之前学习了一些python的爬虫技术... 已经可以通过python来水blog的阅读量了 你知道的太多了, 然而你看我这个blog惨不忍睹的访问量, 有人吗? 有人吗?
今天突然又双叒叕心血来潮想写一个poj的自动提交脚本(其实已经觊觎各大oj好久了)..
本来是想选bzoj的, 但是不知道用了什么黑科技 requests会404.. 加header好像也没用... 不知道浏览器怎么做到的..
所以还是选poj吧... 不过poj的结构做得也是很清晰(就鬼咯)
因为几乎是第一次开发这种东西, 所以不免有些不成熟的地方.. 但是管它呢, 能用就行呗
所以也想分享一下自己做这东西的全过程, 来记录自己的成长, 或许可能的话还能帮一些跟我一样的萌新解决一点问题.. 那我一定会很欣慰的... 而且自己并没有系统学过python或者前端的知识, 全靠在网上吃百家饭, 如果有什么高明的见解, 欢迎提出哟~
这里采用的是requests和BeautifulSoup4, 都是直接pip安装的, 大约都是最新版吧(萌新不懂...
这两个东西的教程网上也有不少, 官方文档(的翻译)大约也是可以搜得到的...
这里因为自己也没完全学完, 所以就不详细讲了(说了能用就行嘛)
然后我们想提交肯定要登录啊对吧, 那我们就观察一下登录要做些什么...
想要查看登录需要一些什么东西, 我们需要抓包, 而最简单的方式就是采用自己的浏览器辣~
我们可以打开自己的Chorme(Firefox什么的应该也可以, 这里用的是装虚拟机里面自带的Chormium..)
我们就利用一个新注册的测试账户"fk_poj"来进行实验.
我们先输入账号和密码, 别急着点login!!, 然后按F12, 打开开发人员工具界面. 大约像这样:
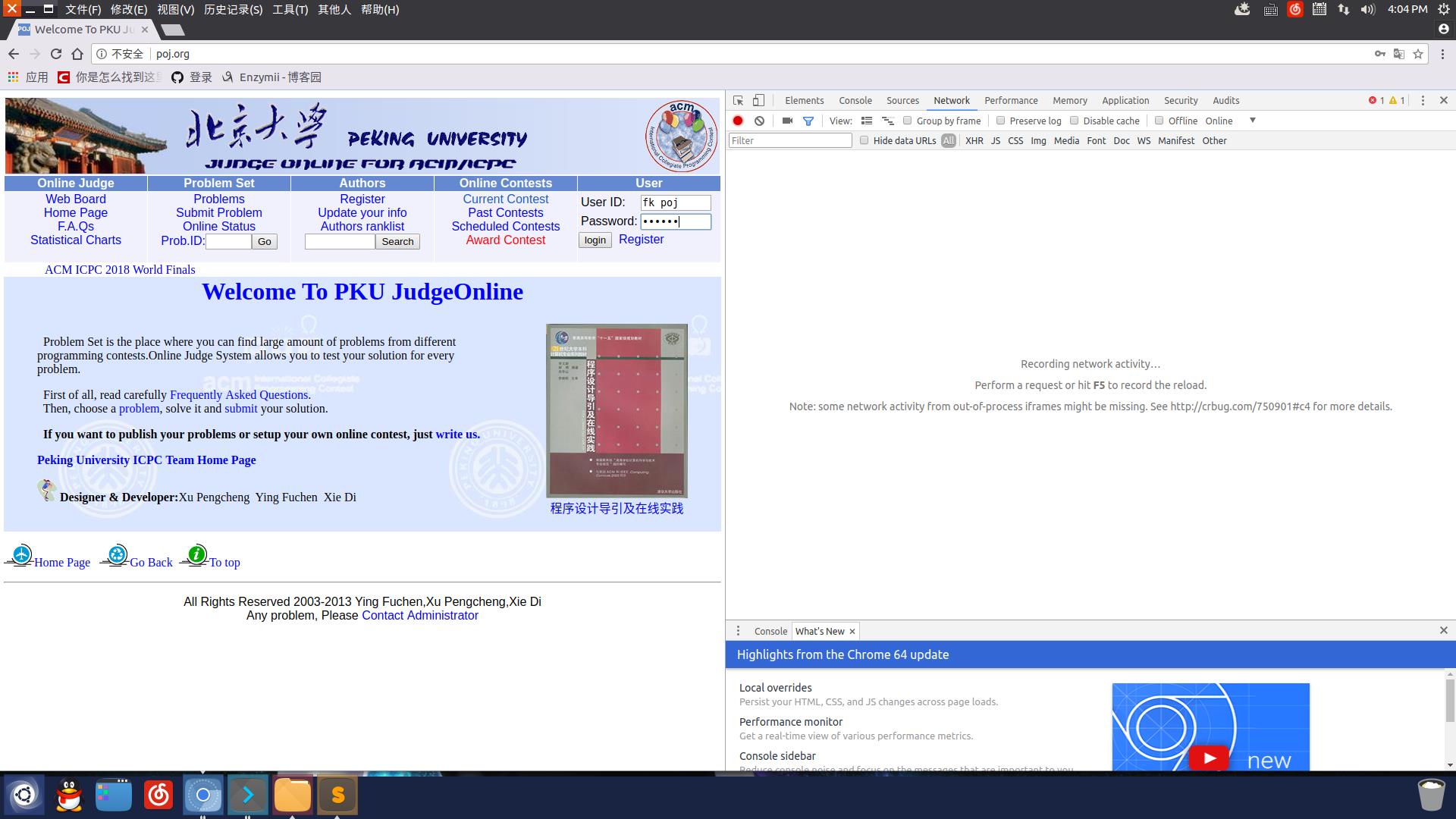
然后我们看到顶上的选项卡, 选NetWork..

现在这里应该就一句话, 没显示什么东西..
这样我们再点击login, 看到这里多了一堆东西, 有一个叫login的, 点它左边的小白块就可以查看详细信息了~

然后我们就可以看到, 登录就是一个POST请求, 而请求的内容也在下面的Form Data中显示出来了,(好像顺便暴露了密码...), 我们只需要处理成一个字典:
logindata={
\'user_id1\':\'fk_poj\',
\'password1\':\'123456\',
\'B1\':\'login\',
\'url\':\'/\'
}
然后用requests.post往Request URL(http://poj.org/login)里把这个字典发过去就ok了..
r=requests.post(\'http://poj.org/login\',data=logindata)
但是我们又不能同时登录和交题, 所以我们要保持登录...
这样我们就不能每次调用requests.post/get了, 但是requests替我们想了办法...
我们可以用requests.session..
session=requests.session()
r=session.post(\'http://poj.org/login\',data=logindata)
这样很显然session这个变量还能继续使用, 然后这个连接就会保持...
好的我们已经实现了发送登录数据, 但是我们并不知道是否登录成功了啊, 我们模拟一下登录错误的情况, 输密码多输一个7:
发现并没有什么提示啊之类的, 界面也没有切换, 抓包里面的也没有特殊的返回...
这就比较难办咯.. 但是有些功能是只有登录后才能用的!
(比如我们要做的交题就是... 留个小练习:自己动手做一下如果不登录就用POST交题(方法下面会讲), 会产生什么现象?)
这里我选择了邮件... 如果登录不成功的话会是这样的:
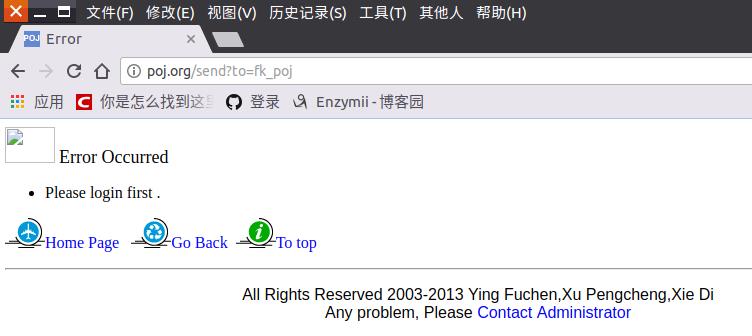
而登录成功的话是这样的:
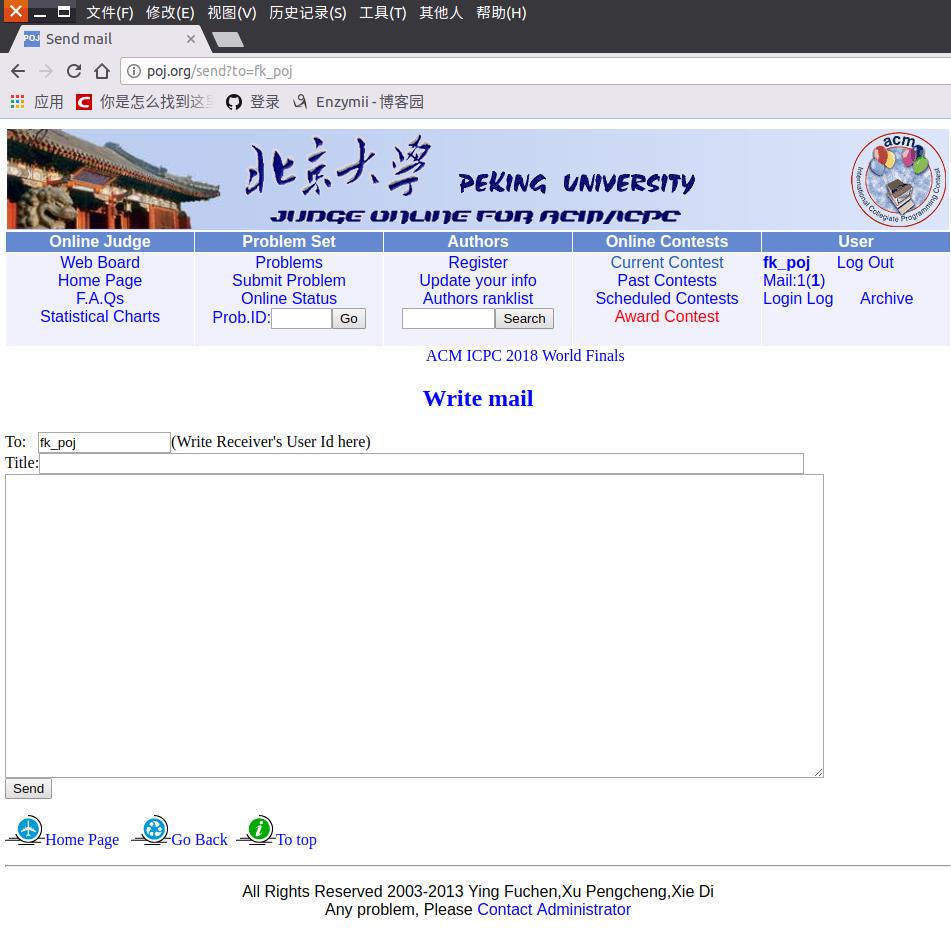
那我们就找出两个界面中html代码的不同(不同还挺大), 然后正则处理一波就行了...
(这里我用的是"Error", 判断存不存在的时候可以用开发人员工具中的Elements选项卡里Ctrl+F搜索...)
这样就登录完了, 该交题了.
由于我们只自动提交, 所以不需要读题啊获取题目信息啊之类的..
那我们就直接打开交题界面就行了...
这里选择了伟大的1000 A+B Problem
然后贴一段代码(越简单越好啊, 不要用什么"高标预流推进"之类的啦)

然后点submit, 会发现代码变成了这个熊样

而且看抓包信息的话, 这鬼东西作为了表单中的Source被POST了进去
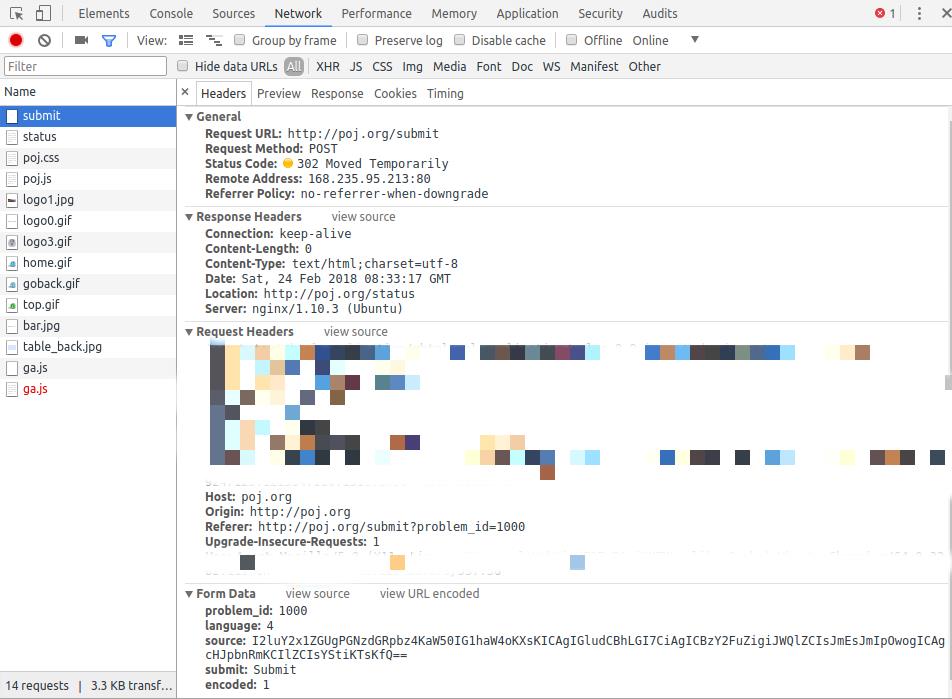
而由常识, 我们可以一眼看出这是base64的编码...
而非常巧的是, python支持base64的编码和解码, 所以我们只需要:
#import base64 # 只要import就好啦
submitdata={
\'problem_id\':1000,
# 语言的话当然是填列表项的索引, 注意从0开始
\'language\':4,
# base64的解码解出来是unicode, 所以再强转一步str
\'source\':str(base64.b64encode(code.encode(\'utf-8\'))),
\'submit\':\'Submit\',
\'encoded\':1
}
然后我们把表单POST给http://poj.org/submit就行啦~
r=session.post(\'http://poj.org/submit\',data=submitdata)
这样就做完了, 我们来看一下是否成功地提交了呢?
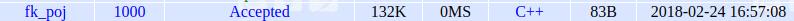
嗯 成功了, status中出现了我们的提交记录.
但是平时交题的时候基本都不是交上就算了的, 肯定还要知道自己的结果怎样, 而如果每次都手动查看的话, 显然还不如直接在oj上主动交呢.. 所以我们还要获取一下提交的结果.
为了防止其他人交题过多造成的干扰(比如交了好几页), 我们不妨利用搜索功能, 用对应的用户名、题目名和语言来找到最近的提交记录(就是刚刚提交的..) 我们还是来搜索然后抓一下包看看做了什么.

嗯, 这次是一个GET指令, 而且其实有很显然的GET的标志——选项都写在了url里..
所以我们如果是按照题目编号 用户名和语言三个关键字来搜索的话, 就应该写
status=fxxk_poj_.mainurl+\'/status?problem_id=%d&user_id=%s&result=&language=%d\'\\
%(prob_id,self.user_id,lang)
r=session.get(status)
然后我们就可以获取到网页的内容了...
然后为了找到提交的结果, 我们用BeautifulSoup来分析网页的html代码
from bs4 import BeautifulSoup # 引入BeautifulSoup
soup=BeautifulSoup(r.text)
这样这碗美丽的汤就会自动帮我们做分析了...
但是我们要找到我们要的东西还是要找到这东西的特征...
那我们就找到Elements选项卡, 然后点左上角的箭头, 再单击我们要找的"Accepted"

然后分析它和它父亲 祖父... 标签的关系,
我们发现这东西在一个table里面, 而这个table和其它的table不同的一点是, 这个table有一个class="a"的与众不同的属性.
我们找到了特征, 就可以从汤里把这个table捞出来~
# 自定义比较函数, 找到所有有class标签且class="a"的table
def stat_tab(tag):
\'\'\'
ignore tables which is no the submission table
\'\'\'
return tag.has_attr(\'class\') and tag[\'class\']==[\'a\']
# 然后用find_all, 不过返回值是个列表, 我们取第0号元素即可(因为是唯一哒)
tbs=soup.find_all(stat_tab)[0]
这样我们就提取出了我们要的状态所在的table... 我们来输出一下看看是不是我们找的...
print tbs.prettify() # 这样可以以正常的缩进来输出
然后我们再在里面精确的定位即可.
我们就可以利用类似于这篇blog讲的那样处理出我们要的信息, 这里我为了防止时间太长定位出偏差选择了根据Run ID来找, 不过翻页了并没有加以处理.. 如果有这种需要(大家还是别交太快对吧), 可以去修改代码... 具体实现这里就不细讲了, 可以去看代码.
然后我们定位出状态所在的这一条之后, 什么内存 时间 代码长度 就都是小意思啦~
这样我们已经可以实现我们需求的功能了, 不过交题的话把code写在一个字符串里其实并不多么好看, 而且也不好调试对吧... 所以我们可以采用文件读写的技术来交题..
上面的实现了的话其实代码就非常的容易啦
fcode=open(filename)
code=fcode.read()
# 然后把code交上去就行啦
最后的代码我进行了一下封装, 这样以后如果还写了其它oj的可以串在一起用..
最后的实现结果:
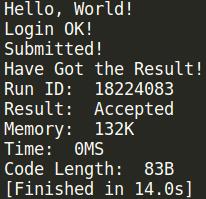
大约就是这样了. 详细的代码实现参见github..(大家要是觉得有那么一点意思, 希望大家能给个star, 大家的肯定是对一个萌新最大的鼓励_)