摘要:
本章先回顾了前面介绍的合并排序、堆排序和快速排序的特点及运行运行时间。合并排序和堆排序在最坏情况下达到O(nlgn),而快速排序最坏情况下达到O(n^2),平均情况下达到O(nlgn),因此合并排序和堆排序是渐进最优的。这些排序在执行过程中各元素的次序基于输入元素间的比较,称这种算法为比较排序。接下来介绍了用决策树的概念及如何用决策树确定排序算法时间的下界,最后讨论三种线性时间运行的算法:计数排序、基数排序和桶排序。这些算法在执行过程中不需要比较元素来确定排序的顺序,这些算法都是稳定的。
1、决策树模型
在比较排序算法中,用比较操作来确定输入序列<a1,a2,......,a3>的元素间次序。决策树是一棵完全二叉树,比较排序可以被抽象视为决策树,表示某排序算法作用域给定输入所做的比较。在决策树中,节点表示为i:j,其中1≤i,j≤n,n是待排序元素个数,叶子节点是排序的结果。节点的左子树满足ai≤aj,右子树满足ai>aj。排序算法正确工作的必要条件是:n个元素的n!中排列中的每一种都要作为决策树的一个叶子而出现。举例说明,先有序列A<3,2,1>,对其进行有小到达进行插入排序,排序的决策树如下图所示:
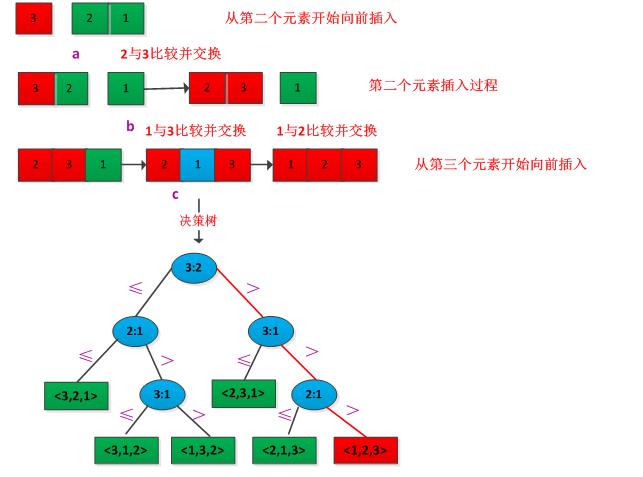
在决策树中,从跟到任意一个可达叶子节点之间最长路径的长度,表示对应的排序算法中最坏情况下的比较次数。
定理:对于一个比较排序算法在最坏情况下,都需要做Ω(nlgn)此比较。
推论:堆排序和合并排序都是渐进最优的比较排序算法。
2、计数排序
计数排序假设n个输入元素中的每一个都介于0和k之间的整数,k为n个数中最大的元素。当k=O(n)时,计数排序的运行时间为θ(n)。计数排序的基本思想是:对n个输入元素中每一个元素x,统计出小于等于x的元素个数,根据x的个数可以确定x在输出数组中的最终位置。此过程需要引入两个辅助存放空间,存放结果的B[1...n],用于确定每个元素个数的数组C[0...k]。算法的具体步骤如下:
(1)根据输入数组A中元素的值确定k的值,并初始化C[1....k]= 0;
(2)遍历输入数组A中的元素,确定每个元素的出现的次数,并将A中第i个元素出现的次数存放在C[A[i]]中,然后C[i]=C[i]+C[i-1],在C中确定A中每个元素前面有多个元素;
(3)逆序遍历数组A中的元素,在C中查找A中出现的次数,并结果数组B中确定其位置,然后将其在C中对应的次数减少1。
举个例子说明其过程,假设输入数组A=<2,5,3,0,2,3,0,3>,计数排序过程如下: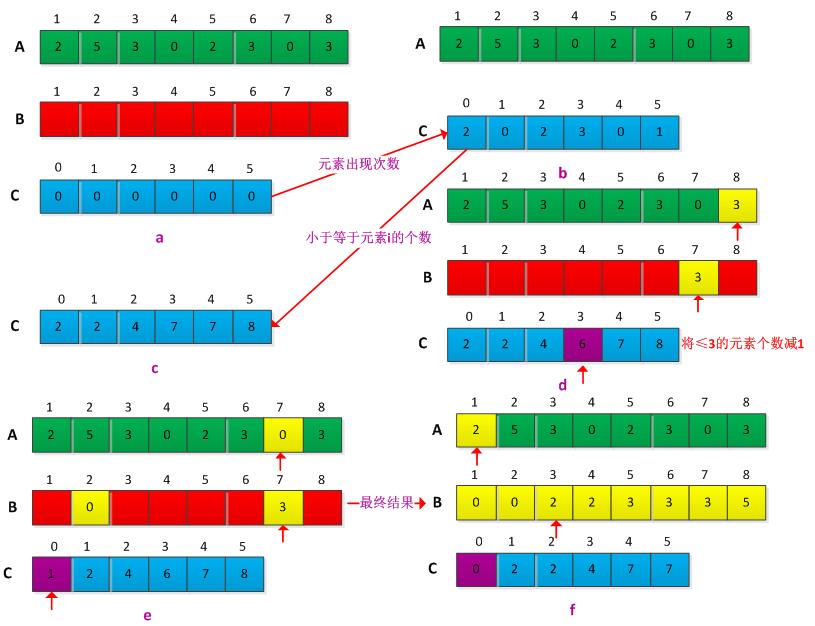
数中给出了计数排序的伪代码:
1 COUNTING_SORT(A,B,k) 2 for i=0 to k 3 do C[i] = 0 4 for j=1 to length(A) 5 do C[A[j]] = C[A[j]]+1 //C[i]中包含等于元素i的个数 6 for i=1 to k 7 do C[i] = C[i] + C[i-1] //C[i]中包含小于等于元素i的个数 8 for j=length[A] downto 1 9 do B[C[A[j]]] = A[j] 10 C[A[j]] = C[A[j]] -1
问题:在COUNTING_SORT过程中,第8行for循环为什么是 for j=length[A] downto 1,而不是 for j=1 to length[A]。
解答:虽然从改为 for j=1 to length[A]该算法仍然能够正常地工作,但是此时不能保证算法是稳定的。因为如果有两个元素相同,那么就导致排序后前面的出现在后面,后面的出现在前面,即相同值的元素在输出数组中的相对次序与它们在输入数组中的次序是不同的。而从for j=length[A] downto 1可以保证是稳定的算法。
C++代码如下:
#include<iostream>using namespace std;void CountingSort(int A[],int B[],int n,int k){ int C[k]; int i; for(i=0;i<k;i++) C[i]=0; for(i=0;i<n;i++) C[A[i]]++; for(i=1;i<k;i++) C[i]+=C[i-1]; for(i=n-1;i>=0;i--) { B[C[A[i]]-1]=A[i]; C[A[i]]--; }}int main(){ int arr[20]={1,2,2,4,5,6,3,2,5,3,4,7,8,6,8,5,0,2,8,9}; int B[20]; CountingSort(arr,B,20,10); for(auto a:B) cout<<a<<" "; cout<<endl;}从计数排序的思想及过程可以看出,当输入数组A中的数较大的时候,就不适合。因为需要开辟最大元个辅助数组,统计每个元素的出现次数。通常计数排序用在基数排序中,作为一个子程序。计数排序最重要的性质就是它是稳定的:具有相同值的元素在输出数组中的相对次序与它们在输入数组中的次序相同。
3 基数排序
基数排序排序过程无须比较关键字,而是通过“分配”和“收集”过程来实现排序,它的时间复杂度可达到线性阶:O(n)。对于十进制数来说,每一位的在[0,9]之中,d位的数,则有d列。基数排序首先按低位有效数字进行排序,然后逐次向上一位进行排序,直到最高位排序结束。举例说明基数排序过程,如下图所示:
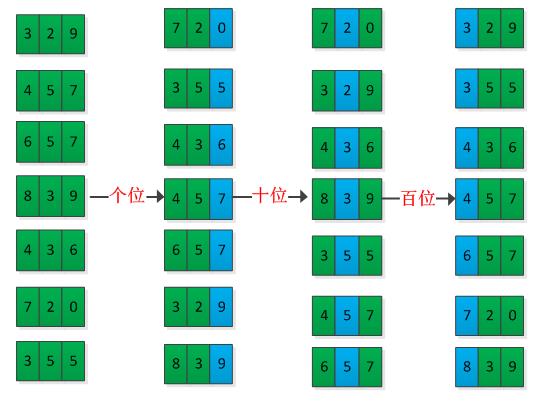
基数排序算法很直观,假设长度为n的数组A中,每个元素都有d位数字,其中第1位是最低位,第d位是最高位。书中给出了伪代码如下所示:
1 RADIX_SORT(A,d) 2 for i=1 to d 3 do usage a stable sort to sort array A on digit i
引理:给定n个d位数,每一个数位可以取k种可能值。如果所用的稳定排序需要θ(n+k)的时间,基数排序算法性能以θ(d(n+k))的时间正确对这些数进行排序。
4、桶排序
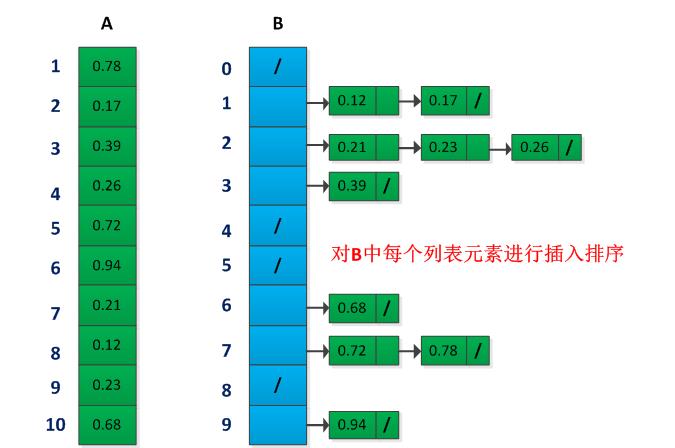
计数排序假设输入是由一个小范围内的整数构成,而桶排序则假设输入由一个随机过程产生的,该过程将元素均匀而独立地分布在区间[0,1)上。当桶排序的输入符合均匀分布时,即可以线性期望时间运行。桶排序的思想是:把区间[0,1)划分成n个相同大小的子区间,成为桶(bucket),然后将n个输入数分布到各个桶中去,对各个桶中的数进行排序,然后按照次序把各个桶中的元素列出来即可。
数中给出了桶排序的伪代码,假设输入是一个含有n个元素的数组A,且每个元素满足0≤A[i]<1,另外需要一个辅助数组B[0....n-1]来存放链表(桶)。伪代码如下所示:
1 BUCKET_SORT(A) 2 n = length(A) 3 for i= 1 to n 4 do insert A[i] into list B 5 for i=0 to n-1 6 do sort list B[i] with insertion sort 7 concatenate the list B[0]、B[1],,,B[n-1] together in order
举个来说明桶排序的过程,假设现在有A={0.78,0.17,0.39,0.26,0.72,0.94,0.21,0.12,0.23,0.68},桶排序如下所示: