01_数据库设计规范
Posted HigginCui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了01_数据库设计规范相关的知识,希望对你有一定的参考价值。
【数据库设计规范】
数据库命名规范
数据库基本设计规范
数据库索引设计规范
数据库字段设计规范
SQL开发规范
数据库操作规范
【1.数据库命名规范】
1.所有数据库对象名称必须使用小写字母并用下划线分割
mysql是区分大小写的,如果设计时用了大小写,可能会出现下面凌乱的情况
不同的数据库名 dbName dbname
不同的表名 Table table tabLe
2.所有数据库对象名称禁止使用MySql保留关键i字
3.数据库对象的命名要做到见名识义,并且最好不要超过32个字符
4.临时库、表必须以tmp为前缀并且以日期为后缀
5.备份库、表必须以bak为前缀并且以日期为后缀
6.所有存储相同数据的列名和列类型必须一致
【2.数据库基本设计规范】
1.MySql5.5使用之前Myisam(默认存储引擎)的情况,建议使用InnoDB存储引擎。
InnoDB是5.6以后默认的存储引擎,其支持事务、行级锁、更好的恢复性、高并发下性能更好。
2.数据和表的字符集建议统一使用UTF-8
统一字符集可以避免由于字符集转换产生的乱码。
注意:MySql中UTF-8字符集汉字占3个字节,ASCII码占1个字节。
3.所有表和字段都需要添加注释
使用comment从句添加表和列的备注。
从一开始就进行数据字典的维护。
4.尽量控制单表数据量的大小,建议控制在500万以内
500万并不是MySql数据的限制(修改表结构、备份、恢复都会有很大的问题)
MySql最多可以存储多少万数据呢?——这种限制取决于存储设备和文件系统。
如果感觉单表数据量过大,可以采用历史归档、分库分表等手段来控制数据量大小。
5.谨慎使用MySql分区表
分区表在物理上表现为多个文件,在逻辑上表现为一个表
谨慎使用分区键,跨分区查询效率可能更低。
建议采用物理分表的方式管理大数据。
6.尽量做到冷热数据分离,减小表的宽度。
减少磁盘IO,保证热数据的内存缓存命中率
更有效地利用缓存,避免读入无用的冷数据
将经常一起使用的列放到一个表中。
7.禁止在表中建立预留字段
预留字段的命名很难做到见名识意
预留字段无法确认存储的数据类型,所以无法选择合适的类型
对预留字段的修改,会对表进行锁定
8.禁止在数据库中存储图片、文件等二进制数据
9.禁止在线上做数据库压力测试
10.禁止从开发环境、测试环境直连生产环境数据库
【3.索引设计规范】
1.限制每张表上的索引数量,建议单张表的索引不超过5个
索引并不是越多越好,索引可以提高查询效率,也可以降低插入、更新、查询效率
禁止给表中的每一列都建立单独的索引。
2.Innodb是按照主键索引顺序来组织表的,所以每个Innodb表必须有一个主键。
不使用更新频繁的列作为主键,不使用多列主键。
不使用UUID、MD5、HASH、字符串列作为主键。
主键建议使用自增ID值。
3.常见索引列建议
SELECT、UPDATE、DELETE语句的WHERE从句中的列
包含在ORDER BY、GROUP BY、DISTINCT中的字段
多表JOIN的关联列
4.如何选择索引列的顺序
区分度最高的列放在联合索引的最左侧
尽量把字段长度小的列放在联合索引的最左侧
使用最频繁的列放到联合索引的左侧
5.避免建立冗余索引和重复索引
6.对于频繁的查询优先考虑使用覆盖索引(即包含了所有需要查询字段的索引)
避免Innodb表进行索引的二次查找
可以避免随机IO变为顺序IO加快查询效率
7.尽量避免使用外键
不建议使用外键约束,但一定要在表与表之间的关联键上建立索引。
外键可用于保证数据的参照完整性,但建议在业务端实现。
外键会影响父表和子表的写操作从而减低性能。
【4.数据库字段设计规范】
1.优先选择符合存储需要的最小的数据类型。
将字符串转化为数字类型的存储。
INET_ATON( \' 255.255.255.255 \' ) = 4294967295
INET_NTOA( 4294967295 ) = \' 255.255.255.255 \'
对于非负型的数据来说,要优先使用无符号整型来存储。
VARCHAR( N ) 中的N代表的是字符数,而不是字节数
使用UTF8存储汉字VARCHAR( 255 ) = 765个字节
2.避免使用TEXT、BLOB数据类型
如果一定要使用,建议把TEXT、BLOB列分离到单独的扩展表中
注意:TEXT或BLOB类型只能使用前缀索引
3.避免使用ENUM数据类型
修改ENUM值需要使用ALTER语句
ENUM类型的ORDER BY 操作效率低,需要额外操作
禁止使用数值作为ENUM的枚举值
4.尽可能把所有列定义为NOT NULL
索引NULL列需要额外的空间来保存,所以要占用更多的空间。
进行比较和计算时要对NULL值做特别的处理。
5.存储日期类型的数据不要使用字符串类型,要使用TIMESTAMP或DATETIME类型。
使用字符串类型存储日期的问题:无法使用日期函数进行计算和比较,且字符串存储日期会占用更多的空间。
TIMESTAMP 范围:1970-01-01 00:00:01 ~ 2038-01-19 03:14:07
TIMESTAMP 占用4字节和INT相同,但比INT可读性高。
超出TIMESTAMP取值范围的使用DATETIME类型
6.同财务相关的金额类数据,必须使用decimal类型
decimal类型为精度浮点数,在计算时不会丢失精度。
占用空间由定义的宽度决定
可用于存储比bigint更大的整数数据。
【5.数据库SQL开发规范】
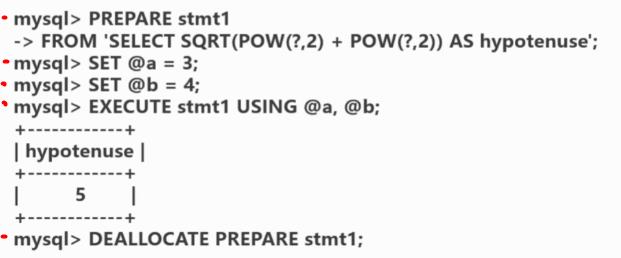
1.建议使用预编译语句进行数据库操作。
只传参数,比传递SQL语句更高效。
相同语句可以一次解析,多次使用,提高处理效率。
2.避免数据类型的隐式转换
隐式转换会导致索引失效
select * from user where id = \' 111 \' #实际id是Long类型
3,.充分利用表上已存在的索引。
避免使用 双% 的查询条件。 如:like \' %123% \'
一个SQL只能利用到复合索引中的一列进行范围查询
使用left join 或 not exists 来优化 not in 操作
4.数据库设计时,就应该对以后扩展进行考虑。
5.程序连接不同的数据库使用不同的账号,禁止跨库查询。
为数据库迁移和分库分表留出余地。
降低业务耦合度。
避免权限过大产生的安全风险。
6.禁止使用SELECT * ,应该使用 SELECT <字段列表> 进行查询。
7.禁止使用不含字段列表的 INSERT 语句

8.尽可能避免使用子查询,可以把子查询优化为join操作。
子查询的结果集无法使用索引
子查询会产生临时表操作,如果子查询数据量大会严重影响性能。
消耗过多的CPU及IO资源。
9.也要避免使用JOIN关联太多的表。(关联的表少可以接受)
每JOIN一个表会多占用一部分内存(join_buffer_size)
会产生临时表操作,影响查询效率
MySql最多允许关联61个表,建议不超过5个
10.减少数据库的交互次数
数据库更适合合理批量操作
合并多个相同的操作到一起,可以提高处理效率

11.使用 in 代替 or
in 中的数值不超过500个
in 操作可以有效地利用索引
12.禁止使用order by rand()进行随机排序
这种方式会把符合条件的数据装载到内存中进行排序。
会消耗大量的CPU、IO、内存资源。
推荐在程序中获取一个随机值,然后从数据库中获取数据。
13.WHERE从句中禁止对列进行函数转换和计算
对列进行函数转换或计算会导致无法使用索引

14.在明显不会有重复值时使用UNION ALL ,而不是UNION
UNION会把所有的数据放到临时表中后再进行去重操作。
UNION ALL 不会再对结果集进行去重操作。
15.拆分复杂的大SQL为多个小SQL
MySql一个SQL只能使用一个CPU进行计算。
SQL拆分后可以通过并行执行来提高处理效率。
【数据库操作行为规范】
1.超过100万行的批量写操作,要分批多次进行操作。
大批量的写操作可能会造成严重的主从延迟。
binlog日志为row格式时会产生大量的日志。
避免产生大事务操作。
2.对大表数据结构的修改一定要谨慎,会造成严重的锁表操作,尤其是生产环境,是不能忍受的。
对于大表使用pt-online-shcema-change修改表结构。
3.禁止为程序使用的账号赋予 super 权限。
4.对于程序连接数据库账号,遵循权限最小原则。
程序使用数据库账号只能在一个DB下使用,不准跨库。
程序使用的账号原则上是不能有drop权限的。
以上是关于01_数据库设计规范的主要内容,如果未能解决你的问题,请参考以下文章