朴素贝叶斯趣味挑战项目
Posted 卷珠帘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯趣味挑战项目相关的知识,希望对你有一定的参考价值。
1.目的
定时爬取笑话网站,利用朴素贝叶斯分析,将不同笑话发给不同人群。
2.方案
(1)首先利用python爬虫抓取某个网站上的笑话。
(2)提供训练样本,然后用朴素贝叶斯模型来判断当前的笑话是否属于成人笑话。
(3)如果是成人笑话,把它自动发给好兄弟的qq邮箱。
(4)如果不是成人笑话,把它自动发给女朋友的qq邮箱。
(5)之后用pyinstaller将.py文件打包成exe文件,适用于所有环境。
(6)利用windows系统的任务计划程序功能早上8点定时执行此exe。因为不可能一直开着电脑,所以用云服务器。
3.实施
1.选取合适的笑话网站。---- 某某网站。
2.学习爬虫,本来只会RSS源那样子爬,但是好多网站找不到RSS地址,所以我只能学习爬虫。
(其实最后也没用到抓包工具,可以先不下载)首先需要抓包工具,下载火狐浏览器的低版本才能兼容httpfox,下载地址http://ftp.mozilla.org/pub/firefox/releases/35.0/win32/zh-CN/,这个是中文版
首先入门爬虫,https://cuiqingcai.com/1052.html,学长推荐的课程,开始入门。
这门课程上的是Python2,关于其中的函数的差别,http://blog.csdn.net/duxu24/article/details/77414298
首先以post的方式爬取一个不需要验证码的
import urllib.request import urllib.parse values = {"username":"xxxxxxxxx@qq.com","password":"xxxxx"} data = urllib.parse.urlencode(values).encode(\'utf-8\') url = "http://nian.so/" request = urllib.request.Request(url,data) response = urllib.request.urlopen(request) print(response.read())
3.记录一下cookie学习的代码。
1)利用CookieJar对象实现获取cookie的功能,并存储到变量中,打印变量。
import urllib.request import urllib.parse import urllib.error import http.cookiejar cookie = http.cookiejar.CookieJar() #声明一个CookieJar对象实例来保存cookie #使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象 handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) #构建请求 respoense = opener.open("http://www.baidu.com") for item in cookie: print(\'Name = \',item.name) print(\'Value = \',item.value)
2)保存Cookie到文件,用MozillaCookieJar模块
import urllib.request import urllib.parse import urllib.error import http.cookiejar filename = "F:\\\\cookie.txt" cookie = http.cookiejar.MozillaCookieJar(filename) #声明一个CookieJar对象实例来保存cookie #使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象 handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) #构建请求 respoense = opener.open("http://www.baidu.com") #保存cookie到文件 cookie.save(ignore_discard=True,ignore_expires=True)
ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入。
打开cookie文件。

3)从文件中获取Cookie并访问
import urllib.request import http.cookiejar filename = "F:\\\\cookie.txt" cookie = http.cookiejar.MozillaCookieJar() #声明一个CookieJar对象实例来保存cookie #使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象 cookie.load(filename,ignore_discard=True,ignore_expires=True) request = urllib.request.Request("http://www.baidu.com") handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) #构建请求 response = opener.open(request) print(response.readline())
4)利用cookie模拟网站登录
访问我校教务系统。
import urllib.request import http.cookiejar filename = "F:\\\\cookie.txt" cookie = http.cookiejar.MozillaCookieJar(filename) #声明一个CookieJar对象实例来保存cookie #使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象 handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) #构建请求 loginUrl = "http://ids.chd.edu.cn/authserver/login?service=http%3A%2F%2Fportal.chd.edu.cn%2F" values = {"username":"201524070201","password":"xxxxxx"} data = urllib.parse.urlencode(values).encode(\'utf-8\') respoense = opener.open(loginUrl,data) #保存cookie到文件 cookie.save(ignore_discard=True,ignore_expires=True) gradeUrl = "http://bkjw.chd.edu.cn/eams/teach/grade/course/person!search.action?semesterId=75&projectType=" result = opener.open(gradeUrl) print(result.read())
4.记录正则表达式学习过程中的一点小问题。
我把学习正则的python文件命名为re.py,结果说module \'re\' has no attribute \'match\',结果一百度
命名py脚本时,不要与python预留字,模块名等相同,即Python文件名不要使用Python系统库的名字,就是因为使用了Python系统库的名字,
所以在编译的时候才会产生.pyc文件。正常的Python文件在编译运行的时候是不会产生.pyc文件的!
这类问题的解决方法则是:更改python脚本的命名,不要与python系统库重合即可。回答链接:https://www.cnblogs.com/fangxx/p/xx-python02.html
5.正式学习爬取某笑话网站。
学习崔庆才大神的爬取记录,还有后人更改py2为py3的博客,进行学习。
1)目标。
(1)抓取糗事百科热门段子。
(2)过滤袋有图片的段子。
(3)根据发布时间,段子内容,点赞数,进行筛选。
2)确定URL并抓取页面代码。
import urllib.request import urllib.error #不需要用到cookie #构建请求 page = 1 url = "https://www.qiushibaike.com/hot/page/" + str(page) header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/58.0.3029.96 Safari/537.36" } try: request = urllib.request.Request(url,headers=header) response = urllib.request.urlopen(request) print(response.read().decode("utf-8")) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason)
提取到的内容如图所示。
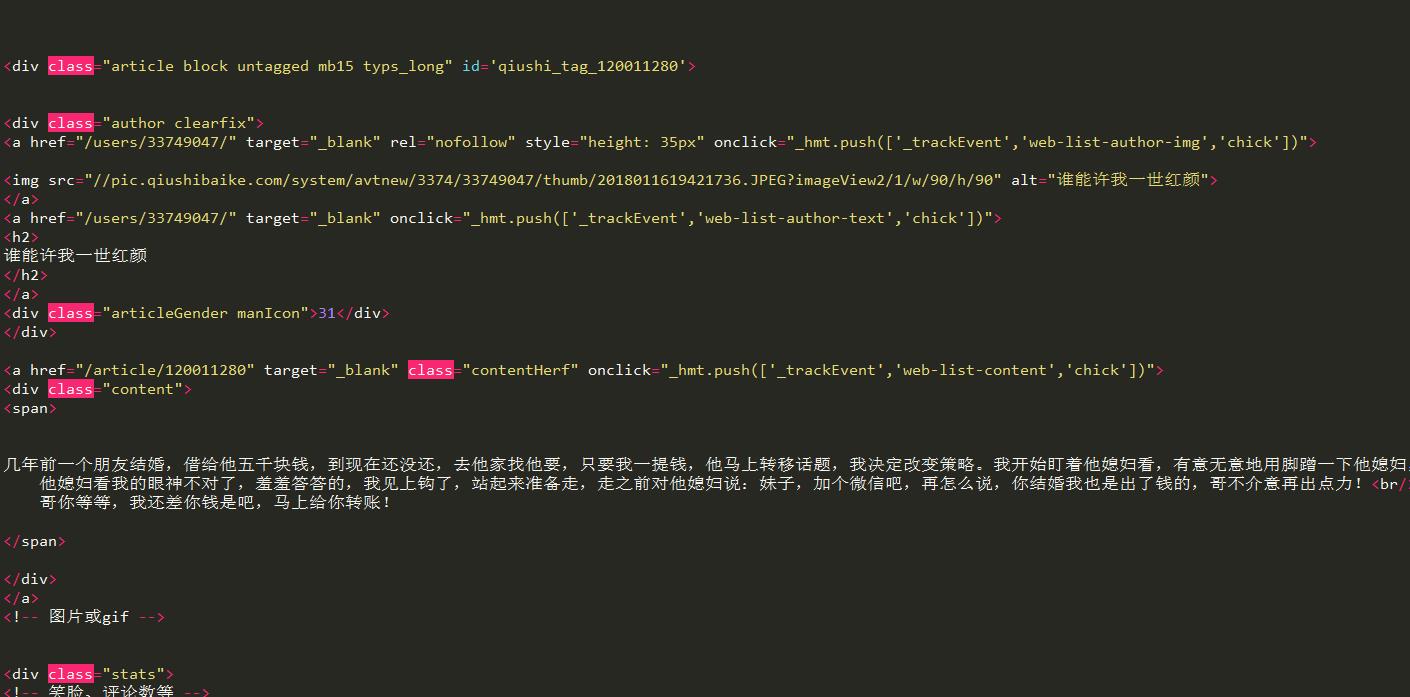
3)加入正则表达式提取第一页的所有段子。
先写正则表达式。

正则表达式如下:
#0发布人 1内容 2是图片 3是点赞数 pattern = re.compile(\'\'\'<div class="article.*?<h2>(.*?)</h2>.*?\'\'\' + \'\'\'<span>(.*?)</span>.*?\'\'\' + \'\'\'<!-- 图片或gif -->(.*?)<div class="stats">.*?\'\'\' + \'\'\'<span class="stats-vote"><i class="number">(.*?)</i>\'\'\', re.S)
正则表达式在写的时候,一定要注意空格!!! <!-- 图片或gif --> 里面的空格害我找了很长时间。
4)获取笑话。
过滤掉带图片的。
import urllib.request import urllib.error import re def init(): #不需要用到cookie #构建请求 page = 1 url = "https://www.qiushibaike.com/hot/page/" + str(page) header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36" } try: request = urllib.request.Request(url,headers=header) response = urllib.request.urlopen(request) content = response.read().decode("utf-8") #0发布人 1内容 2是图片 3是点赞数 pattern = re.compile(\'\'\'<div class="article.*?<h2>(.*?)</h2>.*?\'\'\' + \'\'\'<span>(.*?)</span>.*?\'\'\' + \'\'\'<!-- 图片或gif -->(.*?)<div class="stats">.*?\'\'\' + \'\'\'<span class="stats-vote"><i class="number">(.*?)</i>\'\'\', re.S) items = re.findall(pattern,content) #只要没图片的段子 for item in items: if not re.search("img",item[2]): result = re.sub(\'<br/>\',"\\n",item[1]) print("发布人: %s\\n内容:%s\\n点赞数:%s\\n" %(item[0].strip(),item[1].strip(),item[3].strip())) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) init() #<div class="content">
把那种查看全文的显示全。

获取段子完整代码。其中遇到的问题:http://www.cnblogs.com/littlepear/p/8456897.html
import urllib.request import urllib.error import re page = 5 url = "https://www.qiushibaike.com/hot/page/" mainurl = "https://www.qiushibaike.com" header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36" } def init(): content = getpage(index = page) #0发布人 1内容 2是图片 3是点赞数 pattern = re.compile(\'\'\'<div class="article.*?<h2>(.*?)</h2>.*?\'\'\' + \'\'\'<a href="(.*?)".*?\'\'\' + \'\'\'<span>(.*?)</span>.*?\'\'\' + \'\'\'<!-- 图片或gif -->(.*?)<div class="stats">.*?\'\'\' + \'\'\'<span class="stats-vote"><i class="number">(.*?)</i>\'\'\', re.S) items = re.finditer(pattern,content) pageItems = [] #只要没图片的段子 for item in items: zannum = int(item.group(5).strip()) if ((not re.search("img",item.group(4))) and (zannum>1000)): #print(zannum) 挑选赞大于1000的笑话 #print(item.group()) if ((not re.search("查看全文",item.group()))): result = re.sub("<br/>","\\n",item.group(3)) #print("发布人: %s\\n内容:%s\\n点赞数:%s\\n" %(item.group(1).strip(),result.strip(),item.group(5).strip())) pageItems.append([item.group(1).strip(),result.strip(),item.group(5).strip()]) else: contentForAll = getpage(contentUrl=item.group(2)) patternForAll = re.compile(\'\'\'<div class="article.*?<h2>(.*?)</h2>.*?\'\'\' + \'\'\'<div class="content">(.*?)</div>.*?\'\'\' + \'\'\'<span class="stats-vote"><i class="number">(.*?)</i>\'\'\',re.S) # patternForAll = re.compile(\'\'\'<div class="article.*?<h2>(.*?)</h2>\'\'\' # + \'\'\'.*?<div class="content">(.*?)</div>\'\'\' # + \'\'\'.*?<i class="number">(.*?)</i>\'\'\', re.S) newitems = re.findall(patternForAll,contentForAll) result = re.sub("<br/>","\\n",newitems[0][1]) #print("发布人: %s\\n内容:%s\\n点赞数:%s\\n" %(newitems[0][0].strip(),result.strip(),newitems[0][2].strip())) pageItems.append([newitems[0][0].strip(),result.strip(),newitems[0][2].strip()]) return pageItems def getpage(index=None,contentUrl=None): response = None if index: request = urllib.request.Request(url + str(index),headers=header) response = urllib.request.urlopen(request) elif contentUrl: request = urllib.request.Request(mainurl + contentUrl,headers=header) response = urllib.request.urlopen(request) return response.read().decode("utf-8") def main(): pageItems = [] pageItems = init() for jokelist in pageItems: for content in jokelist: print(content) main()
效果:

6.通过朴素贝叶斯判断是成人笑话还是普通笑话。
用了一份停用表,感觉效果还很好。
之前与之后的对比:

关于朴素贝叶斯的写法与推导,在之前的博客上:http://www.cnblogs.com/littlepear/p/8322251.html
同时关于汉字的处理,参考:https://www.cnblogs.com/marc01in/p/4775440.html
from numpy import * #加载停用词 stop_word = [] def loadword(text): word = [] fr = open(text,\'r\') lines = fr.readlines() for line in lines: word.extend(line.strip()) fr.close() return word def bagOfWordsVec(vocabSet,inputSet): returnVec = [0]*len(vocabSet) for word in inputSet: if word in vocabSet: returnVec[vocabSet.index(word)] += 1 return returnVec def textParse(bigString,stop_word): listOfWord = [] #print(stop_word) for word in bigString: if word not in stop_word: listOfWord.append(word) return listOfWord #创建一个词汇的集合 def createVocabList(dataSet): vocabSet = set([]) #创建空集合 for document in dataSet: vocabSet |= set(document) return list(vocabSet) def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) #有几行话 numWords = len(trainMatrix[0]) #每行的词汇表的词数 # print(numTrainDocs) # print(numWords) pAbusive = sum(trainCategory)/float(numTrainDocs) #p(Ci) 算是垃圾邮件的概率 p0Num = ones(numWords) p1Num = ones(numWords) # print(p0Num) #p0Denom = 2.0; p1Denom = 2.0 #书上是2.0 不知道为什么 p(x1|c1)= (n1 + 1) / (n + N) 看网上的, #为了凑成概率和是1,N应该是numWords p0Denom = 1.0*numWords; p1Denom = 1.0*numWords for i in range(numTrainDocs): if trainCategory[i] == 1: #某句话是侮辱性的话 p1Num += trainMatrix[i] #矩阵相加 #print(p1Num) p1Denom += sum(trainMatrix[i]) #print(p1Denom) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = log(p1Num/p1Denom) p0Vect = log(p0Num/p0Denom) return p0Vect,p1Vect,pAbusive def classifyNB(vecOClassify,p0Vec,p1Vec,p1Class): p1 = sum(vecOClassify*p1Vec) + log(p1Class) p0 = sum(vecOClassify*p0Vec) + log(1 - p1Class) if p1 > p0: return 1 else: return 0 #进行测试 def jokeTest(): stop_word = loadword(\'stopword1.txt\') docList = [];classList = [] for i in range(1,26): text = (\'joke/adult/%d.txt\' % i) wordList = loadword(text) wordList = textParse(wordList,stop_word) docList.append(wordList) classList.append(1) text = (\'joke/normal/%d.txt\' % i) wordList = loadword(text) wordList = textParse(wordList,stop_word) docList.append(wordList) classList.append(0) vocabList = createVocabList(docList) # 40个训练集,10个测试集 trainingSet = list(range(50));testSet = [] for i in range(10): randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) #保证随机性,不管重复 del(trainingSet[randIndex]) trainMax = []; trainClasses = [] for docIndex in trainingSet: #print(docIndex) trainMax.append(bagOfWordsVec(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V,p1V,pSpam = trainNB0(array(trainMax),array(trainClasses)) errorCount = 0 for docIndex in testSet: wordVector = bagOfWordsVec(vocabList, docList[docIndex]) if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: errorCount += 1 print("the text %s \\n the result %s the true result %s " % (docList[docIndex],classifyNB(array(wordVector), p0V, p1V, pSpam),classList[docIndex])) print("error rate: %f " % (float(errorCount)/len(testSet))) # def main(): # stop_word = [] # stop_word = loadword(\'stopword.txt\') # for item in stop_word: # print(item) #main() jokeTest()
50个样例采用交叉验证的方法,40个训练,10个测试,错误率在10%左右。

7.通过qq邮箱发送邮件
参考:https://www.cnblogs.com/xshan/p/7954317.html
import smtplib from email.mime.text import MIMEText from email.utils import formataddr my_sender=\'xxxxxxxx@qq.com\' # 发件人邮箱账号 my_pass = \'xxxxxxxxx\' # 发件人邮箱密码(当时申请smtp给的口令) my_user=\'xxxxxxxxx@qq.com\' # 收件人邮箱账号 def mail(): ret=True try: content = "I love you!" msg=MIMEText(content,\'plain\',\'utf-8\') msg[\'From\']=formataddr(["发件人昵称",my_sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号 msg[\'To\']=formataddr(["收件人昵称",my_user]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号 msg[\'Subject\']="邮件主题-测试" # 邮件的主题,也可以说是标题 server=smtplib.SMTP_SSL("smtp.qq.com", 465) # 发件人邮箱中的SMTP服务器,端口是465 server.login(my_sender, my_pass) # 括号中对应的是发件人邮箱账号、邮箱密码 server.sendmail(my_sender,[my_user,],msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件 server.quit()# 关闭连接 except Exception:# 如果 try 中的语句没有执行,则会执行下面的 ret=False ret=False return ret ret=mail() if ret: print("邮件发送成功") else: print("邮件发送失败")
8.整合
所有代码稍后给个github上的链接:
以下是正常笑话:

以下是成人笑话:
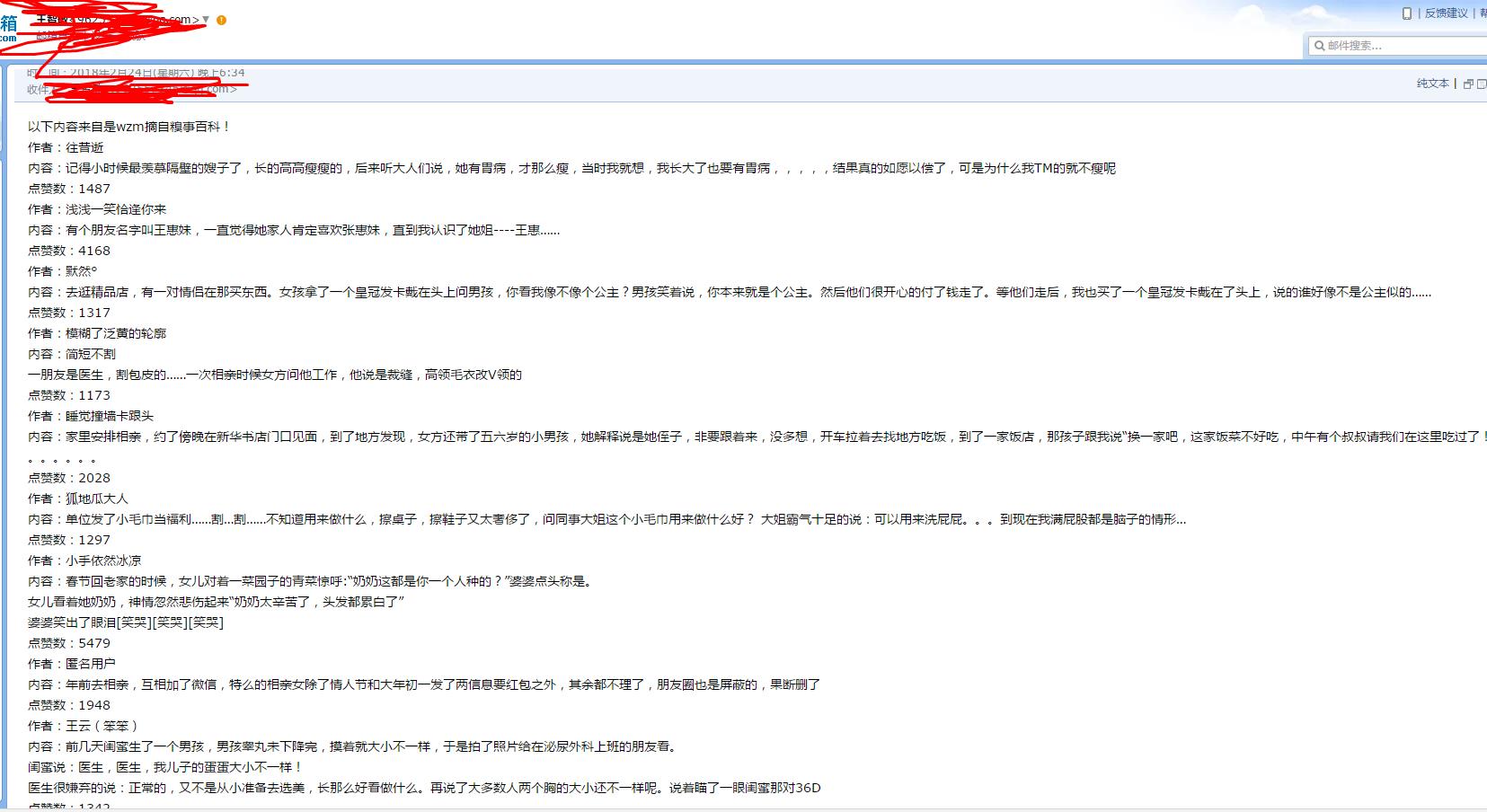
9.将.py文件打包成exe,在所有环境下执行
一直尝试用py2exe来打包,一直出问题,看网上说,可能是不支3.4以上的版本,遂换成pyinstaller,安装和使用参考下面的博客:
https://www.zhihu.com/question/54777137
https://www.zhihu.com/question/52660083
小tips:如果打包后的exe出现问题,可以用控制台程序来执行可以查看错误。

同时所用到的附件文件比如txt和图片,必须拷到所在dist下。

10.用电脑定时执行exe.
(1)windows
遇到个坑:
几个文件在同一目录下,我之前设的相对路径,直接点开文件,可以运行,如果让计算机的任务计划程序定时运行的话,一直找不到我的附件的
很纳闷,输出绝对路径查看了下,直接点开exe,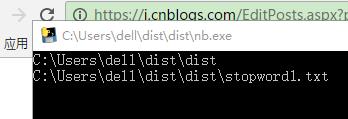
如果任务计划程序定时运行的话,路径变成,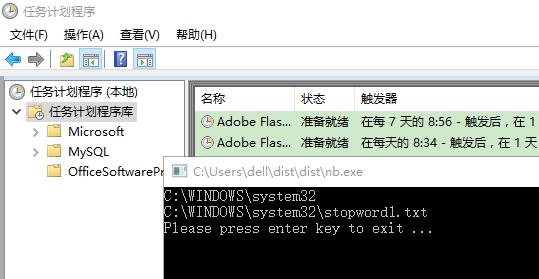
网上也有解决方案:https://www.cnblogs.com/huoqs/p/5670216.html
http://blog.csdn.net/vic0228/article/details/61914425
(2)linux
以上是关于朴素贝叶斯趣味挑战项目的主要内容,如果未能解决你的问题,请参考以下文章