新到来的事件将暂时添加到ovflist中,直到sproc处理完成。
* NULL表示可用,EP_UNACTIVE_PTR表示不可用。
*/
spin_lock_irqsave(&ep->lock, flags);
/* 从ready list中把链表移到txlist。 */
list_splice_init(&ep->rdllist, &txlist);
ep->ovflist = NULL;
spin_unlock_irqrestore(&ep->lock, flags);
/*
* Now call the callback function.
*/
error = (*sproc)(ep, &txlist, priv);
spin_lock_irqsave(&ep->lock, flags);
/*
* During the time we spent inside the "sproc" callback, some
* other events might have been queued by the poll callback.
* We re-insert them inside the main ready-list here.
*/
/* 在处理sproc的时候有事件到来,需要把ovflist中的事件添加到ready list。 */
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/*
* We need to check if the item is already in the list.
* During the "sproc" callback execution time, items are
* queued into ->ovflist but the "txlist" might already
* contain them, and the list_splice() below takes care of them.
*/
if (!ep_is_linked(&epi->rdllink))
list_add_tail(&epi->rdllink, &ep->rdllist);
}
/*
* We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after
* releasing the lock, events will be queued in the normal way inside
* ep->rdllist.
*/
/* 关闭ovflist的使用。 */
ep->ovflist = EP_UNACTIVE_PTR;
/*
* Quickly re-inject items left on "txlist".
*/
/* 把处理剩下的ready list重新接回rdllist,这时候可能ready list还有数据,如拷贝异常等。 */
list_splice(&txlist, &ep->rdllist);
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irqrestore(&ep->lock, flags);
mutex_unlock(&ep->mtx);
/* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
return error;
} 这里就是把链表中的节点取出来拷贝必要信息给用户空间,这里主要注意的是对于非边缘触发的处理方式,会重新添加回ready list,以便下次epoll_wait的时候可以正常激活对应事件。
static int ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
/* struct ep_send_events_data封装了用户数据。 */
struct ep_send_events_data *esed = priv;
int eventcnt;
unsigned int revents;
struct epitem *epi;
struct epoll_event __user *uevent;
/*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop because ep_scan_ready_list() is
* holding "mtx" during this call.
*/
for (eventcnt = 0, uevent = esed->events;
!list_empty(head) && eventcnt < esed->maxevents;) {
/* 遍历head,即scan_ready_list中创建的ready list的备份txlist。 */
epi = list_first_entry(head, struct epitem, rdllink);
list_del_init(&epi->rdllink);
/* 不是用户关注事件不会上报。 */
revents = epi->ffd.file->f_op->poll(epi->ffd.file, NULL) &
epi->event.events;
/*
* If the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, ep_scan_ready_list()
* is holding "mtx", so no operations coming from userspace
* can change the item.
*/
if (revents) {
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
/* 拷贝失败重新添加回head,head在外层会添加会ready list。 */
list_add(&epi->rdllink, head);
return eventcnt ? eventcnt : -EFAULT;
}
eventcnt++;
uevent++;
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS;
else if (!(epi->event.events & EPOLLET)) {
/*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, noone can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
/* 不是边缘触发的话,需要重新添加回ready list,
* 以便下一次epoll_wait的时候即使设备没有输入仍可唤醒。
* 如第一次epoll_wait可读1000byte,但是用户只读取了100byte,
* 第二次epoll_wait的时候设备无数据输入,但是缓冲区中仍有900byte,
* ready list仍旧非空,epoll_wait仍可马上唤醒。
* 这里直接添加会eventpoll的ready list,是防止一直添加回head
* 导致循环无法退出。
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
}
}
}
return eventcnt;
}
以上是关于内核源码IO多路复用EPOLL的主要内容,如果未能解决你的问题,请参考以下文章