前端回答从输入URL到页面展示都经历了些什么
Posted 逸丶风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端回答从输入URL到页面展示都经历了些什么相关的知识,希望对你有一定的参考价值。
浏览器和服务器涉及大量网络通信内容,此处做了弱化介绍,作为前端主要关注第四部分。
一、 网络环境保障
我们先假定我们访问的URL为www.abc.com并且地址不在局域网内;
首先我们所处的局域网的总路由应该和ISP(因特网服务提供商)连接,我们的主机要实现网络通信必须具备以下四个要素
1、本机的IP地址
2、子网掩码
3、网关的IP地址(如果我们访问的网址在局域网内则不需要该项)
4、DNS的IP地址
获取这四个要素的基本方式有两种,手动配置(静态获取)和通过DHCP获取(动态获取)
此处略过该内容,毕竟作为前端应该了解到这里够了。如果你想深究此处涉及DHCP服务(通过UDP报文段通信),想了解学习该服务具体细节建议先了解以太网中基于MAC地址的基本通信模式—广播。
再次假定我们主机已经获得.本机获取
本机的IP地址:192.168.1.100
子网掩码:255.255.255.0
网关的IP地址:192.168.1.1
DNS的IP地址:68.68.68.222
二、 获取服务器的IP地址
我们输入的URL是后经过浏览器监听到事件后,经过一系列处理,浏览器要生成一个TCP套接字(我们所说的socket),套接字用于给www.abc.com发HTTP请求,为了生成该套接字,我们的主机需要知道www.abc.com的IP地址,此时需要用到DNS服务(基于UDP报文通信),下面是DNS查询过程
主机的操作系统生成DNS查询报文,放入UDP报文中,该报文继续被放到以太网帧中(按照5层网络结构该处是链路层);前面我们已经获取到了本地DNS服务器地址68.68.68.222,但是链路层中该报文传输并不能通过IP标识链路层中的通信中介,这里就需要MAC地址(网卡地址),所以需要查询网关的MAC地址(此处就需要用到ARP协议)
同样的该处内容复杂繁多,我简化一下:
DNS查询报文------》网关路由---------》本地DNS服务器----------》返回我们要访问的IP地址
上边过程中本地DNS服务器并不一定就已经缓存了我们所查询的IP地址,所以我们的查询IP的请求可能是经过很多次查询得到的比如:www.abc.com的完整拼写应该是www.abc.com.
查询过程由 . ------com.------abc.com.-------www.abc.com.(根域名服务器--顶级域名服务器—二级域名服务器-- www.abc.com.域名服务器)
顶级域名:以.com,.net,.org,.cn等等属于国际顶级域名,根据目前的国际互联网域名体系,国际顶级域名分为两类:类别顶级域名(gTLD)和地理顶级域名(ccTLD)两种。类别顶级域名是 以"COM"、"NET"、"ORG"、"BIZ"、"INFO"等结尾的域名,均由国外公司负责管理。地理顶级域名是以国家或地区代码为结尾的域名,如"CN"代表中国,"UK"代表英国。地理顶级域名一般由各个国家或地区负责管理
二级域名:二级域名是以顶级域名为基础的地理域名,比喻中国的二级域有,.com.cn,.net.cn,.org.cn,.gd.cn等.子域名是其父域名的子域名,比喻父域名是abc.com,子域名就是www.abc.com或者*.abc.com.
一般来说,二级域名是域名的一条记录,比如alidiedie.com是一个域名,www.alidiedie.com是其中比较常用的记录,一般默认是用这个,但是类似*.alidiedie.com的域名全部称作是alidiedie.com的二级
当然查询一次之后本地域名服务器就会缓存本次查的域名IP,避免下次查询在经历这个复杂的过程,如果对域名服务器的网络结构有兴趣可以自行学习,此处不再阐述。
如果我们访问的服务器使用了代理(如常见的反向代理nginx)那么DNS查回来的是代理的IP地址(后边客户端与浏览器交互也多了一层代理通信)
三、 客户端和服务端交互(TCP和HTTP)
发送正式请求报文之前客户端(浏览器)会和服务器有三次TCP报文段交互,就是我们所称的三次握手,每次交换报文都是一次完成的请求过程,此处简化为:
客户端---SYN=1,seq=client_isn------服务端
服务端---SYN=1,seq=client_isn,ack= client_isn +1------服务端
客户端---SYN=0,seq=client_isn+1, ack= client_isn +1------服务端
1.浏览器生成HTTP请求类似这样:
GET / HTTP/1.1
Host: www.abc.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1) ……
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Cookie: ……
我们假定这个部分的长度为6000字节,它会被嵌在TCP数据包之中。
2.浏览器生成TCP套接字(socket)将HTTP数据包放入TCP数据包,并且设置接收方(www.abc.com)的端口号80(默认),发送方(本机)的端口(即之前的socket)是一个随机生成的1024-65535之间的整数,假定为55555。
TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为5020字节。
3. 然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.172.72.222(假定此IP为刚第二部查询到的服务器IP)。
然后,TCP数据包再嵌入IP数据包。IP数据包需要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.172.72.222。
IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5040字节。
4. 最后数据进入链路层,IP数据包嵌入以太网数据包。以太网数据包需要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到)。
以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5040字节。因此,IP数据包必须分割成四个包。因为每个包都有自己的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、600。
5. 服务器端响应
经过多个网关的转发,服务器172.172.72.222,收到了这四个以太网数据包。
根据IP标头的序号,服务器将四个包拼起来,取出完整的TCP数据包,然后读出里面的”HTTP请求”,接着做出”HTTP响应”,再用TCP协议发回来。浏览器接收到数据解码后变成HTML文档。
四、浏览器渲染部分:
1、浏览器渲染页面
1.1浏览器内核(渲染引擎)从浏览器网络模块获取文档内容后主流程:
a.解析HTML文档创建文档对象模型(DOM)
b.解析CSS创建CSS对象模型(CSSDOM)
c.基于DOM和CSSDOM执行JS脚本
d. 基于DOM和CSSDOM构建渲染树
e.使用渲染树布局(layout)素有元素
f.浏览器UI后端渲染(Paint)所有元素
以上过程是一个渐进过程,即渲染引擎将会尽可能早的把内容在屏幕上显示出来,不会等到所有的 HTML 都被解析完才开始建造和布局渲染树,当进程还在继续解析源源不断的来自于网络的内容的时候,一部分内容会被解析并且显示出来
此处附上webkit和Mozilla\'s Gecko 渲染引擎主要流程图
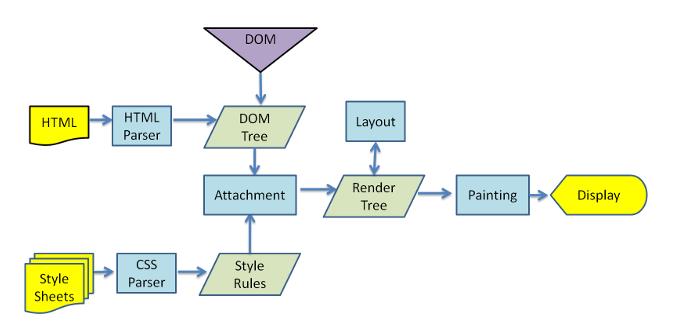
Webkit渲染引擎主要流程
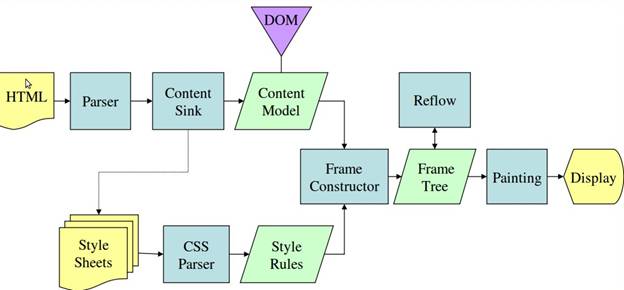
Mozilla\'s Gecko 渲染引擎主要流程
1.2解析(How browsers work)
以上主流程的涉及到的解析主要有:
a.HTML解析,
HTML语法规则并不是上下文无关的,HTML语言特点:
1. 语言宽容的特性
2. 浏览器对人们熟知的非法 HTML 有容错性的事实
3. 解析过程是可中断的。通常资源在解析过程中是不变的,但是在 HTML 里,包含“document.write”的脚本可以增加额外的子串,因此解析过程实际上改变了初始内容。
因此HTML 不能用普通的自上向下或者自下向上的普通解析器解析,浏览器做了专门的解析器来解析 HTML
b.CSS 解析器
每个css 文件都会被解析成一个 StyleSheet 对象,每个对象包含 css 规则,CSSrule 对象包含选择器和声明对象以及符合 CSS 规则的其他对象
c.JS脚本解析和执行
web 模型是同步的,开发者希望当解析器遇到<script>标签的时候脚本就被解析并且执行,脚本执行完成前暂停文档的解析,如果脚本是外部的,必须首先从网络上获取这个资源—这也是同步的,获取到这个资源之前会暂停文档的解析,这是用了多年的模型,当然也在 HTML4 和 5 中被定义了。开发者可以把脚本标记为“defer”,这样就不会暂停文档的解析,而是等文档解析完才执行。HTML5 增加了一个选择,可以把脚本标记为异步的,这样就会通过一个不同的线程来解析和执行它
取巧性解析(speculative parsing)
Webkit 和firefox都做了这个优化。当执行脚本的时候,另一个线程会解析其余的文档,寻找哪些资源需要从网络上加载并且加载它们,这种方式资源会被平行地载入,整体速度会好一些,要注意—取巧性解析器并不改变 DOM 树而是把 DOM 留给主解析器,它只解析引用的外部资源,比如外部脚本、样式表和图片。
css是不同的模型,理论上来说因为样式表并不改变 DOM 树,所以没有理由为了等待它们而去停止解析文档,然而却有一个问题,在文档解析阶段的时候,脚本执行中会请求样式信息,如果样式还没有加载或者解析,脚本会得到错误的信息,很明显这会导致很多问题。这种情况看起来边缘但实际上很普遍,当样式表在被加载和解析的时候 Firefox 会阻塞所有的脚本,而只有当脚本试图访问某些会被还未加载的样式影响的属性的时候,Webkit 才会阻塞它们
1.3构建渲染树
渲染对象和 DOM 元素是相一致的,但是并不是一对一的关系,非可见元素不会被插入到渲染树上,有个例子是“head”元素,还有 display 属性为 none 的元素不会出现在树中(visibility 为hidden 的元素会出现)
构建渲染树需要计算每个渲染对象的视觉性的属性,这是通过计算各个元素的样式属性完成的。样式来自于不同来源的样式表,内联样式或者 HTML 中视觉性的属性(就像“background”属性),后者会被转换以符合 CSS 的样式属性
Css的匹配内容较多这里不过多介绍
1.4布局(layout)和绘制(paint)
布局可以是全局的和递增的,所谓的“全局”布局发生时由于影响所有解析器的全局样式改变了如:字体大小改变,屏幕改变;布局也可以是增量的,只有重写的解析器和他的子孙被布局,当解析器是重写状态的时候,增量式布局被触发(异步的),例如,当额外的内容从网络中进来并且添加到 DOM 树之后,新的解析器被添加到渲染树上的时候。(如前面提到的整个流程是渐进的)
绘制也可以是全局式的(整个树被绘制)或者增量式的。在增量式的绘制中,解析
器中的一些以不影响整个树的方式改变。改变了的解析器使屏幕上它的区域无效,这导致操作系统把它看作是“重写区域”并且触发“绘制”方法,操作系统很巧妙的做这些,它会把几个区域合并成一个。在 Chrome 里变得更加复杂,因为解析器是在一个不同的进程而不是主进程里,Chrome 在一定程度上模仿操作系统,这种方式会监听这些事件,并且把消息委托给渲染树的根节点,这个树被遍历直到到达对应的解析器,解析器会重绘它自身(通常还有它的子节点)
以上在布局和绘制过程中涉及两个概念:reflow(回流)和 repain(重绘),DOM节点的每个元素都是以盒模型的形式存在的,这些都需要浏览器去计算其位置和大小等,这个过程称为reflow;当节点的位置大小和其他内容,字体、颜色等都确定下来之后,这个过程称为repain。页面首次加载时候必然会有回流和重绘,回流和重绘制是非常消耗性能的(回流通常比重绘严重),尤其是在移动端,所有要尽可能的减少回流和重绘制次数。
2.一些注意的点
如果你对页面的渲染和js执行顺序有疑问可以看一下内容!!
2.1 在1中介绍的浏览器渲染页面的过程是渐进的!!重要的事情说三遍。
2.2以上过程不是有单一线程来完成的,JS执行是单线程,但是浏览器不是单线程的;
为了说明这一条我们来看一下浏览器的多线程:
一般浏览器的内核中至少有三个常驻线程(不同浏览器实现不同):
GUI渲染线程 ---- 浏览器内核(渲染引擎)的主线程
JS引擎线程 ---- 处理js脚本的主线程
浏览器事件触发线程 ---- 控制交互,响应用户
另外还有一些执行完就终止的线程,如http请求线程。
我们简单举个例子:首先在1中介绍的浏览器渲染页面过程中,解析html页面构造DOM树和渲染树都是有GUI渲染主线程完成的;如果遇到的<script>标签,会先把js加载回来,交给JS引擎线程解析和执行,在js执行过程中始终是单线程执行,如果你认真看了前面的内容有提到,当js执行过程中会阻塞文档解析,这是因为js引擎线程和GUI渲染主线程是互斥的,执行js时候渲染主线程处于挂起状态,故而会阻塞页面解析,为啥要这样设计,原因之前也提到过,因为他们同时要操作DOM树(多个线程同时操作同一个对象会有冲突);
至于css加载和解析时候会阻塞js执行(chrome只有在脚本访问样式信息时候才阻塞),之前也提到过是因为js可能访问css样式信息;(鉴于js执行和渲染主线程是互斥的,也有浏览器把js执行交个渲染主线程执行的说法,这里我并不是很清楚,毕竟浏览器不是我写的)
2.3 JS引擎线程(以下我们统称js主线程)执行机制:
(1)所有同步任务都在js主线程上执行,形成一个执行栈(当然也有堆—存储js执行过程)
(2)主线程之外,还存在一个”任务队列”。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
(3)一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
主线程从”任务队列”中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)
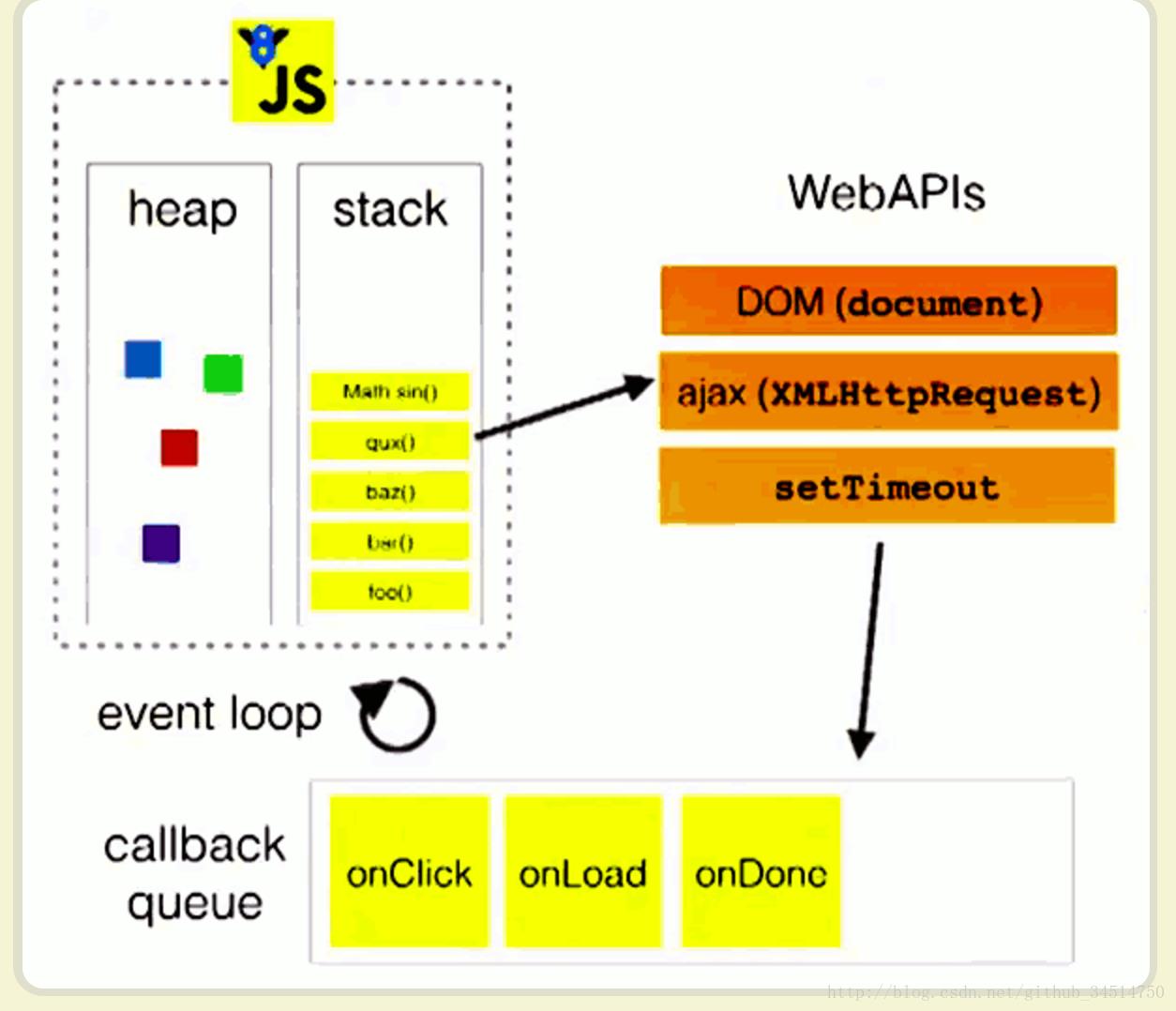
上图中,js主线程运行的时候,产生堆(heap)和栈(stack),栈中的代码调用各种外部API,它们在”任务队列”中加入各种事件(click,load,done)。只要栈中的代码执行完毕,主线程就会去读取”任务队列”,依次执行那些事件所对应的回调函数。执行栈中的代码(同步任务),总是在读取”任务队列”(异步任务)之前执行.上述过程中监听DOM事件并将事件回调添加到事件队列里是由事件触发线程完成的。
异步处理的原因:但如果单线程,任务都需要排队。排队是因为计算量大,CPU忙不过来,倒也算了,但是很多时候CPU是闲着的,因为IO设备(输入输出设备)很慢(比如Ajax操作从网络读取数据),不得不等着结果出来,再往下执行。javascript语言的设计者意识到,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
所以异步是浏览器的两个或者两个以上线程共同完成的。比如ajax异步请求和setTimeout。
现在你再看xia述代码有啥区别应该很好理解了
setTimeout(function test( ){
dosomething();
setTimeout(test,100);
},100)
setInterval(unction test( ){
dosomething();
},100)
再者为啥有时候有些代码里边写
setTimeout(function test( ){
dosomething();
},0)
这些都可以在伤处js执行过程找到答案
参阅:《How browsers work》、《计算机网络-自顶向下方法》
以上是关于前端回答从输入URL到页面展示都经历了些什么的主要内容,如果未能解决你的问题,请参考以下文章